pandas 강의를 듣고 정리
Pandas 팬더스 데이터분석 기초 실습
데이터 프레임 행, 열 삭제
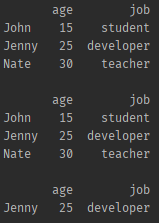
index 이름으로 드랍하기
import pandas as pd
friends = [{'age': 15, 'job': 'student'},
{'age': 25, 'job': 'developer'},
{'age': 30, 'job': 'teacher'}
]
# friends 라는 정보를 가지고, df라는 데이터 프레임을 생성한다
df = pd.DataFrame(friends, index=['John', 'Jenny', 'Nate'], columns=['age', 'job'])
print(df, '\n')
# john과 nate 를 제거, 그러나 원래 데이터 베이스에는 적용되지 않음.
df.drop(['John', 'Nate'])
print(df, '\n')
# john과 nate 를 제거, Inplace 인자를 추가해서 원래 데이터 베이스에도 적용.
df.drop(['John', 'Nate'], inplace=True)
print(df, '\n')- 결과
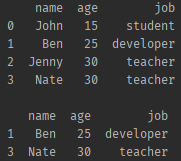
index 넘버로 드랍하기
import pandas as pd
friends = [{'name': 'John', 'age': 15, 'job': 'student'},
{'name': 'Ben', 'age': 25, 'job': 'developer'},
{'name': 'Jenny', 'age': 30, 'job': 'teacher'},
{'name': 'Nate', 'age': 30, 'job': 'teacher'}
]
# friends 라는 정보를 가지고, df라는 데이터 프레임을 생성한다
# 인덱스가 그냥 숫자인 데이터 프레임임!
df = pd.DataFrame(friends, columns=['name', 'age', 'job'])
print(df, '\n')
# 인덱스가0, 2 인 데이터
# 배열을 한번 더 넣어주는 이유는 여러개 삭제할 것이기 때문
print(df.drop(df.index[[0,2]]))- 결과
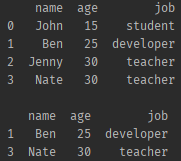
컬럼의 벨류 조건에 따라 드랍하기
import pandas as pd
friends = [{'name': 'John', 'age': 15, 'job': 'student'},
{'name': 'Ben', 'age': 25, 'job': 'developer'},
{'name': 'Jenny', 'age': 30, 'job': 'teacher'},
{'name': 'Nate', 'age': 30, 'job': 'teacher'}
]
# friends 라는 정보를 가지고, df라는 데이터 프레임을 생성한다
# 인덱스가 그냥 숫자인 데이터 프레임임!
df = pd.DataFrame(friends, columns=['name', 'age', 'job'])
print(df, '\n')
# 인덱스가0, 2 인 데이터
# 배열을 한번 더 넣어주는 이유는 여러개 삭제할 것이기 때문
print(df.drop(df.index[[0,2]]))- 결과
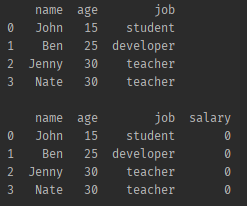
데이터 프레임 행, 열 생성, 수정
열 추가하기
import pandas as pd
friends = [{'name': 'John', 'age': 15, 'job': 'student'},
{'name': 'Ben', 'age': 25, 'job': 'developer'},
{'name': 'Jenny', 'age': 30, 'job': 'teacher'},
{'name': 'Nate', 'age': 30, 'job': 'teacher'}
]
# friends 라는 정보를 가지고, df라는 데이터 프레임을 생성한다
df = pd.DataFrame(friends, columns=['name', 'age', 'job'])
print(df.head(), '\n')
# salary 열을 추가한다, 간단히 0이라는 데이터를 넣을수도 있고
df['salary'] = 0
# 배열을 넣을수도 있다
# df['salary'] = [0, 1, 2, 3]
print(df.head(), '\n')- 결과
조건에 따라 열 수정하기 (numpy 사용!!)
import pandas as pd
import numpy as np
friends = [{'name': 'John', 'age': 15, 'job': 'student'},
{'name': 'Ben', 'age': 25, 'job': 'developer'},
{'name': 'Jenny', 'age': 30, 'job': 'teacher'},
{'name': 'Nate', 'age': 30, 'job': 'teacher'}
]
# friends 라는 정보를 가지고, df라는 데이터 프레임을 생성한다
df = pd.DataFrame(friends, columns=['name', 'age', 'job'])
print(df.head(), '\n')
df['salary'] = 0
print(df.head(), '\n')
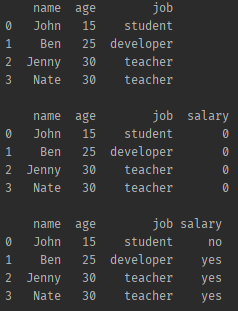
# df의 salary 라는 열을 수정할거야 = 넘파이를통해서.어디에?(df의 [job을 봐바] != 학생이아니면, 연봉이있구, 학생이면 연봉이없어)
df['salary'] = np.where(df['job'] != 'student', 'yes', 'no')
print(df.head(), '\n')- 결과
컬럼 값을 더해서, 혹은 평균 등 값을 기반으로 수정하기, 등급 매기기
import pandas as pd
import numpy as np
friends = [{'name': 'John', 'midterm': 95, 'final': 85},
{'name': 'Ben', 'midterm': 85, 'final': 80},
{'name': 'Jenny', 'midterm': 30, 'final': 10},
{'name': 'Nate', 'midterm': 95, 'final': 100},
{'name': 'Kim', 'midterm': 70, 'final': 75}
]
# friends 라는 정보를 가지고, df라는 데이터 프레임을 생성한다
df = pd.DataFrame(friends, columns=['name', 'midterm', 'final'])
print(df.head(), '\n')
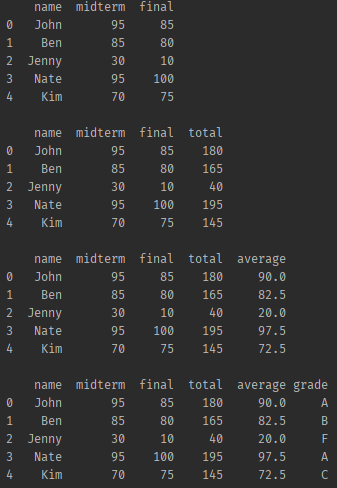
# 총점이라는 행을 추가한다, midterm 과 final 을 더해서!!!
df['total'] = df['midterm'] + df['final']
print(df.head(), '\n')
# 평균이라는 행을 추가한다, total을 2로 나눈 값으로
df['average'] = df['total'] / 2
print(df.head(), '\n')
# 점수에 따라 등급 매기기
grades = [] # 파이썬 빈 리스트 만들기
# for문을 통해 빈 리스트에 점수에 따라 등급을 넣기
for row in df['average']:
if row >= 90:
grades.append("A")
elif row >= 80:
grades.append("B")
elif row >= 70:
grades.append("C")
else:
grades.append("F")
df['grade'] = grades
print(df.head())- 결과
등급에 따라 함수 리턴 밸류를 넣어주기
import pandas as pd
import numpy as np
friends = [{'name': 'John', 'midterm': 95, 'final': 85},
{'name': 'Ben', 'midterm': 85, 'final': 80},
{'name': 'Jenny', 'midterm': 30, 'final': 10},
{'name': 'Nate', 'midterm': 95, 'final': 100},
{'name': 'Kim', 'midterm': 70, 'final': 75}
]
# friends 라는 정보를 가지고, df라는 데이터 프레임을 생성한다
df = pd.DataFrame(friends, columns=['name', 'midterm', 'final'])
print(df.head(), '\n')
# 총점이라는 행을 추가한다, midterm 과 final 을 더해서!!!
df['total'] = df['midterm'] + df['final']
print(df.head(), '\n')
# 평균이라는 행을 추가한다, total을 2로 나눈 값으로
df['average'] = df['total'] / 2
print(df.head(), '\n')
# 점수에 따라 등급 매기기
grades = [] # 파이썬 빈 리스트 만들기
# for문을 통해 빈 리스트에 점수에 따라 등급을 넣기
for row in df['average']:
if row >= 90:
grades.append("A")
elif row >= 80:
grades.append("B")
elif row >= 70:
grades.append("C")
else:
grades.append("F")
df['grade'] = grades
print(df.head())
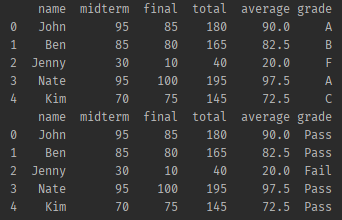
# 간단한 함수를 생성한다.
def pass_or_fail(row):
if row != 'F':
return "Pass"
else:
return "Fail"
# grade를 변경 시킬거다. 함수를 기반으로.. apply 라는 함수를 사용 해야 한다.
# df.grade를 변경시킬거야 = df.grade.적용시킬거야(pass_or_fail 이라는 함수를)
# print(df.grade.apply(pass_or_fail))
df.grade = df.grade.apply(pass_or_fail)
print(df.head())- 결과

삶을 스스로 통제하고 있다는 느낌을 받을 때 더 행복하고 성공한다.🍃