Encoder & Decoder
-
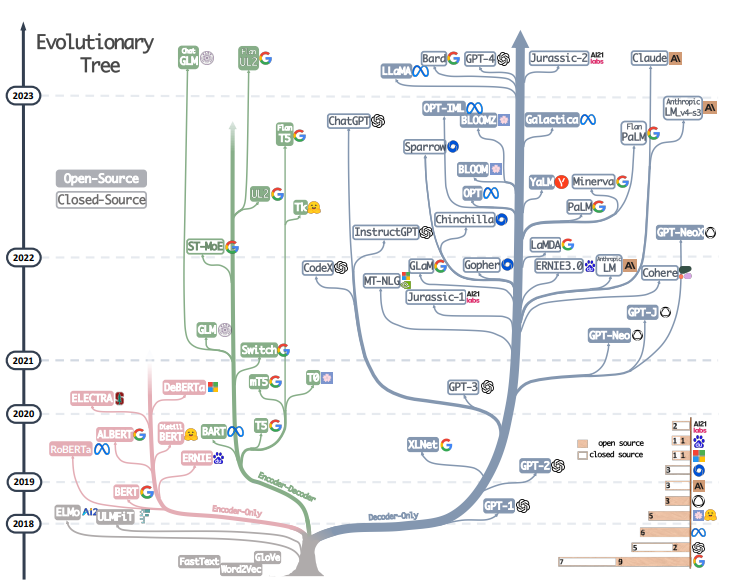
NLP Evolutionary Tree
-
2018년도에 Attention Is All You Need가 등장하면서 폭발적으로 성장하게 되었고, 크게 다음 3가지 분야에 대해 발전이 이루어짐.
- Encoder Base
- Decoder Base
- Encoder Decoder
-
위 그림에서는 표현되지 않은 RNN, LSTM, GRU 등 NLP 분야의 발전과정에 대해 생략된 파트들은 2018년도 이후와 비교하면 중요도가 비교적 떨어진다고 생각하여 논문의 저자들이 언급한 Glvoe, Word2vec, FastText 등에 대해서만 알고 넘어가도 괜찮다고 생각합니다.
-
또한, 시기적으로 GPT(OpenAI, 2018.06)도가 먼저 발표되었으나 그렇게 많은 주목(citation 11454)은 받지 못했고, BERT(Google, 2018.10)은 GPT에 비해 많은 주목(Citation 117454)을 받았음.
- 단순 인용수만 비교해도 10배 가까이 차이남.
- 실제로 GPT(Decoder Base)보다 BERT(Encoder Base)위주로 많은 발전이 이뤄졌었음.
- 하지만 OpeaAI가 GPT를 포기하지 않고, Decoder Base로 발전 시키고 GPT-2(OpenAI, 2019.02)에서 큰 주목을 받음. 당시에 GPT-2의 생성 능력이 뛰어나
가짜 뉴스 생성우려로 완전한 모델은 공개하지 않았으나 현재는 다 공개된 상태. - Emergent Abilities(2022)의 발견으로 Decoder base의 모델들의 파라미터들이 기하급수적으로 증가하였고, 증가하면 증가할수록 더 좋은 성능을 보여줌.
- 해당 모델들은 파라미터들이 많아 LLM(Large Language Model)이라고 부름.
Encoder Decoder
-
Encoder : 정보를 제한된 벡터 크기로 줄임(데이터 압축).
-
Decoder : 제한된 벡터를 가지고 정보를 생성(데이터 압축 해제).
-
대표 모델 : Transformer, BART, T5
-
Architecture
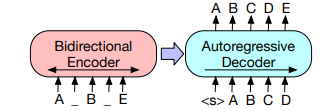
- 장점:
- Encoder의 장점인 전체 입력 Sequence의 문맥을 압축해서 표현.
- 모듈화 된 구조(Encoder와 Decoder를 독립적으로 최적화 가능)
- 단점:
- 높은 계산복잡도, 두 개의 네트워크를 사용하므로 계산량이 많음.
- 정보 손실, Encoder에서 정보를 압축하므로 정보의 손실이 있음.
- 확장성 부족, In-Context Learning의 사용 어려움.
Encoder Base
-
Encoder만 있는 구조.
-
대표 모델 : BERT, RoBERTa, ALBERT, ELECTRA
<MASK>토큰을 예측하는 형태로, Self-Supervised Learning 사용.
-
장점:
- 기본적으로 데이터를 압축하는 구조다 보니 문장에 대한
문맥의 이해가 가능하고,특징을 잘 추출.- 주로 문서분류(감정 분서, 스팸 필터링) 및 정보 검색으로 사용
- 또한 기본적으로
<MASK>토큰을 기반으로 학습하다 보니, 양방향의 정보를 활용할 수 있음.
- 기본적으로 데이터를 압축하는 구조다 보니 문장에 대한
-
단점:
- Auto-regressive한 Task에 적합하지 않고, 텍스트 생성에 직접 사용하는건 어려움.
Decoder Base(LLM)
-
Decoder만 있는 구조.
- Auto-regressive 방식 사용.
-
대표 모델 :
GPT 시리즈- 앞의 토큰과 문맥을 토대로 다음의 토큰을 예측(Next Token Prediction 사용)
- Emergent Abilities(모델 사이즈와 학습량을 증가하면 성능이 증가한다는 특징으로 여기서 더 자세하게 알수 있습니다.)
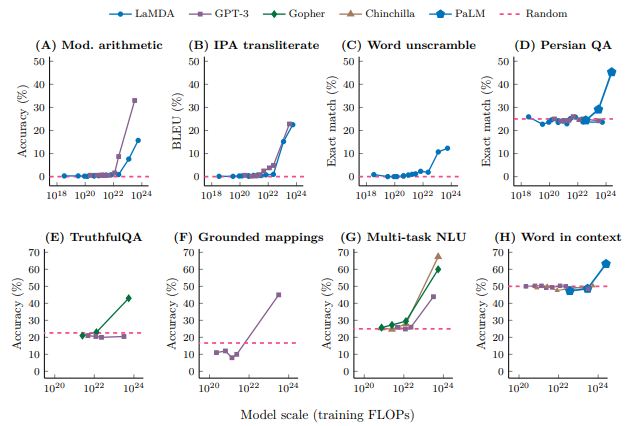
-
장점(특징):
- 텍스트 생성에 강점.
- Chain-of-Tought(CoT)를 사용하면 어려운 Task에서 뛰어난 성능을 보여줌.
- NLU Task 중에서 분류 관련해서도 생각보다 잘 품.
- 해당 과정은 zero-shot보다는 Few-shot을 사용했을 때 매우 뛰어남(
In-Context Learning).
- 해당 과정은 zero-shot보다는 Few-shot을 사용했을 때 매우 뛰어남(
- 효율성이 좋음, Encoder-Decoder 모델보다 학습 및 추론 속도가 빠름.
- Instruction Learning
- 모델이 해당 Task에 대해 특화되어 있지 않아서, 단순 지시문 하나
영어를 한국어로 번역해줘하나로 Task를 잘하게 됨.
- 모델이 해당 Task에 대해 특화되어 있지 않아서, 단순 지시문 하나
- Reinforcement learning Human Feedback(RLHF)
- AI 모델을 인간의 선호도와 피드백을 기반으로 학습시키는 방법
- 텍스트 생성에 강점.
-
단점:
- 개인이 학습할 수 있는 단계가 아님.
- 우리나라에게 주목받았던 GPT3의 파라미터는 약 1,750억개로, 이를 4090(메로리 24GB)로 학습하기 위해서 최소 63대는 있어야 학습이 가능함.
- gpt 4의 파라미터는 약 1.8조개로 약 642대가 필요.
- 개인이 학습할 수 있는 단계가 아님.

AI Engineer 오승범