pandas 강의를 듣고 정리
Pandas 팬더스 데이터분석 기초 실습
판다스, 데이터프레임, 시리즈
- 파이썬의 라이브러리
- 2D array 이다
- 엑셀이 있는데 굳이 팬더스를 배우는 이유?
- 파이썬으로 다뤄야 프로그램을 만들 수 있다.
- 팬더스는 Numpy를 사용한다. Numpy는 연산에 강력한 퍼포먼스(속도)를 보여준다. 엑셀보다 훨씬 빠름!
- Pandas의 각 컬럼은 Series 라고 부른다
→ series 로 이루어진 것이 데이터 프레임이다. - series 를 만드는 방법은 파이썬의 List를 사용해서 만든다.
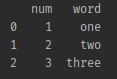
✔ 기초적인 판다스! 데이터 프레임을 만들어보기
import pandas as pd
s1 = pd.core.series.Series([1, 2, 3])
s2 = pd.core.series.Series(['one', 'two', 'three'])
s3 = pd.DataFrame(data=dict(num=s1, word=s2))
print(s3)- 결과
파일에서 데이터 불러오기
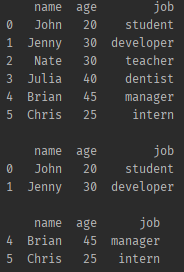
✔ csv에서 불러오기, head / tail 명령어
csv는 쉼표로 구분되어있기 때문에 별도의 추가 파라미터 없이 불러올 수 있다.
import pandas as pd
df = pd.read_csv('data/friend_list.csv')
print(df)
print('')
print(df.head(2)) # 앞에서부터 불러오기, 파라미터 없으면 모든데이터
print('')
print(df.tail(2)) # 뒤에서부터 불러오기, 파라미터 없으면 모든데이터- 결과
✔ csv에서 불러오기, Tab 으로 구분된 파일의 경우?
pandas에게 delimiter(구분문자) 파라미터를 추가해서, 탭으로 구분됨을 알려주어야 한다.
import pandas as pd
df = pd.read_csv('data/friend_list_tab.txt', delimiter='\t')
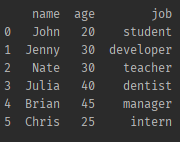
print(df)✔ 헤더(컬럼명)가 없는 데이터 불러오는 경우
pandas에게 header no 파라미터를 추가해서, 없음을 알려주어야 한다.
import pandas as pd
df = pd.read_csv('data/friend_list_no_head.csv', header= None)
print(df) # 이 경우엔 컬럼 네임이 없음
df.columns = ['name', 'age', 'job'] # 컬럼명을 지정해줌
print(df)- 결과
데이터 프레임 생성하기 (딕셔너리, 리스트)
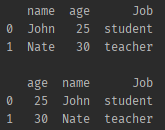
✔ 딕셔너리 형태의 데이터를 데이터 프레임으로 생성하자!
이 경우, 딕셔너리는 컬럼 순서가 보장되지 않으므로 순서가 필요한 경우엔 별도로 컬럼 순서를 명시해주어야한다
from_dict() 매서드
import pandas as pd
friend_dict_list = [
{'name' : 'John', 'age' : 25, 'Job' : 'student'},
{'name' : 'Nate', 'age' : 30, 'Job' : 'teacher'}
]
df = pd.DataFrame(friend_dict_list)
print(df.head(),'\n')
df = df[['age', 'name', 'Job']]
print(df.head())- 결과
✔ 위의 경우가 번거로울 경우엔 한번에 하기위해서
collections의 ordereddict 를 사용해야한다. (키의 순서를 보장)
import pandas as pd
from collections import OrderedDict
friend_ordered_dict = OrderedDict(
[
('name', ['John', 'Nate']),
('age', [25, 30]),
('job', ['student', 'teacher'])
]
)
df = pd.DataFrame.from_dict(friend_ordered_dict)
print(df.head(),'\n')- 결과
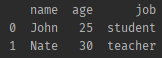
✔ 리스트 형태의 데이터를 데이터 프레임으로 생성하자!
from_records() 매서드
import pandas as pd
# 데이터가 담길 리스트를 생성한다.
friend_list = [
['John', 25, 'student'],
['Nate', 30, 'teacher']
]
# 컬럼명 정보가 담길 리스트를 생성한다.
column_name = ['name', 'age', 'job']
# friend 데이터 정보와 컬럼명(head) 정보가 마련됐으니
# 두 정보를 이용해서 데이터 프레임을 만들자
df = pd.DataFrame.from_records(friend_list, columns = column_name)
print(df,'\n')- 결과
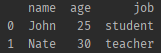
import pandas as pd
# 데이터가 담긴 리스트
friend_list = [
['name', ['John', 'Nate']],
['age', [25, 30]],
['job', ['student', 'teacher']]
]
# friend 데이터 정보와 컬럼명(head) 정보가 마련됐으니
# 두 정보를 이용해서 데이터 프레임을 만들자
df = pd.DataFrame.from_dict(dict(friend_list))
print(df,'\n')데이터 프레임 필터링
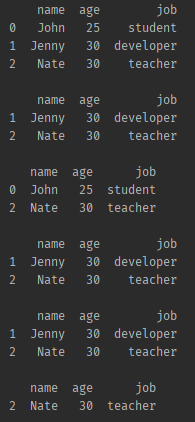
✔ index, 컬럼, 쿼리 형태로 필터링
by column condition
import pandas as pd
friend_list = [
['name', ['John', 'Jenny', 'Nate']],
['age', [25, 30, 30]],
['job', ['student', 'developer', 'teacher']]
]
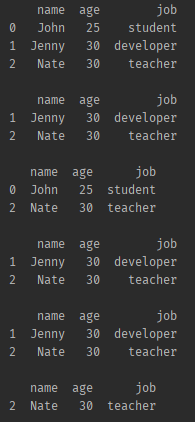
df = pd.DataFrame.from_dict(dict(friend_list))
print(df,'\n')
#### index 로 필터링 하기 > 리스트 슬라이싱
print(df[1:3],'\n')
### loc 로 원하는 index 만 리스트에 넣어서 가져온다.
print(df.loc[{0,2}],'\n')
### by column condition > DB쿼리처럼 컬럼 데이터 조건에 따라 가져온다
# 특정 컬럼을 지정해서 가져옴
print(df[df.age > 25],'\n')
# 쿼리 형태로 가져옴
print(df.query('age>25'),'\n')
# 쿼리 형태이고 조건이 두가지
print(df[ (df.age > 25) & (df.name == 'Nate')])- 결과
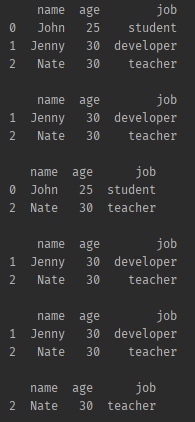
✔ iloc 함수
import pandas as pd
friend_list = [
['John', 20, 'student'],
['Jenny', 30, 'developer'],
['Nate', 30, 'teacher']
]
df = pd.DataFrame.from_records(friend_list)
print(df, '\n')
# 특정 한가지 값을 가져옴
print(df.iloc[0, 2])
# 리스트 슬라이싱 활용해서 범위로 가져옴
print(df.iloc[:, 0:2])- 결과
by column name
import pandas as pd
friend_list = [
['name', ['John', 'Jenny', 'Nate']],
['age', [25, 30, 30]],
['job', ['student', 'developer', 'teacher']]
]
df = pd.DataFrame.from_dict(dict(friend_list))
print(df,'\n')
#### index 로 필터링 하기 > 리스트 슬라이싱
print(df[1:3],'\n')
### loc 로 원하는 index 만 리스트에 넣어서 가져온다.
print(df.loc[{0,2}],'\n')
### by column condition > DB쿼리처럼 컬럼 데이터 조건에 따라 가져온다
# 특정 컬럼을 지정해서 가져옴
print(df[df.age > 25],'\n')
# 쿼리 형태로 가져옴
print(df.query('age>25'),'\n')
# 쿼리 형태이고 조건이 두가지
print(df[ (df.age > 25) & (df.name == 'Nate')])- 결과

삶을 스스로 통제하고 있다는 느낌을 받을 때 더 행복하고 성공한다.🍃