참고자료
https://www.youtube.com/watch?v=_PwhiWxHK8o
https://sanghyu.tistory.com/7
https://en.wikipedia.org/wiki/Support_vector_machine
https://jaejunyoo.blogspot.com/2018/01/support-vector-machine-1.html#mjx-eqn-eqdr
https://decisionboundary.tistory.com/2
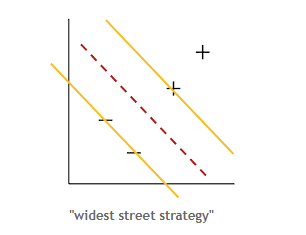 출처 : https://jaejunyoo.blogspot.com/2018/01/support-vector-machine-1.html#mjx-eqn-eqdr
출처 : https://jaejunyoo.blogspot.com/2018/01/support-vector-machine-1.html#mjx-eqn-eqdr
SVM이란?
SVM은 두 개의 집단을 분류를 선형적으로 분류를 한다. 다른 분류 기법과는 다르게 위의 사진과 같이 두 집단 사이의 여백(margin)이 가장 넓어지도록 분류한다.그럼 어떻게 하면 가장 잘 분류할 수 있는 기준을 알 수 있을까? 먼저 SVM의 decision rule을 알아보기전에 간단한 용어 정리부터 해보자.
support vector : '+' sample과 '-' sample 들이 모인곳에서 최외각에 있는 sample을 support vector라고 한다. 이 벡터들을 기준으로 margin을 구한다.
hyper plane : 어떤 N차원 공간에서 한 차원 낮은 N-1차원의 subspace를 뜻함
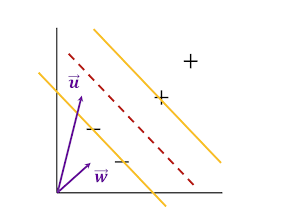 출처: https://jaejunyoo.blogspot.com/2018/01/support-vector-machine-1.html#mjx-eqn-eqdr
출처: https://jaejunyoo.blogspot.com/2018/01/support-vector-machine-1.html#mjx-eqn-eqdr
SVM decision Rule
위의 그림에서 w는 support vector 사이의 여백을 가장 크게하는 방향을 뜻한다. 크기는 우선 상관하지 않는다. u는 임의의 vector를 뜻한다. 두 벡터를 내적시킨다면
w⋅u+b≥0then′+′
이 식을 구할 수 있다. 이것을 통해 알 수 잇는 것은 위 식이 0보다 같거나 크면 u가 '+' 영역에 있고 0보다 같거나 작으면 -샘플 쪽에 있다는 것을 알 수 있다. 하지만,여기서 어떤 기준으로 w와 b를 잡아야 하는지 모른다. 이를 위해 몇가지 조건을 더 건다.
w⋅x++b≥1w⋅x−+b≤−1
여기서 복잡한 식을 줄이기 위해 새로운 변수를 추가해 다시 정의한다.
yi={1−1for ′+′for ′−′
양변에 yi를 곱해주면
yi(w⋅xi+b)≥1yi(w⋅xi+b)−1≥0
으로 정리할 수 있다. 상황에 따라 복잡했던 식을 하나의 간단한 식으로 만들었다. 이 때, x를 노란선 위에 있다고 가정을 하면,
yi(w⋅xi+b)−1=0
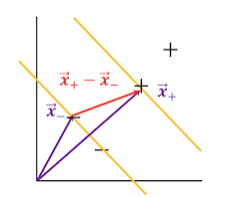 출처: https://jaejunyoo.blogspot.com/2018/01/support-vector-machine-1.html#mjx-eqn-eqdr
출처: https://jaejunyoo.blogspot.com/2018/01/support-vector-machine-1.html#mjx-eqn-eqdr
이된다. 우리는 가장 최대의 margin을 구하는것이 목표이다. 폭을 구하려면 각 영역에 있는 support vector의 차를 w의 단위벡터와 내적을 시키면 알 수 있다.
Width=(x+−x−)⋅∥w∥w
그리고 위에서 간단하게 정리한 식을 대입하면
Width=∥w∥2
폭을 알았으니 이 값이 최대값이 이루어지면 된다.
maxw1→min∥w∥→min21∥w∥2
이 과정은 모두 수학적 편의를 위해서이다. 위의 정의한 조건들을 라그랑주 승수법을 활용해 신경쓰지 않고 풀 수 있다. 라그랑주 승수법은 간단히 말하자면 모든 제약식에 라그랑주 승수(Lagrange Multiplier) λ를 곱하고 등식 제약이 있는 문제를 제약이 없는 문제로 바꾸어 문제를 해결하는 방법이다. 아래 식에서는 α를 뜻한다.
L=21∥w∥2−∑αi[yi(w⋅xi+b)−1]
최대 최소등 극점을 알아야 하므로 각각의 변수에 따른 편미분을 진행한다.
∂W∂L=w−∑αiyi⋅xi=0→w=∑αiyi⋅xi
∂b∂L=∑αiyi=0
w은 몇몇 샘플들의 선형 결합으로 이루어짐을 알 수가 있다. α가 0인 경우를 제외하고 말이다. 이제 구한 w를 위에서 정의한 간단한 식에 대입을 해보자.
L=21(∑αiyi⋅xi)(∑αjyj⋅xj)−(∑αiyi⋅xi)(∑αjyj⋅xj)−∑αiyib+∑αi=∑αi−i∑j∑αiαjyiyjxixj
위 식을 통해 α를 구하게 되면 w 와b를 구할 수 있게 되고 이를 통해 x가 supportvector라 정의할 수 있다. SVM은 신경망과는 달리 localminima에 빠질 걱정을 안해도 되는 것이 특징이다.
 출처 : https://jaejunyoo.blogspot.com/2018/01/support-vector-machine-1.html#mjx-eqn-eqdr
출처 : https://jaejunyoo.blogspot.com/2018/01/support-vector-machine-1.html#mjx-eqn-eqdr
