1. KafKa Producer
Kafka의 토픽으로 메시지를 전송함.
ProducerRecord: Kafka로 전송하기 위한 실제 데이터. topic, partition, key, value로 구성.
1-1. 동작 원리
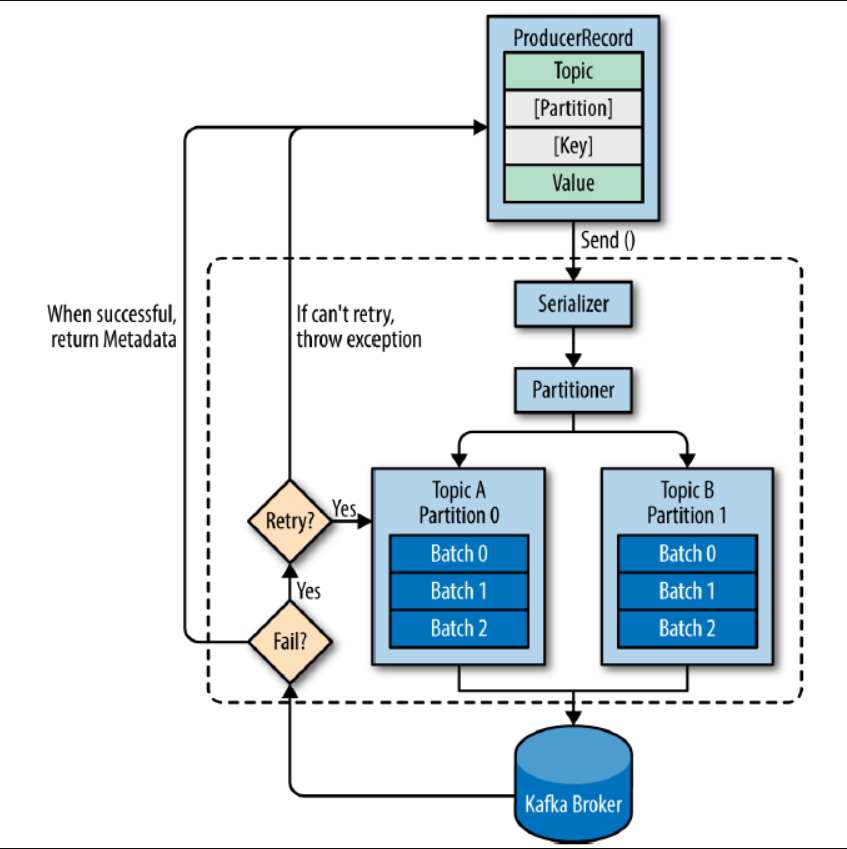
- producer가 kafka로 record를 전송할 때, 특정 topic으로 메시지를 전송함.
record에 topic과 value는 필수이고, partition과 key는 선택 사항임.
partition은 특정 파티션을 지정하기 위해 사용되고, key는 특정 partition에 record들을 정렬하기 위해 사용됨. - 각 record들은 producer의 send 메소드를 사용하여 serializer, partitioner를 거치게 됨.
- partition을 지정했다면 partitioner는 아무 동작도 하지 않고 지정된 partition으로 record를 전달함. partition을 지정하지 않은 경우 key를 이용해서 partition을 선택하여 record를 전달. 기본적으로 round robin 방식으로 동작.
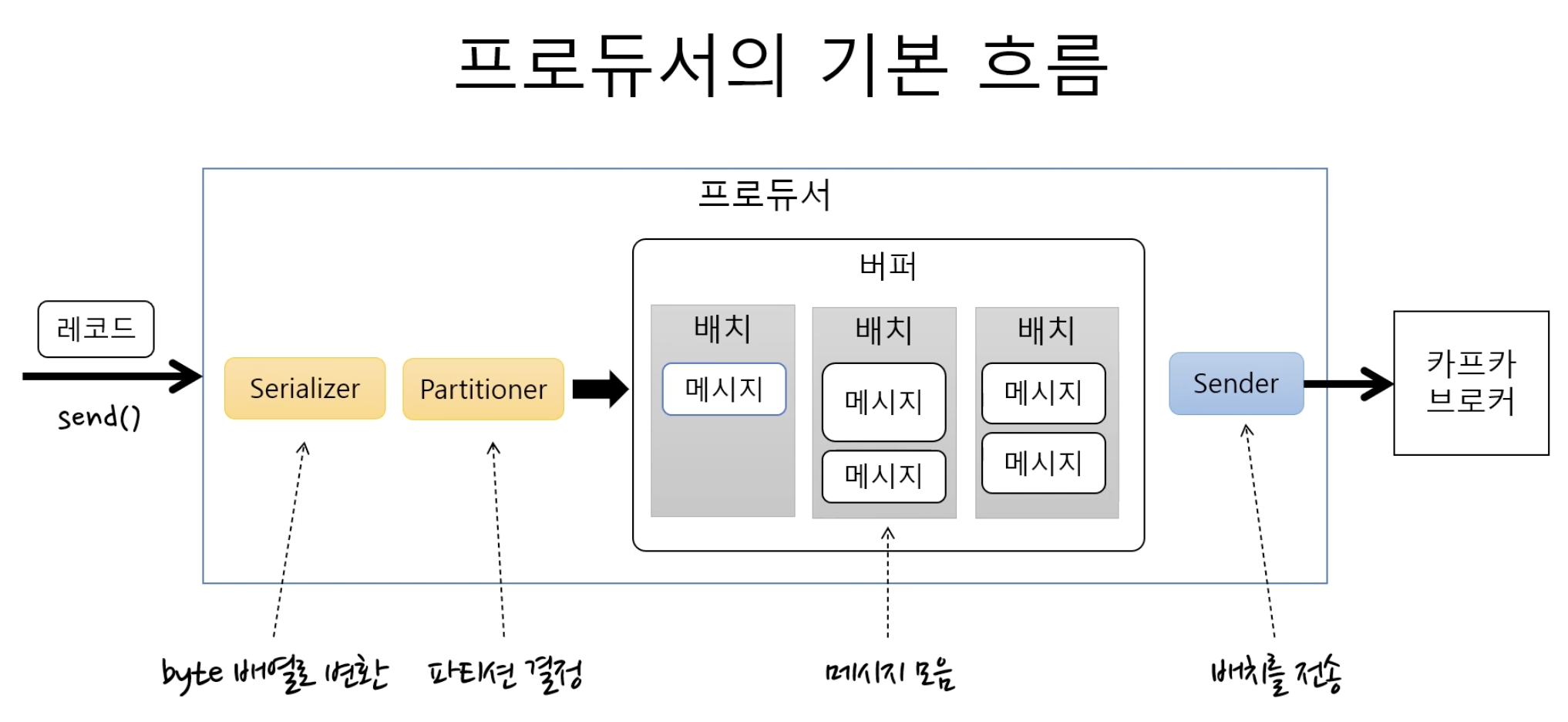
- send() 메소드 동작 이후 record들은 producer가 kafka로 전달하기 전에 배치 전송을 위해 partition별로 잠시 모아 둠. 전송 실패 시 재시도 동작이 이루어지고, 지정한 횟수만큼 재시도가 실패하면 최종 실패로 전달하게 됨. 전송 성공 시 성공에 대한 메타데이터를 리턴함.
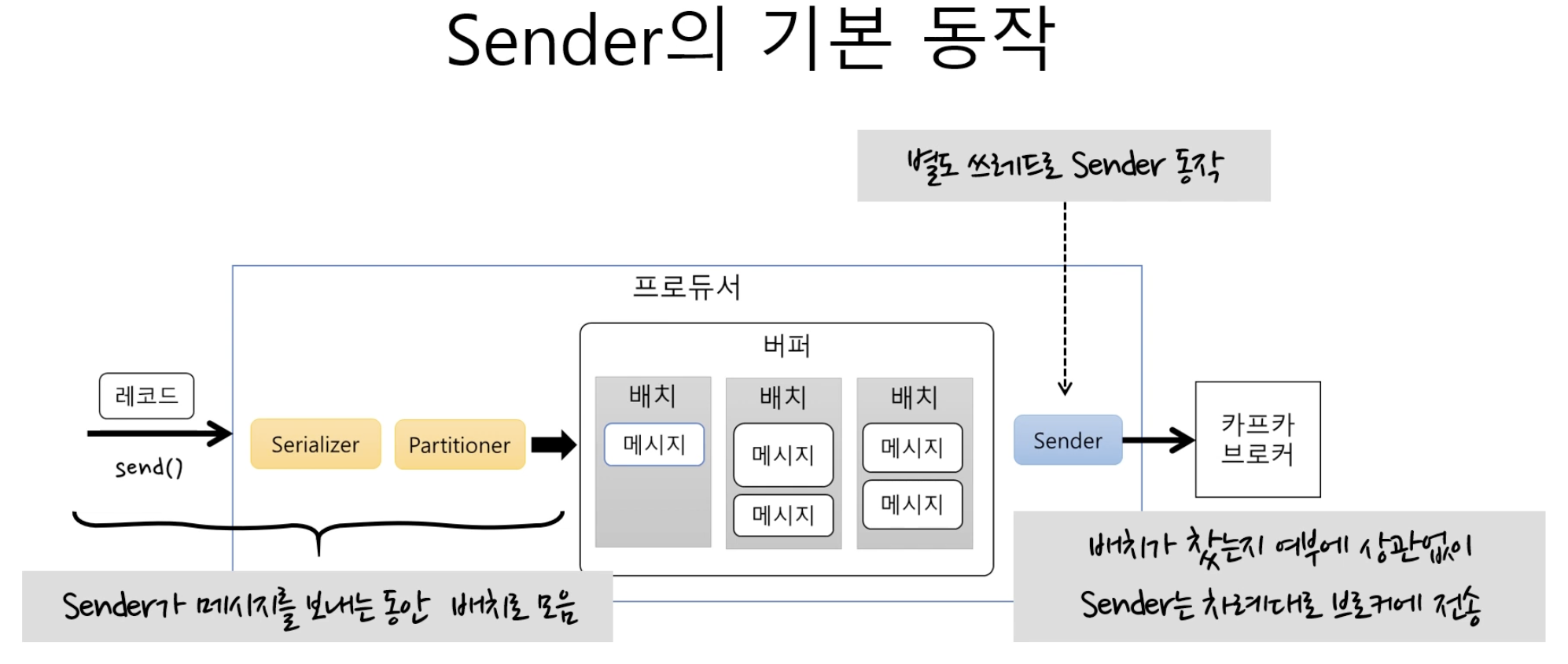
sender가 메시지를 보내는 것과, batch로 메시지를 모으는 것이 별도 쓰레드로 동작함.
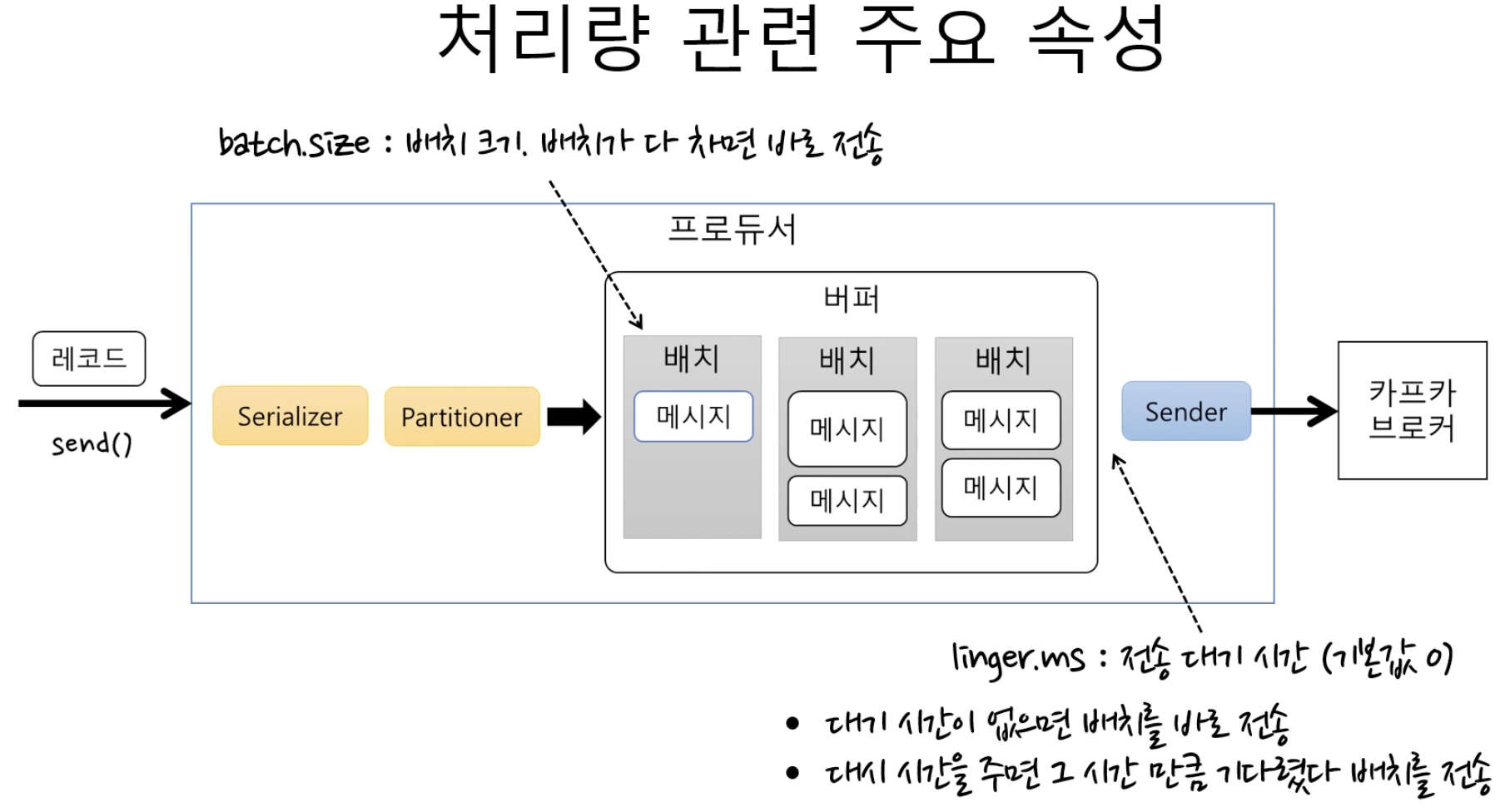
- batch.size: 배치 크기, 배치가 다 차면 바로 전송함
- linger.ms: 전송 대기 시간, 대기 시간이 없으면 배치를 바로 전송함.
1-2. ack
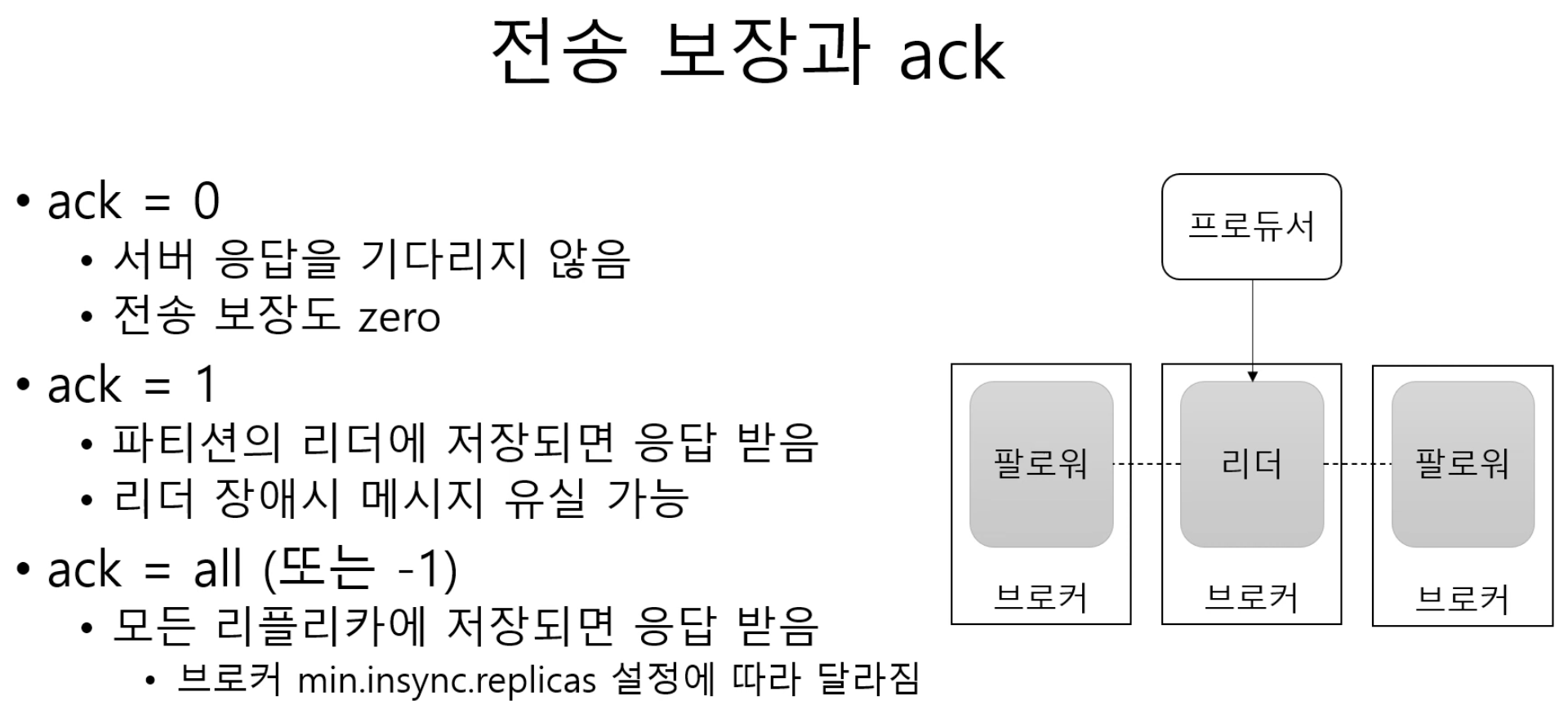
전송 보장을 하지 않아도 되는 서비스엔 ack을 0으로, 전송 보장이 중요한 서비스의 경우 ack = 1 or all로 설정.
1-3. min.insync.replicas

ack = all이면 모든 partition 복제본에 저장되었을 경우 응답을 받는다. 이 경우를 유연하게 처리하기 위해 broker에서 min.insync.replicas 옵션을 사용하면, 몇 개의 최소 partition에 저장되었을 때 응답을 보낼건지 정할 수 있다.
리플리카 개수가 3개, ack = all, min.insync.replicas = 3인 경우, 리터와 팔로워 2개에 저장되면 성공 응답을 받는다. 이러한 경우 하나의 broker에서라도 장애가 발생하면 저장에 실패한다.
1-4. 에러 유형
전송 과정에서 실패
- 전송 타임 아웃(일시적인 네트워크 오류 등)
- 리더 다운에 의한 새 리더 선출 진행 중
- 브로커 설정 메시지 크기 한도 초과
- 등등
전송 전 실패
- 직렬화 실패(producer 자체 요청 크기 제한 초과)
- producer 버퍼가 차서 기다린 시간이 최대 대기 시간 초과
- 등등
1-5. 실패 대응 방법
1. 재시도
브로커 응답 타임 아웃, 일시적인 리더 부재 등의 이유라면 재시도 처리 가능.
send() 메서드에서 exception 발생 시 or callback 메서드에서 exception 발생 시 재시도 처리.
producer는 자체적으로 broker 전송 과정에서 에러가 발생하면, 재시도 가능한 에러에 대해 재전송을 시도함. (retries 속성)
하지만 특별한 이유가 없다면 무한 재시도는 X
2. 기록
별도 파일, DB등을 이용해서 실패한 메시지를 기록, 추후 보정 작업 진행.
기록 시기:
- send() 메서드에서 exception 발생 시
- send() 메서드에서 전달한 callback 메서드에서 exception 받는 경우
- send() 메서드가 리턴한 Future의 get() 메서드에서 exception 발생 시
전송이 성공했는데 브로커 ack 응답이 늦게 온 경우 중복 발생할 가능성이 있음. 이 때 producer의 enable.idempotence 속성을 참고하면 중복 전송 가능성을 줄일 수 있다.
1-6. 재시도와 전송 순서
max.in.flight.requests.per.connection: 블록킹 없이 한 커넥션에서 전송할 수 있는 최대 전송중인 요청 개수. -> 한 번에 보낼 수 있는 batch의 최대 개수.
이 값이 1보다 크다면, 재시도 시점에 따라 메시지 순서가 바뀔 수도 있다.
ex) max.in.flight.requests.per.connection = 3인 경우,
batch1 전송 -> 실패
batch2 전송 -> 성공
batch3 전송 -> 성공
batch1 재전송 -> 성공
이런 상황에서 batch는 2 3 1 순서로 전송되고, 순서가 바뀔 수 있다.
전송 순서가 중요한 서비스인 경우 max.in.flight.requests.per.connection를 1로 지정해야 함.
1-7. producer API
- Apache Log4j
- 로그 출력 시 사용하는 자바 기반 로깅 유틸리티 소프트웨어
- Kafka Appender
- Apache Flume
- 다량의 로그 데이터 효율적으로 수집, 취합, 이동하기 위한 분산형 소프트웨어
- Kafka Sink
- Fluentd
- 크로스 플랫폼 오픈소스 데이터 수집 소프트웨어
- fluent-plugin-kafka
- Logstash
- 일래스틱에서 제공하는 OSS(Open Source Software) 데이터 수집 엔진
- logstash-output-kafka
2. Consumer
producer가 kafka topic에 메시지를 전송하면 해당 메시지들은 broker의 로컬 디스크에 저장됨.
consumer의 poll() 메서드는 topic에 저장된 메시지를 가져오는 역할을 수행함.
2-1. Consumer Group
하나 이상의 consumer들이 모여 있는 그룹. consumer는 반드시 consumer group에 속하게 됨.
- consumer group은 각 partition의 leader(replication된 partition의 leader)에게 kafka topic에 저장된 메시지를 가져오기 위한 요청을 보냄.
- partiton 수와 consumer(하나의 consumer group 안에 있는 consumer들) 수를 고려할 때, 무조건 1대1 매핑이 되야 하는 것은 아니지만 partition 수 < consumer 수 구조는 바람직하지 않다. 이런 구조에서 초과되는 consumer는 그냥 대기 상태로 존재하기 때문에 처리량이 늘지 않는다.
- consumer group 내부 consumer에서 장애가 발생할 경우, consumer group 내부에서 리밸런싱 동작을 통해 동일 group의 다른 consumer가 그 역할을 대신 수행하므로 굳이 장애 대비를 위한 추가 consumer 리소스를 할당하지 않아도 된다.
- 따라서 만약 처리량을 높이기 위해 consumer의 수를 늘린다면, partiton의 수도 늘려야 한다.
예시
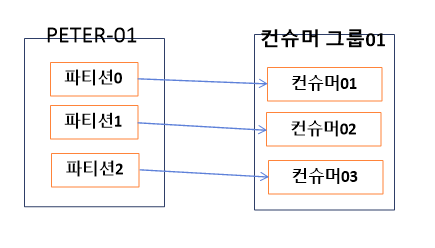
peter-01 topic에 3개의 partition 존재.
consumer group01에 3개의 consumer 존재.
consumer group 내부의 consumer들은 서로의 정보를 공유함.
consumer01에 문제가 생겨 종료되었다면, consumer02 or consumer03은 consumer01이 하던 일을 대신해서 peter-01 topic의 partition0을 처리한다.
2-2. commit, offset
작동 방식
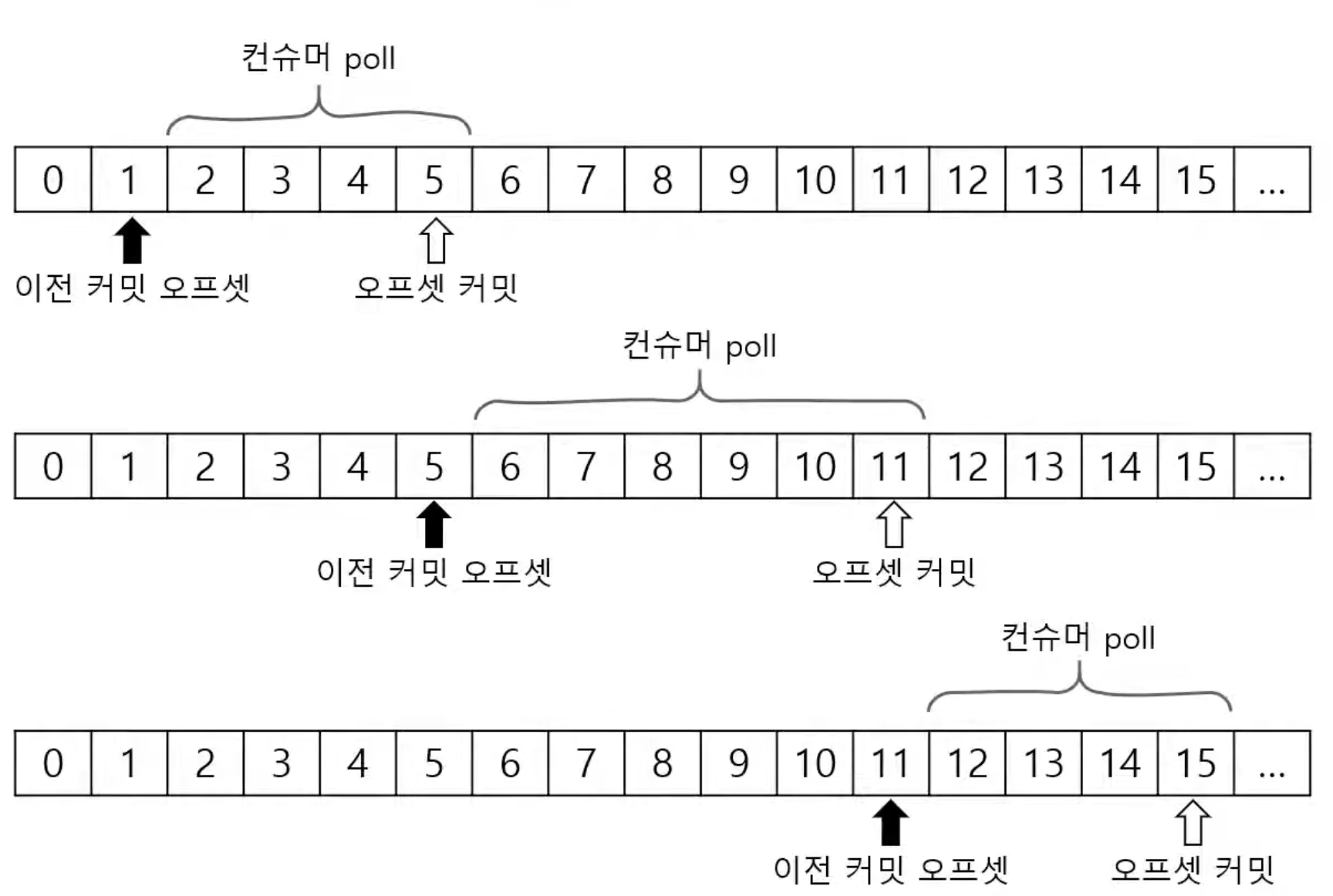
이전 commit offset 이후 offset부터 record를 읽고, 다 읽었으면 갱신된 offset을 commit한다.
2-3. consumer 설정값
fetch.min.bytes
- broker가 전송할 최소 데이터 크기. poll() 메서드가 불렸을 때 해당 값 이상의 데이터가 쌓일 때까지 기다렸다가 준다.
- 이 값이 크면 대기 시간은 늘어나지만, 처리량이 증가한다.
- 기본값: 1
fetch.max.wait.ms
- 데이터가 최소 크기가 될 때까지 기다리는 시간.
- 데이터가 최소 크기가 되지 않는다고 무한정 기다릴 수 없다. 따라서 값에 해당하는 시간이 지나면, broker는 데이터가 최소 크기 이상 쌓이지 않더라도 보낸다.
- poll() 메서드에 있는 대기시간과는 별개의 설정값임. poll() 메서드에 있는 대기시간은, 만약 poll()을 했는데 소비할 record가 없는 경우에, 다음 poll()을 부르기 전까지 대기하는 시간임.
- 기본값: 500(ms)
max.partition.fetch.bytes
- partition당 server에서 리턴할 수 있는 최대 크기.
- 해당 크기가 넘어가면 바로 리턴함.
- 기본값: 1048576(1MB)
poll() 메서드를 호출하는 빈도는 client 코드에 의해 제어됨. 무한 루프 안에 poll() 메서드가 있다면 빈도는 poll() 호출에서 반환된 record를 처리하는 데 걸리는 시간과, 루프의 다른 부분에서 소요된 시간에 따라 결정됨.
enable.auto.commit
- true: 일정 주기로 consumer가 읽은 offset commit (기본값)
- false: 수동으로 commit해야 함.
auto.commit.interval.ms: 자동 commit 주기
- 기본값: 5000(5초)
poll(), close() 메서드 호출시에는 자동 commit 실행됨.
2-4. 동일 메시지 조회 가능성, 재처리와 순서
kafka에서는 일시적인 commit 실패, 리밸런싱 등에 의해 consumer가 동일한 메시지를 조회할 가능성이 존재.
데이터 특성에 따라 timestamp, 일련 번호 등을 활용해야 함.
2-5. consumer group 리밸런싱
consumer는 heartbeart를 broker에 전송해서 연결 유지.
broker는 consumer로부터 heartbeat가 없으면 consumer를 group에서 빼고 리밸런스 진행.
session.timeout.ms
- 세션 타임아웃 시간
- 기본값: 10000(10초)
- 해당 시간동안 heartbeat가 없으면 리밸런싱.
heartbeat.interval.ms
- heartbeat 전송 주기
- 기본값: 3000(3초)
- session.timeout.ms의 1/3 이하를 추천.
max.poll.interval.ms
- poll() 메서드의 최대 호출 간격.
- 해당 값이 지나도록 poll()이 호출되지 않으면 리밸런싱.
2-6. 종료 처리.
다른 쓰레드에서 wakeup() 메서드를 호출하면, poll() 메서드에서 WakeupException이 발생함.
close() 메서드로 종료처리를 한다.
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop);
consumer.subscribe(Collections.singleton("topic1");
try {
while (true) {
ConsumerRecords<String, STring> records = consumer.poll(Duration.ofSeconds(1);
...
}
} catch (Exception ex) {
...
} finally {
consumer.close();
}2-7. Consumer API
- Apache Spark
- 빅데이터 처리를 위한 오픈 소스 클러스터 컴퓨팅 프레임워크
- Spark Streaming
- Apache Samza
- 스트림 처리용 오픈소스 소프트웨어로, 준 리얼타임 비동기 계산 프레임워크
- Apache Flink
- 스트림 처리용 오픈소스 프레임워크
2-8. 기타
Kafka consumer는 쓰레드로부터 안전하지 않다. KafkaConsumer 단일 인스턴스가 동시에 여러 쓰레드에서 사용되면 안 된다는 의미이다. 여러 쓰레드에서 소비해야 하는 경우, 각 쓰레드에서는 각기 다른 KafkaConsumer 인스턴스를 사용해야 한다. 예외적으로 wakeup() 쓰레드만 다른 쓰레드에서 호출해도 안전하도록 설계되었다.
출처
https://zeroco.tistory.com/105
https://www.youtube.com/watch?v=geMtm17ofPY
https://www.youtube.com/watch?v=xqrIDHbGjOY
