
❗️ 계속해서 업데이트 될 예정...
잘못된 부분이 있다면 알려주세요 🙏
그래프
그래프
객체의 일부 쌍들이 연관되어 있는 객체 집합 구조.
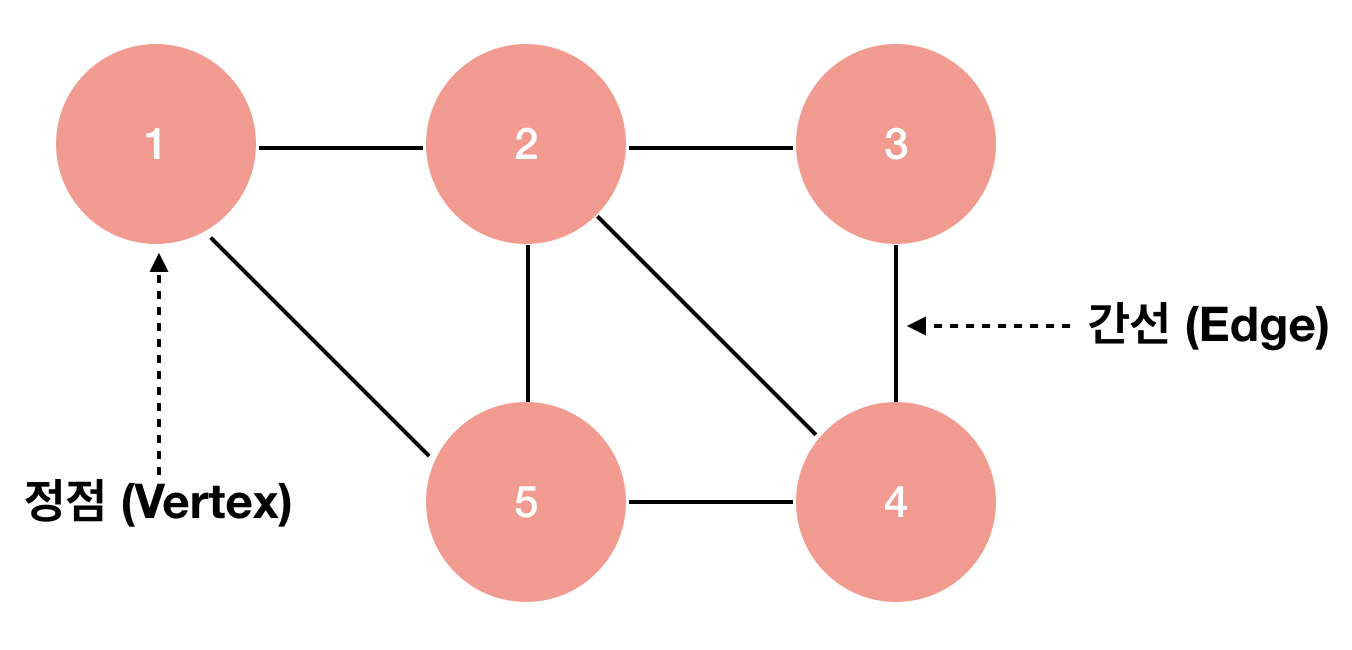
차수(Degree)
한 정점에 연결되어 있는 간선의 수.
오일러 경로
모든 간선을 한 번씩 방문하는 그래프. 즉, 한붓 그리기.
모든 정점이 짝수 개의 차수를 갖는다면 오일러의 경로이다.
해밀턴 경로
모든 정점을 한 번씩 방문하는 그래프.
- 해밀턴 순환 : 모든 정점을 한 번만 방문한 뒤 다시 출발지로 돌아오는 경로.
- 외판원 문제 : 모든 정점을 한 번만 방문한 뒤 다시 출발지로 돌아오는 경로 중 가장 짧은 경로
그래프 순회
그래프의 각 정점을 방문하는 과정
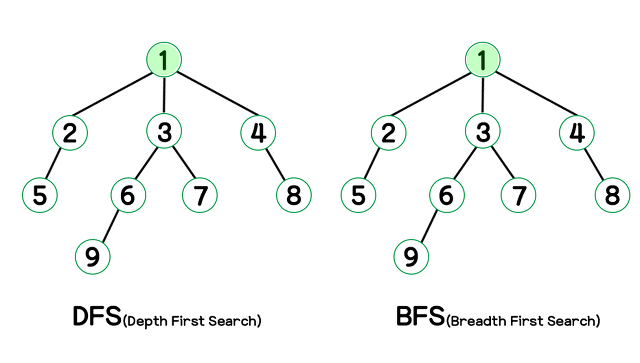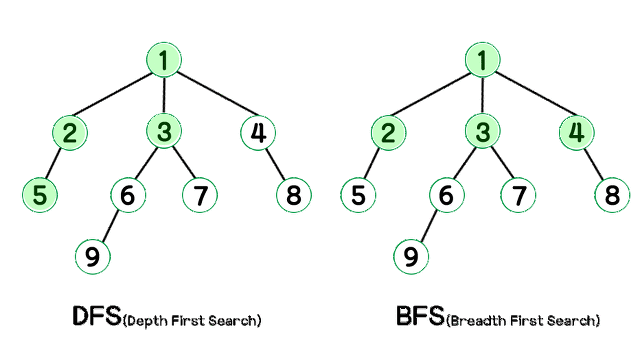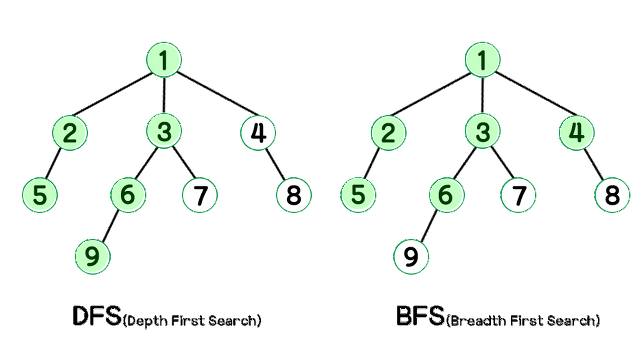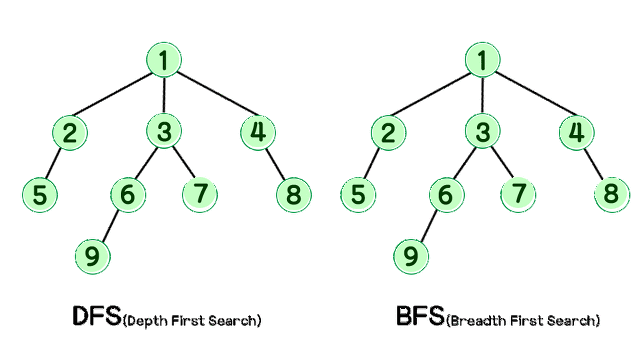
graph = { # 그래프를 인접 리스트로 표현
1: [2,3,4],
2: [5],
3: [6,7],
4: [8],
5: [],
6: [9],
7: [],
8: [],
9: []
}깊이 우선 탐색(Depth First Search, DFS)
주로 스택이나 재귀로 구현.
재귀로 구현한 DFS 는 사전식 순서로 방문.
스택으로 구현한 DFS 는 그 역순으로 방문.
순서의 차이는 있지만 두 방식 다 깊이를 우선으로 탐색함.
- 재귀로 구현 -> [1, 2, 5, 3, 6, 9, 7, 4, 8]
# 총 노드의 개수: N 시작 노드: v
# visited = [False] * (N+1)
def recursive_dfs(v, visited): # v는 정점, visited은 방문 여부
visited[v] = True # 도달한 v 정점을 방문했다고 표시
for w in graph[v]: # 인접 리스트로 표현한 그래프의 정점은 순환
if not visited[w]: # 한번도 도달한 적 없는 정점이라면 재귀 실행
discovered = recursive_dfs(w, visited)
return discovered재귀 구현은 부모 트리에서 뻗어나온 자식 트리가 또 하나의 그래프가 되어서 반복된다.
스택 구현이 좀 더 속도가 빠르지만, 간결하고 우아한 코드는 재귀 구현이다.
- 스택으로 구현 -> [1, 4, 8, 3, 7, 6, 9, 2, 5]
# 총 노드의 개수: N 시작 노드: v
# visited = [False] * (N+1)
def iterative_dfs(start_V): # start_V 는 정점
stack = [start_v] # 탐색 순서를 담을 stack
while stack:
v = stack.pop() # stack에 쌓인 정점의 끝에 값을 꺼냄
if not visited[v]: # 도달하지 않은 정점일 시 도달한 것으로 처리
visited[v] = True
for w in graph[v]: # 도달한 것으로 처리된 정점의 인접 정점을 stack에 담음
stack.append(w)
return discovered재귀 구현보다는 스택 구현이 좀 더 직관적이고 속도가 빠르다.
너비 우선 탐색(Breadth Frirst Search, BFS)
주로 큐로 구현. 그래프의 최단 경로를 구하는 문제 등에 사용.
아래는 리스트로 구현했지만 최적화를 위해 데크 자료형을 사용할 수 있음.
- 큐로 구현 -> [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 총 노드의 개수: N 시작 노드: v
# visited = [False] * (N+1)
def iterative_bfs(start_V): # start_V 는 정점
visited[start_V] = True # 도달한 정점을 담을 list
queue = collections.deque([start_V]) # 탐색 순서를 담을 queue
while queue:
v = queue.popleft() # stack에 쌓인 정점의 앞에 값을 꺼냄
for w in graph[v]:
if not visited[w]: # 도달하지 않은 정점일 시 도달한 것으로 처리
visited[w] = True
queue.append(w) # 다시 큐의 끝에 값을 넣음
return discoveredDFS VS BFS
이 영상이 두 알고리즘에 대해 가장 쉽게 설명해준다. 대신, 구현하는 부분은 JAVA로 되어있다.
다익스트라 알고리즘
항상 노드 주변의 최단 경로만을 선택한다. 대표적인 그리디 알고리즘.
단순하며, 속도가 빠르다.
보통, 최단 경로 문제를 풀 때 사용하는 알고리즘.
BFS를 이용하는 알고리즘. DFS는 한 사람이 미로에서 길을 찾는 과정과 비슷하고, BFS는 여러 사람이 갈림길마다 흩어져서 길을 찾는 과정과 비슷하다.
그래프 문제 풀이
문제 1012
✏️ 내가 작성한 코드
import sys
sys.setrecursionlimit(10000) # 최대 재귀 깊이보다 재귀의 깊어지지 않도록 제한
T = int(input())
def dfs(field, i:int, j:int):
# 밭의 범위에서 벗어나면 종료
if i < 0 or j <0 or i >= N or j >= M or field[i][j] != 1:
return
# 이미 방문한 곳은 0으로 마킹
field[i][j] = 0
# 상하좌우 탐색
dfs(field, i+1, j)
dfs(field, i-1, j)
dfs(field, i, j+1)
dfs(field, i, j-1)
for _ in range(T):
M, N, K = map(int, input().split())
field = [[0]*M for _ in range(N)]
cnt = 0
for _ in range(K): # 배추 위치 -> 그래프 그리기
x, y = map(int, input().split())
field[y][x] = 1
for i in range(N): # 전체 밭을 돌며 1일 경우 dfs 호출
for j in range(M):
if field[i][j] == 1:
dfs(field, i, j)
cnt += 1
print(cnt) 해당 문제는 완전 탐색 문제이므로, DFS나 BFS 둘다 풀이가 가능하다. 위 코드는 DFS로 푸는 방법 중 재귀함수로 구현하여 풀었다.
T = int(input())
for _ in range(T):
M, N, K = map(int, input().split())
field = [[0]*M for _ in range(N)]
for _ in range(K): # 배추 위치 -> 그래프 그리기
x, y = map(int, input().split())
field[y][x] = 1
stack = []
cnt = 0
for i in range(N):
for j in range(M):
if field[i][j] == 1:
stack.append((i,j))
cnt += 1
while stack: # 상하좌우 탐색
x, y = stack.pop()
field[x][y] = 0
if x > 0 and field[x-1][y]: stack.append((x-1, y))
if x < N-1 and field[x+1][y]: stack.append((x+1, y))
if y > 0 and field[x][y-1]: stack.append((x, y-1))
if y < M-1 and field[x][y+1]: stack.append((x, y+1))
print(cnt) DFS로 푸는 방법 중 이번에는 stack 구현하여 풀었다. 재귀가 조금 더 우아한 코드지만, 확실히 stack을 사용하면 좀 더 직관적이고 속도도 빠르다.
from collections import deque
T = int(input())
for _ in range(T):
M, N, K = map(int, input().split())
field = [[0]*M for _ in range(N)]
for _ in range(K): # 배추 위치 -> 그래프 그리기
x, y = map(int, input().split())
field[y][x] = 1
queue = deque([])
cnt = 0
for i in range(N):
for j in range(M):
if field[i][j] == 1:
queue.append((i,j))
cnt += 1
while queue: # 상하좌우 탐색
x, y = queue.pop()
field[x][y] = 0
if x > 0 and field[x-1][y]: queue.append((x-1, y))
if x < N-1 and field[x+1][y]: queue.append((x+1, y))
if y > 0 and field[x][y-1]: queue.append((x, y-1))
if y < M-1 and field[x][y+1]: queue.append((x, y+1))
print(cnt) BFS를 데크로 구현한 것이다. stack 대신 queue를 사용한 것 말고는 큰 차이가 없다.
문제 10974
✏️ 내가 작성한 코드
nums = list(range(1, int(input())+1))
result = []
prev_elements = []
def dfs(elements):
if len(elements) == 0:
result.append(prev_elements[:])
for e in elements:
next_elements = elements[:]
next_elements.remove(e)
prev_elements.append(e)
dfs(next_elements) # 자식 노드들을 새로운 그래프로 dfs
prev_elements.pop()
dfs(nums)
for i in result:
for j in i:
print(j, end = ' ')
print() 순열 문제를 dfs의 재귀로 풀어보았다. 얼핏보면 dfs로 못 풀거같지만 아래처럼 그래프로 그려보면 다음 자식 노드가 없을 때까지 계속 탐색한다. 즉, 순열이란 모든 가능한 경우를 그래프로 나열한 형태라고 볼 수 있다.
따로import하여copy사용하는 신에[:]를 사용했다.
import itertools
result = list(itertools.permutations(list(range(1, int(input())+1))))
for i in result:
for j in i:
print(j, end=' ')
print()
itertools를 사용하면 한 줄로 간단하게 순열 문제를 풀 수 있다.itertools모듈은 반복적인 연산에 최적화된 여러 기능을 제공한다. 또한 C언어로 작성되어 속도도 빠르다.
permutations는iterable한 객체를 그 객체 길이만한 크기의 순열을 모두 생성한다.
Reference
문제 1260
✏️ 내가 작성한 코드
import collections
graph = collections.defaultdict(list)
N, M, V = map(int, input().split())
for _ in range(M): # 그래프 그리기
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
def dfs(v, discovered=[]):
discovered.append(v)
for w in sorted(graph[v]):
if not w in discovered:
discovered = dfs(w, discovered)
return discovered
def bfs(v):
discovered = [v]
queue = [v]
while queue:
x = queue.pop(0)
for w in sorted(graph[x]):
if not w in discovered:
queue.append(w)
discovered.append(w)
return discovered
print(' '.join(list(map(str,dfs(V)))))
print(' '.join(list(map(str,bfs(V))))) 간선은 양방향이므로 그래프를 그릴때 양쪽을 다 그려준다.
분명 틀린거 하나 없이 완벽하게 다 풀어다고 생각했는데 자꾸 실패가 떴다. 무려 2시간 가까이 틀린 부분을 찾고 다른 코드들을 찾아가며 봤지만 아무리봐도 내 코드는 틀리지않았다.
오픈 채팅방에 물어볼까 했는데 마지막으로 한번만 더 살펴봤을 때 어디가 틀린지 알았다.
정말 말도 안되게 바보같이 출력할 때 리스트 형태 그대로 출력했다.😭
알고리즘은 잠 좀 자고 맨정신으로 풀자...
import collections
graph = collections.defaultdict(list)
N, M, V = map(int, input().split())
for _ in range(M):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
def dfs(v, discovered=[]):
stack = [v]
while stack:
x = stack.pop()
if not x in discovered:
discovered.append(x)
for i in sorted(graph[x], reverse = True):
stack.append(i)
return discovered
def bfs(v):
discovered = [v]
queue = [v]
while queue:
x = queue.pop(0)
for w in sorted(graph[x]):
if not w in discovered:
queue.append(w)
discovered.append(w)
return discovered
print(' '.join(list(map(str,dfs(V)))))
print(' '.join(list(map(str,bfs(V)))))
stack으로 풀면 조금 더 속도가 빠르다. 다만,sorted를 할 때reverse를 해줘야한다.stack은 제일 왼쪽에 있는 값부터 빠지기 때문에 하지 않을 경우 가장 큰 값부터 탐색된다.
문제 2667
✏️ 내가 작성한 코드
N = int(input())
graph = []
for _ in range(N):
graph.append(list(map(int, input())))
def dfs(i, j):
if i < 0 or i >= N or j < 0 or j >= N or graph[i][j] != 1: # 지도 범위를 넘어가면 멈춤
return
graph[i][j] = 0
global apt
apt += 1
dfs(i-1,j)
dfs(i+1,j)
dfs(i,j+1)
dfs(i,j-1)
apt_cnt = [] # 아파트 수
for i in range(N):
for j in range(N):
if graph[i][j] == 1:
# 상하좌우 살펴보기
apt = 0
dfs(i,j)
apt_cnt.append(apt)
print(len(apt_cnt))
for p in sorted(apt_cnt): # 아파트 수를 오름차순으로 출력
print(p) DFS를 재귀로 풀이.
N = int(input())
graph = []
for _ in range(N):
graph.append(list(map(int, input())))
apt_cnt = []
stack = []
for i in range(N):
for j in range(N):
if graph[i][j] == 1:
stack.append((i,j))
apts = 0
while stack: # 상하좌우 살펴보기
x, y = stack.pop()
# 지도 범위를 넘어가면 멈춤
if x < 0 or x >= N or y < 0 or y >= N or graph[x][y] != 1:
continue
graph[x][y] = 0
apts += 1
stack.append((x-1,y))
stack.append((x+1,y))
stack.append((x,y+1))
stack.append((x,y-1))
apt_cnt.append(apts)
print(len(apt_cnt))
for p in sorted(apt_cnt):
print(p)DFS를
stack으로 풀이.
이 문제는 완전 탐색으로queue를 이용하여 BFS로도 풀 수 있음.
문제 2606
✏️ 내가 작성한 코드
import collections
num_com = int(input())
num_coms = int(input())
graph = collections.defaultdict(list) # 인접 리스트
for _ in range(num_coms): # graph 그리기
com_a, com_b = map(int, input().split())
graph[com_a].append(com_b)
graph[com_b].append(com_a)
def recursive_dfs(v, discovered=[]):
discovered.append(v)
for w in graph[v]:
if not w in discovered:
recursive_dfs(w, discovered)
return len(discovered)
print(recursive_dfs(1)-1)DFS를 재귀로 풀이.
import collections
num_com = int(input())
num_coms = int(input())
graph = collections.defaultdict(list)
for _ in range(num_coms):
com_a, com_b = map(int, input().split())
graph[com_a].append(com_b)
graph[com_b].append(com_a)
def stack_dfs(v):
discovered = []
stack = [v]
while stack:
x = stack.pop()
if not x in discovered:
discovered.append(x)
for w in graph[x]:
stack.append(w)
return len(discovered)
print(stack_dfs(1)-1)
stack을 이용한 풀이.
문제 11724
✏️ 내가 작성한 코드
import collections
import sys
sys.setrecursionlimit(10000)
N, M = map(int, sys.stdin.readline().split())
graph = collections.defaultdict(list)
discovered=[]
for _ in range(M):
a, b = map(int, sys.stdin.readline().split())
graph[a].append(b)
graph[b].append(a)
def recursive_dfs(v):
discovered.append(v)
for w in graph[v]:
if not w in discovered:
recursive_dfs(w)
return discovered
cnt = 0
for i in range(1, N+1):
if not i in discovered:
recursive_dfs(i)
cnt += 1
print(cnt)
sys.setrecursionlimit(10000)로 깊이 제한을 걸어두지 않으면 에러가 뜬다.
또한input()으로 데이터를 받으면 시간 초과가 발생한다.
DFS를 재귀로 풀이.
import collections
import sys
sys.setrecursionlimit(10000)
N, M = map(int, sys.stdin.readline().split())
graph = collections.defaultdict(list)
discovered=[]
for _ in range(M):
a, b = map(int, sys.stdin.readline().split())
graph[a].append(b)
graph[b].append(a)
def stack_dfs(v):
stack = [v]
while stack:
w = stack.pop()
if not w in discovered:
discovered.append(w)
for x in graph[w]:
stack.append(x)
cnt = 0
for i in range(1, N+1):
if not i in discovered:
stack_dfs(i)
cnt += 1
print(cnt)
stack을 이용한 풀이.
문제 11724
✏️ 내가 작성한 코드
import sys
sys.setrecursionlimit(10**6)
def dfs(i,j):
if i >= h or i < 0 or j >= w or j < 0 or graph[i][j] != 1:
return
graph[i][j] = 0
# 가로, 새로, 대각선
dfs(i+1,j)
dfs(i+1,j+1)
dfs(i+1,j-1)
dfs(i,j+1)
dfs(i,j-1)
dfs(i-1,j)
dfs(i-1,j+1)
dfs(i-1,j-1)
while 1:
w, h = map(int, input().split())
if w == 0 and h == 0:
break
graph = [list(map(int, input().split())) for _ in range(h)]
cnt = 0
for i in range(h):
for j in range(w):
if graph[i][j] == 1:
dfs(i,j)
cnt += 1
print(cnt)
dfs를 이용한 풀이.
문제 7562
✏️ 내가 작성한 코드
import collections
def add(x,y,cnt):
if x < 0 or y < 0 or x >= l or y >= l:
return
queue.append((x,y,cnt+1))
def bfs(cx,cy):
cnt = 0
while queue:
x, y, cnt = queue.popleft()
if (x,y) == (ax,ay):
return cnt
if discovered[y][x] == 0:
discovered[y][x] = 1
add(x+2, y+1, cnt)
add(x+2, y-1, cnt)
add(x+1, y+2, cnt)
add(x-1, y+2, cnt)
add(x-2, y+1, cnt)
add(x-2, y-1, cnt)
add(x-1, y-2, cnt)
add(x+1, y-2, cnt)
for _ in range(int(input())):
l = int(input())
cx, cy = map(int, input().split())
ax, ay = map(int, input().split())
discovered = [[0]*l for _ in range(l)]
queue = collections.deque([(cx,cy,0)])
print(bfs(cx,cy))최단거리를 찾는 방식과 유사. BFS로 풀이.
문제 2178
✏️ 내가 작성한 코드
import collections
N,M = map(int, input().split())
graph = [list(input()) for _ in range(N)]
discovered = [[0]*M for _ in range(N)]
queue = collections.deque([(0,0,1)])
graph[0][0] = 0
def move(x,y,cnt):
if x < 0 or y < 0 or x >= M or y >= N or graph[y][x] == '0':
return
graph[y][x] = 0
queue.append((x,y,cnt+1))
def bfs(x,y):
while queue:
qx,qy,cnt = queue.popleft()
# print(qx, qy)
if qx == M-1 and qy == N-1:
return cnt
if discovered[qy][qx] == 0:
discovered[qy][qx] = 1
move(qx+1,qy,cnt)
move(qx,qy+1,cnt)
move(qx-1,qy,cnt)
move(qx,qy-1,cnt)
print(bfs(0,0))BFS를 이용한 최단거리 구하기.
discovered = []로 두고 포인트를 지나갈때마다append로 포인트를 추가하는 건 보통 시간초과가 많이 발생한다. 항상 미리 리스트를 크기에 맞춰서 만들어 놓는 습관을 들이자.
문제 7576
✏️ 내가 작성한 코드
import collections
def tomato(h,w):
if h < 0 or w < 0 or h >= N or w >= M or graph[h][w] == '-1' or graph[h][w] == '1':
return
graph[h][w] = '1'
queue.append((h,w,cnt+1))
M, N = map(int, input().split())
graph = [input().split() for _ in range(N)] # [[str]]
discovered = [[False]*M for _ in range(N)] # [[bool]]
queue = collections.deque([])
for i in range(N):
for j in range(M):
if graph[i][j] == '1':
queue.append((i,j,0))
while queue:
tomato_h, tomato_w, cnt = queue.popleft()
if not discovered[tomato_h][tomato_w]:
discovered[tomato_h][tomato_w] = True
tomato(tomato_h+1, tomato_w)
tomato(tomato_h-1, tomato_w)
tomato(tomato_h, tomato_w+1)
tomato(tomato_h, tomato_w-1)
for i in range(N) :
if '0' in graph[i]:
print(-1)
exit()
print(cnt)먼저 익은 토마토의 위치들을
queue에 담는다. 그리고BFS알고리즘을 사용하면 익은 토마토가 여러 곳이라도 제대로 동작이 된다.
discovered는 꼭 크기에 맞춰 미리 만들어 놓아야 빠르게 계산된다.
또한, 주석처럼 변수의 타입을 기입해야 안 까먹고 타입에 맞게 제대로 작성한다. 파이썬 버전에 따라typehint를 지원하지만, 코테가 지원하는 버전을 모르니 주석에 기입하는 습관을 들이면 좋을 거 같다.
import collections
def tomato(h,w):
if h < 0 or w < 0 or h >= N or w >= M or graph[h][w] == '-1' or graph[h][w] == '1':
return
graph[h][w] = '1'
queue.append((h,w,cnt+1))
global tomatos
tomatos -= 1
M, N = map(int, input().split())
graph = [input().split() for _ in range(N)] # [[str]]
discovered = [[False]*M for _ in range(N)] # [[bool]]
queue = collections.deque([])
tomatos = 0
for i in range(N):
for j in range(M):
if graph[i][j] == '1':
queue.append((i,j,0))
elif graph[i][j] == '0':
tomatos += 1
while queue:
tomato_h, tomato_w, cnt = queue.popleft()
if not discovered[tomato_h][tomato_w]:
discovered[tomato_h][tomato_w] = True
tomato(tomato_h+1, tomato_w)
tomato(tomato_h-1, tomato_w)
tomato(tomato_h, tomato_w+1)
tomato(tomato_h, tomato_w-1)
if tomatos:
print(-1)
else:
print(cnt)익지 않은 토마토가 있을 경우
-1을 출력하는 방법중 첫번째 방법보단, 두번째 방법이 더 나을 것 같다.
미리 익지 않은 토마토 개수를 카운트한 뒤, 토마토가 익을 때마다 빼주면 된다.
문제 1697
✏️ 내가 작성한 코드
import collections
N, K = map(int, input().split())
def front(x):
if x < 0 or x > 100000:
return
queue.append((x, cnt+1))
def back(x):
if x < 0 or x > 100000:
return
queue.append((x, cnt+1))
def tele(x):
if x < 0 or x > 100000:
return
queue.append((x, cnt+1))
def bfs(x):
# print(x)
front(x+1)
back(x-1)
tele(2*x)
queue = collections.deque([(N,0)])
discovered = [False]*100001
while queue:
q, cnt = queue.popleft()
if q == K:
print(cnt)
break
if not discovered[q]:
discovered[q] = True
bfs(q)💡 흥미로운 코드
def c(n,k):
if n>=k:
return n-k
elif k == 1:
return 1
elif k%2:
return 1+min(c(n,k-1),c(n,k+1))
else:
return min(k-n, 1+c(n,k//2))
n, k = map(int,input().split())
print(c(n,k))굳이
BFS로 풀지 않고 재귀를 이용해서 푸는게 코드가 더 간결하다.
문제 14502
✏️ 내가 작성한 코드
import itertools
import collections
import copy
N, M = map(int, input().split())
map = [input().split() for _ in range(N)]
tmp = []
virus = []
result = 0
for i in range(N):
for j in range(M):
# 벽을 칠 수 있는 공간 찾기
if map[i][j] == '0':
tmp.append((i,j))
# 바이러스 위치 저장
elif map[i][j] == '2':
virus.append((i,j))
# 3개의 벽 조합 모두 구하기
walls = list(itertools.combinations(tmp,3))
def bfs(x, y):
if x < 0 or y < 0 or x >= N or y >= M or map_tmp[x][y] != '0':
return
queue.append((x,y))
map_tmp[x][y] = '2'
global safe
safe -= 1
# 바이러스 퍼트리기
for wall in walls:
map_tmp = copy.deepcopy(map)
for h,w in wall:
map_tmp[h][w] = '1' # 선택된 3개의 포인트에 벽치기
# 안전한 곳의 수
safe = len(tmp)
queue = collections.deque(virus)
discovered = [[False]*M for _ in range(N)]
while queue:
vh, vw = queue.popleft()
if not discovered[vh][vw]:
discovered[vh][vw] = True
bfs(vh+1, vw)
bfs(vh-1, vw)
bfs(vh, vw+1)
bfs(vh, vw-1)
result = max(result, safe)
print(result-3)처음에 잘못 생각해서
permutations를 사용했다.😂 그래서 계속 시간초과가 뜨는 삽질을 했다...
그리고[:]이deepcopy인줄 알고 있었는데 얕은 복사였다. 이걸 몰라서 시간이 많이 걸렸다. 관련 내용은 여기에 정리해놨다.
문제 2468
✏️ 내가 작성한 코드
import sys
sys.setrecursionlimit(100000)
def dfs(i,j):
if i < 0 or j < 0 or i >= N or j >= N or graph[i][j] == 0:
return
if not discovered[i][j]:
discovered[i][j] = True
dfs(i+1,j)
dfs(i-1,j)
dfs(i,j+1)
dfs(i,j-1)
N = int(input())
graph = [list(map(int, input().split())) for _ in range(N)]
max_value = max(max(i) for i in graph)
result = 0
for rain in range(max_value):
cnt = 0
discovered = [[False]*N for _ in range(N)]
# 비가 내린 양만큼 물에 잠긴 그래프 그리기
for i in range(N):
for j in range(N):
if graph[i][j] <= rain:
graph[i][j] = 0
# 물에 잠긴 그래프에서 안전 위치 구하기
for p in range(N):
for q in range(N):
if graph[p][q] != 0 and not discovered[p][q]:
dfs(p,q)
cnt += 1
result = max(result, cnt)
print(result) 