Decoder Base Model
-
GPT
- Causal Language Model, Auto-Regressive한 방식
- 앞 토큰 및 문맥을 토대로 뒤에 토큰을 예측
-
특징
- Auto Regressive:
- 순차적인 생성(예측), 이전의 생성된 토큰들을 보고 진행.
- 예시
생성 과정:
Step 1: "나는" → "밥을"
Step 2: "나는 밥을" → "먹"
Step 3: "나는 밥을 먹" → "었"
Step 4: "나는 밥을 먹었" → "다"
- Self-Attention:
- 중요한 토큰에 대한 인식
- 중요도에 다른 가중치 부여
- 현재까지의 시퀀스 내 토큰들 간의 관계파악
- 예시
"나는 점심에 밥을 먹었다"에서:
"밥을" 토큰은 "점심" 토큰에 높은 가중치
"먹었다" 토큰은 "밥을" 토큰에 높은 가중치
- 중요한 토큰에 대한 인식
- Causal Masking:
- 현재 시점 이전의 정보들만 알 수 있음. 미래의 토큰에 대해 알지 못함
- 예시
"나는 점심에 밥을 먹었다"에서:
"점심에" 토큰은 "나는과 점심에"를 보고
"밥을" 토큰은 "나는, 점심에, 밥을"를 보고
"먹었다" 토큰은 "나는, 점심에, 밥을, 먹었다" 4가지의 모든 토큰에 대해 본다.
- Auto Regressive:
LlaMA(라마)
- Facebook에서 발표한
open source기반 LLM 모델.- 초기엔 공개하지 않고, 연구 목적으로 승인하여 공개만 함.
- LlaMA 2부터는 신청만하면, 공개해주는 진행.
- LlaMA 3.2(2024.09)부터는 이미지까지 처리할 수 있는
Multi-Modal로 공개. - 만약 공개가 되지 않았다면, 여기까지 성장이 가능했을까?라는 의문은 있습니다.
Decoder Base Model 구조
- GPT는 모델 구조에 대해 공개하지 않으므로, LlaMA를 활용하여 모델의 구조를 살펴본다.
Trasformer 구조
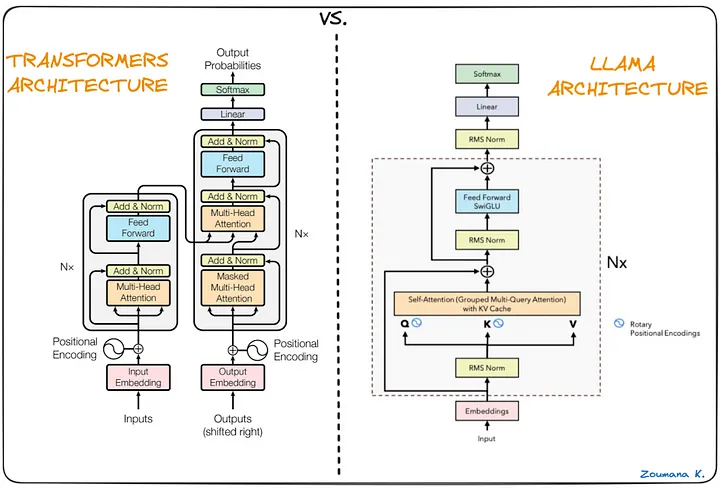
- 왼쪽부터 Transformer 구조, LlaMA구조로 Transformer의 Encoder-Decoder 구조에서 Decoder만 가져와서 사용하는 방식으로 간단히 생각할 수 있다.
GPT-2까지는 Decoder Architecture만 가져와서 사용했지만, LlaMA는 이를개선함.- Transformer의 자세한 내용은 Transformer 리뷰를 참고해주세요.
- Transformer는 기본적으로
Positional Encoding을 통해 절대적인 위치에 대한 정보를 제공하지만, 맨 처음 단에 이를 적용하기 때문에 layer가 깊어질 수록 뒤로 전달되는 위치 정보는 얕아지는 문제가 잇음.- 특히, 상대적위치 정보(A를 기준으로 얼마나 떨어져 있는지 등)에 약했음.
- 관련 논문
LlaMa 구조
-
위의 Transformer의 위치 정보에 대한 문제점을 해결하기 위해
Rotery Positional Embedding(RoPE)를 사용함.-
기하 벡터의
회전 변환을 사용.- 거리가 멀면 멀수록
θ의 누적량이 달라져 절대적 위치와 상대적 위치를 모두 알 수 있다.
- 거리가 멀면 멀수록
-
기존에 Input단계에서 적용을 Query와 Key단계에서 적용하는 것으로 변경.
-
Attention layer가 계산 될때마다 위치정보가 계속 추가됨.
-
실제 Llama 3 Code
def apply_rotary_emb( xq: torch.Tensor, xk: torch.Tensor, freqs_cis: torch.Tensor, ) -> Tuple[torch.Tensor, torch.Tensor]: xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2)) xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2)) freqs_cis = reshape_for_broadcast(freqs_cis, xq_) xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3) xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3) return xq_out.type_as(xq), xk_out.type_as(xk)
-
-
RMS Normalization
- 기존에 Attention Layer 이전에 적용하던 Normalization을 Attention Layer 이전에 적용.
- RMS Normalization 논문
- 실제 Llama 3 Code
class RMSNorm(torch.nn.Module): def __init__(self, dim: int, eps: float = 1e-6): super().__init__() self.eps = eps self.weight = nn.Parameter(torch.ones(dim)) def _norm(self, x): return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) def forward(self, x): output = self._norm(x.float()).type_as(x) return output * self.weight -
SwiGLU
Gelu에서 발전된 방식으로 계산의 효율성을 보다 높여서 진행하는 방법.- SwiGLU 논문
-
Grouped Query Attention(GQA)
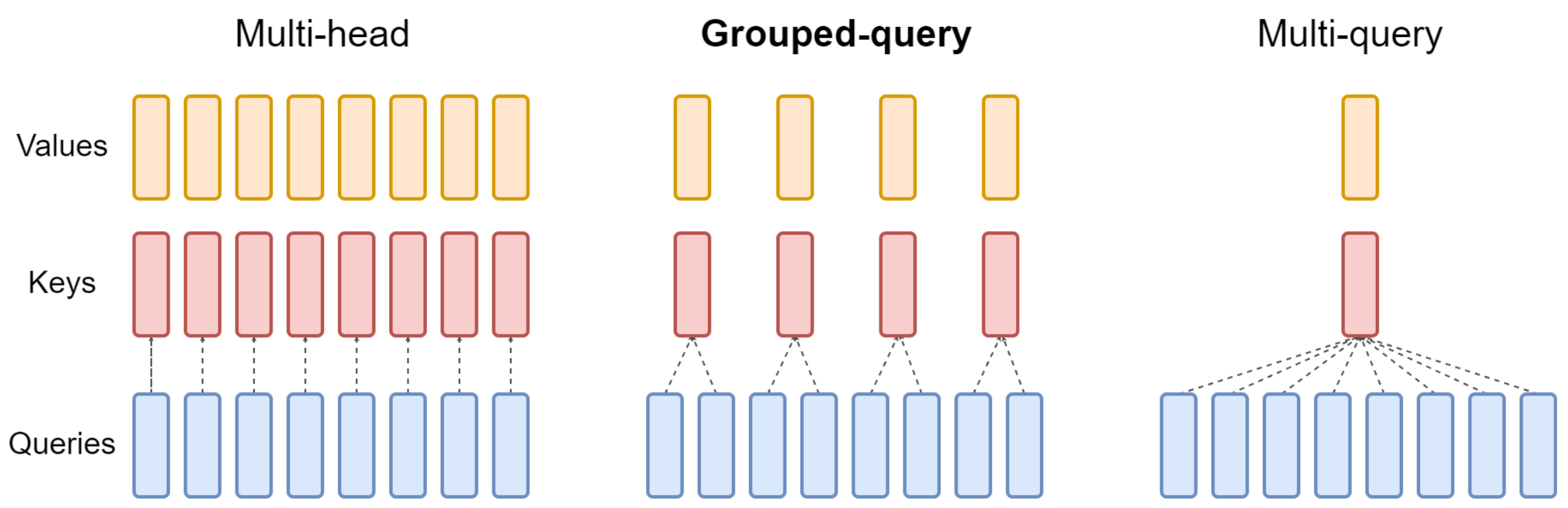
- Multi-head Attention은 기본적으로 계산량이 너무 많은 문제가 있어 이를 해결하기 위해 Multi-Query Attention(공통된 Value와 공통된 Key 사용)을 적용.
- 하지만 Multi-Query Attention은 계산량은 적지만 Multi-head Attention에 비해 성능이 떨어지거나 학습이 불안정하는 문제가 있어 이를 해결하기 위해 등장한 것이
Grouped Query Attention - GQA 논문
-
Multi layer Perceptron(FFN), MLP:
- 기본적으로 Attention layer을 통해 각 토큰들간의 관계가 어떻게 되는지를 알게됨.
- 알게된 내용을 바탕으로 Task을 수행하기 위해서 필요
- 추가적으로 Attention layer는 기본적으로 선형적 계산인데, MLP을 통해 비선형성을 추가할 수 있다.
비선형성의 추가로 복잡한 패턴이나 데이터의 비선형적 특징을 잘 포착할 수 있어진다.
-
Flash Attention
- Torch가 계산되는 메모리의 공간은 주로 sRAM의 공간으로,
A100만 하더라도 20mb로 매우 작은 크기를 가지고 있다. - 이 작은 공간에 Attention을 계산하면, 데이터 불러와서 계산 후 내리고 이 과정을 반복해야하는데 이를 최소화하는 방법이
Flash Attention이다.- 비록 계산량은 많아질 수 있지만, 계산 속도보다 데이터 주고받는 속도가 훨씬 느리기 때문에 학습속도가 빨라진다.
- 관련 논문
- Torch가 계산되는 메모리의 공간은 주로 sRAM의 공간으로,

AI Engineer 오승범