
각 데이터베이스와 시스템 사이에 Kafka를 도입하여, End-to-End 방식이 아니라, 보내는 쪽(Producer)과 받는 쪽(Consumer)이 이 데이터가 어디서 왔고 어디로 연결할지 신경 쓸 필요 없이 Kafka에서 중계역할을 수행하게 됨.
그래서 메시지 '브로커' 라는 이름을 붙인 것으로 보인다.
- Producer (데이터 보내는 주체, Database 등)와 Consumer (데이터 가공 주체, Hadoop, Search Engine 등) 분리
- 전달받은 메시지를 다양한 형태의 여러 Consumer에게 보내는 것을 허용
- 높은 처리량을 위해 메시지 최적화시켜서 내부적으로 보관
- 연결 방식의 확장 (Scale-out) 가능
- 다양한 형태의 Eco-system 연동되므로 보내고 받는 용도뿐 아니라, 다양한 기능으로 이용 가능
- 높은 처리량, 확장 가능, 영구 보관, 고가용성
Kafka Broker
실행된 Kafka Application Server를 의미
출처 : [Apache Kafka] 개념, 설치 및 Producer/Consumer 사용 예제
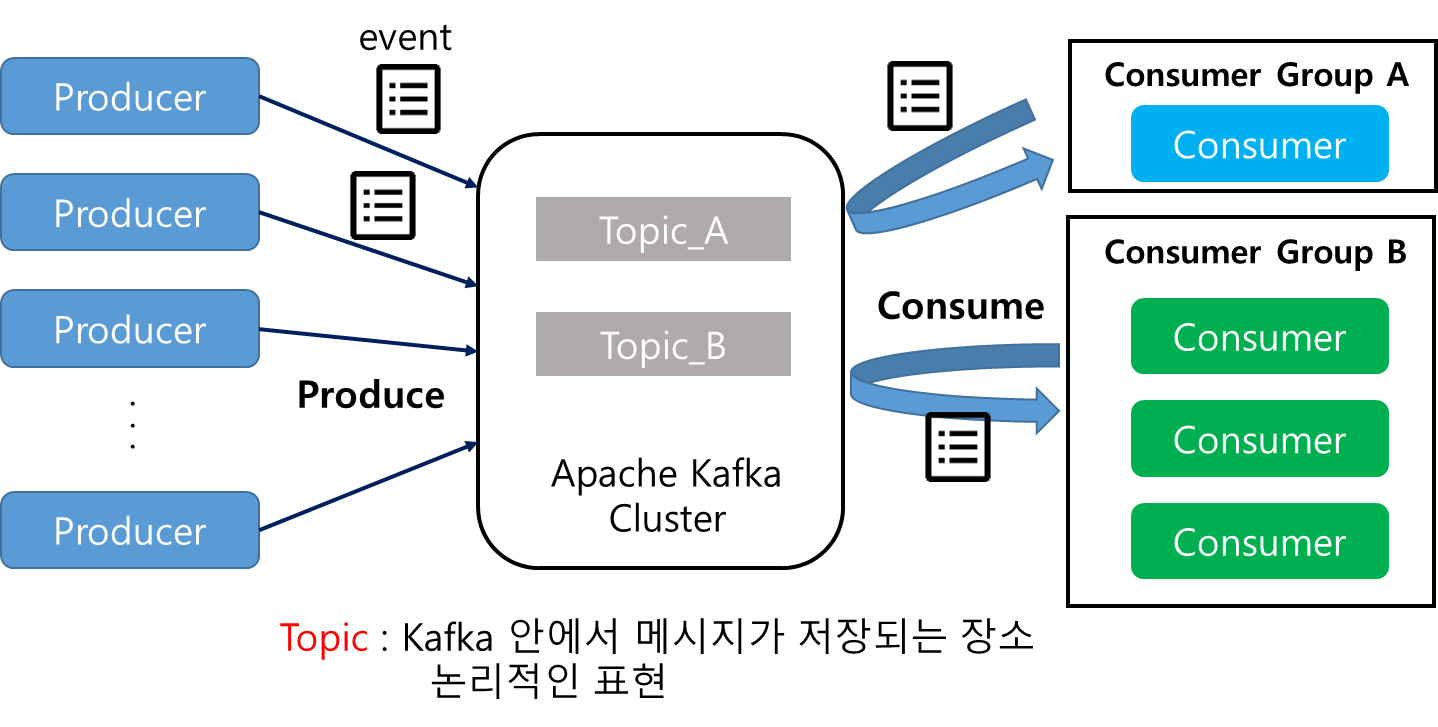
- Producer: 메시지를 생산해서 Kaffa의 Topic으로 메시지를 보내는 애플리케이션
- Consumer: Topic의 메시지를 가져와서 소비하는 애플리케이션
- Consumer group: Topic의 메시지를 사용하기 위해 협력하는 Consumer들의 집합
- 하나의 Consumer는 하나의 Consumer Group에 포함되며, Consumer Group내의 Consumer들은 협력하여 Topic의 메시지를 분산 병렬 처리함
출처 : Apache Kafka 주요 요소1(Producer, Consumer, Topic, Partition, Segment)
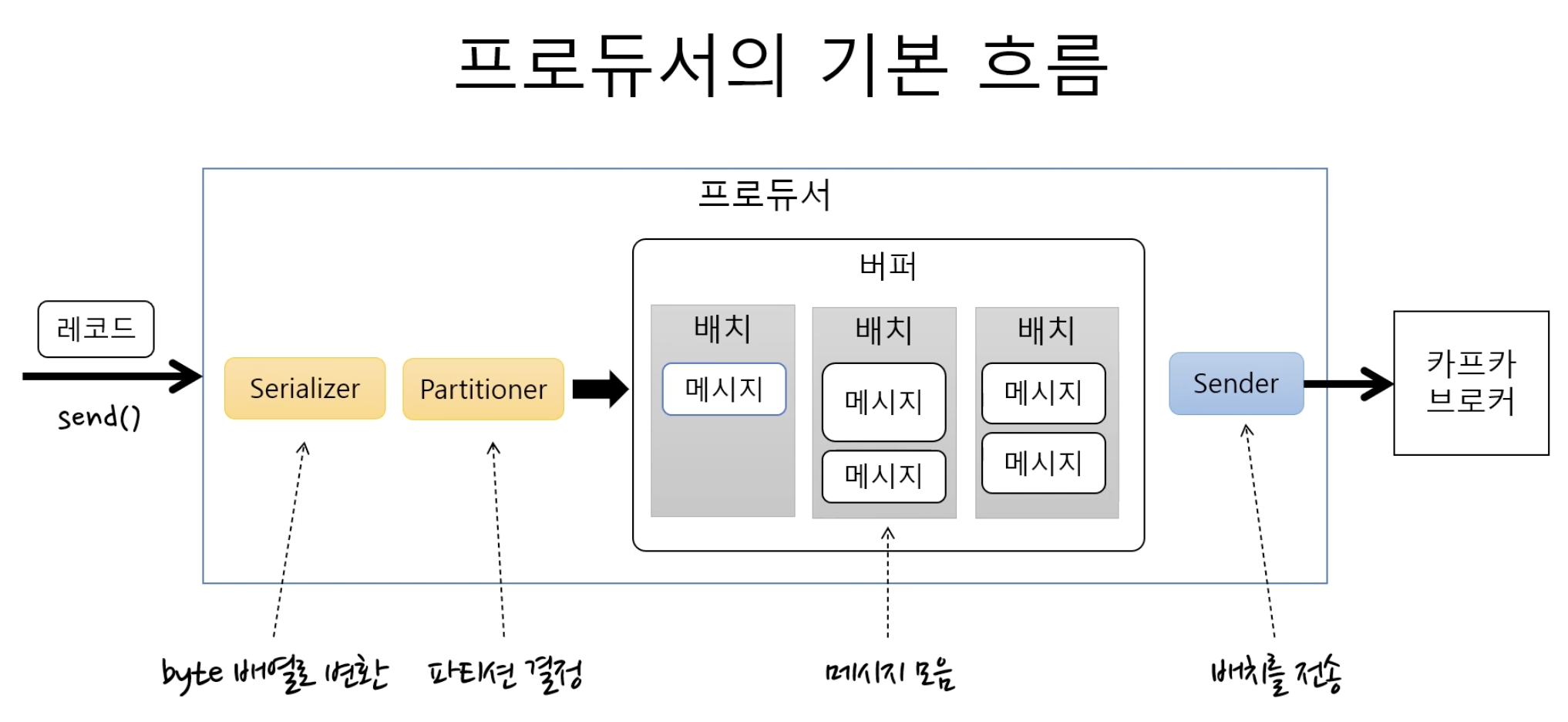

The Man Who Lift