참고자료
https://www.youtube.com/watch?v=AA621UofTUA&t=2612
https://gaussian37.github.io/dl-concept-vit/
https://junklee.tistory.com/117
https://wikidocs.net/137253
https://heekangpark.github.io/nlp/attention
https://arxiv.org/pdf/2010.11929v2.pdf
https://arxiv.org/pdf/1706.03762.pdf
https://re-code-cord.tistory.com/entry/Inductive-Bias%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
Seq2Seq모델의 한계
- 입력 시퀀스의 모든 정보를 하나의 고정된 크기의 벡터(context vector)에 압축하려다 보니 정보의 손실이 생기고 시퀀스의 길이가 길어지면 정보의 손실이 더 커짐
- RNN 구조로 만들어진 모델이다 보니, gradient vanishing등의 현상이 발생
 출처: wikidocs
출처: wikidocs
Attention이란?
Attention 메커니즘은 Seq2Seq 모델의 문제점을 개선하기 위해 제안되었다. 고정된 크기의 벡터(context벡터) 하나에 입력 시퀀스의 모든 정보를 다 담아야 하는 인코더의 부담을 덜기 위해, 디코더에서 다음 단어 예측을 위해 인코더의 마지막 벡터 뿐만 아니라 인코더의 층 마다의 시점을 입력으로 사용한다.
Seq2Seq with Attention
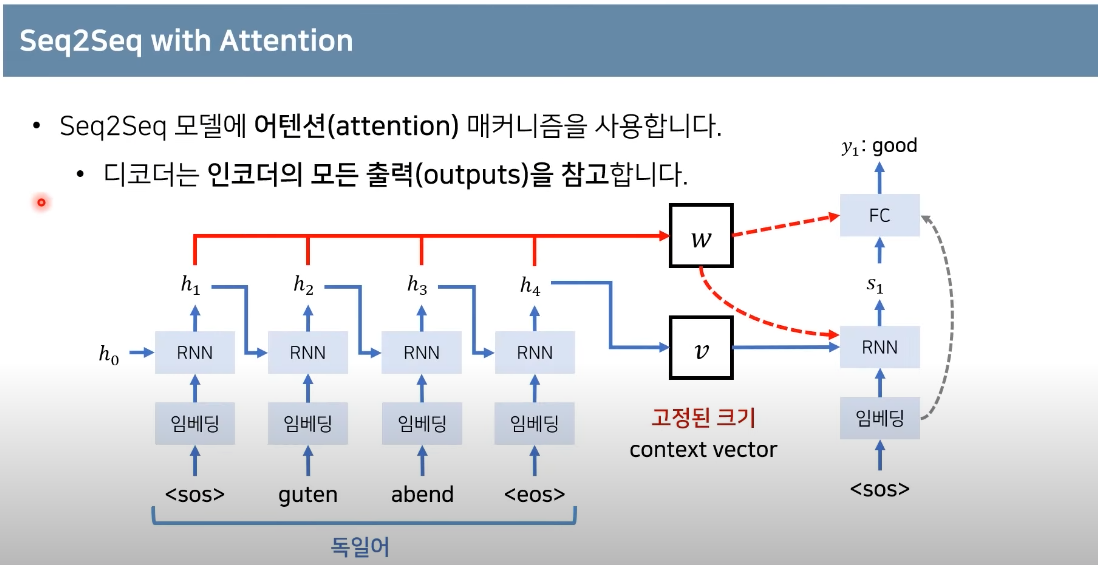 출처 : https://www.youtube.com/watch?v=AA621UofTUA&t=2612
출처 : https://www.youtube.com/watch?v=AA621UofTUA&t=2612
i = 현재의 디코더가 처리중인 인덱스
j = 각각의 인코더 출력 인덱스
에너지(Energy)
가중치(Weight)
Transformer란?
트랜스포머는 자연어처리(NLP)에서 사용되는 알고리즘이다. RNN이나 CNN을 사용하지 않고 학습을 한다. 대신에 Positional Encoding을 사용한다. BERT와 같은 향상된 네트워크에서도 채택이 되고 있다. 인코더와 디코더로 구성이 되어있으며, Attention 과정을 여러 층에서 반복한다.
 출처: https://arxiv.org/pdf/1706.03762.pdf
출처: https://arxiv.org/pdf/1706.03762.pdf
RNN을 사용하지 않으려면 위치 정보를 포함하는 임베딩을 해야하므로 Positional Encoding을 사용한다. 임베딩이 끝난 이후에는 Attention을 진행한다. 성능 향상을 위해 Residual Learning도 사용한다.그 과정 속에서 Attention과 Normalization을 반복해준다.각각의 층은 서로 다른 파라미터를 가지고 있다. 트랜스포머에서도 인코더와 디코더의 구조를 따릅니다. Transformer에서는 마지막 인코더 층의 출력이 모든 디코더 레이어에 입력이 된다. 인코더와 디코더는 Multi-Head Attention층을 사용한다.
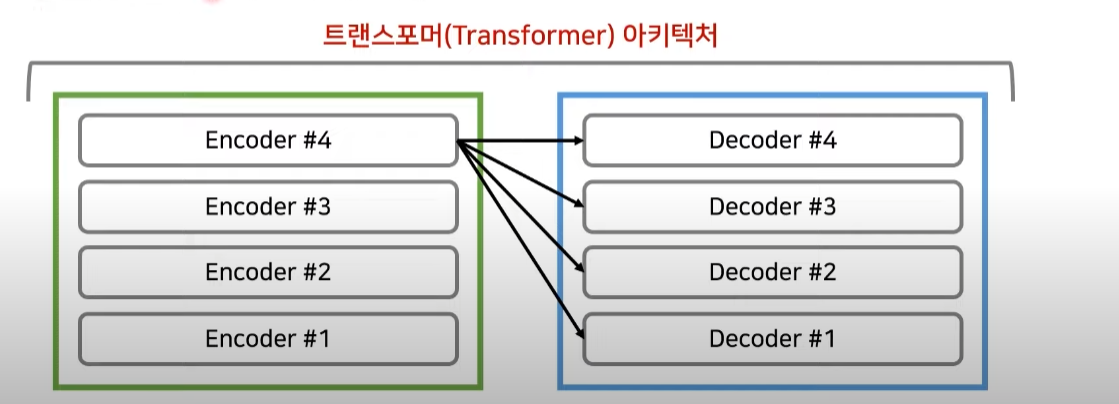 출처 : https://www.youtube.com/watch?v=AA621UofTUA&t=2612
출처 : https://www.youtube.com/watch?v=AA621UofTUA&t=2612
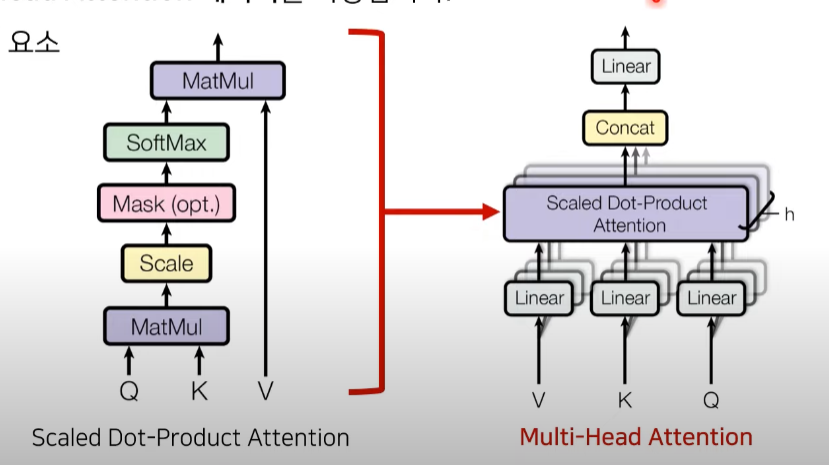 출처 : https://www.youtube.com/watch?v=AA621UofTUA&t=2612
출처 : https://www.youtube.com/watch?v=AA621UofTUA&t=2612
Attention의 세 가지 입력 요소
- Query : 무언가를 물어보는 주체 (I)
- Key : 물어보는 대상 (I am a teacher)
- Value : query와 key의 연관성에 대해서 곱해주는 값
h: head의 개수
또한, mask matrix를 이용해 특정 단어는 무시할 수 있도록 한다. 즉, 마스크 값으로 음수 무한의 값을 넣어 softmax 함수의 출력이 0%에 가까워지도록 한다. MultiHead(Q, K, V)를 수행한 뒤에도 차원(dimension)이 동일하게 유지된다.
ViT란?
Transformer의 전체적인 틀을 크게 변경하지 않은 상태에서 이미지 처리를 위한 용도로 사용되었다. CNN에 의존하지 않고 이미지 패치의 시퀀스를 입력값으로 사용하는 transformer를 적용하여 CNN 기반의 모델보다 좋은 성능을 보였다.
장점
- transformer의 구조를 크게 변경하지 않고 사용하므로 확장성이 좋다. 기존 attention 기반의 모델들은 이론상 좋았어도, 특성화된 attention 패턴 때문에 확장에 어려움이 있음
- large scale에서의 학습에 우수한 성능을 보임
- transfer learning 시 CNN 보다 학습에 더 적은 계산 리소스를 활용함.
단점
- inductive bias의 부족으로 인하여 CNN보다 데이터가 많이 요구된다.
- transformer 모델은 attention 구조만을 사용하므로 CNN같이 local receptive field를 보는 것이 아니라 데이터 전체를 보고 attention할 위치를 정하기 때문에 CNN보다 더 많은 데이터를 필요로 한다.
 출처: https://arxiv.org/pdf/2010.11929v2.pdf
출처: https://arxiv.org/pdf/2010.11929v2.pdf
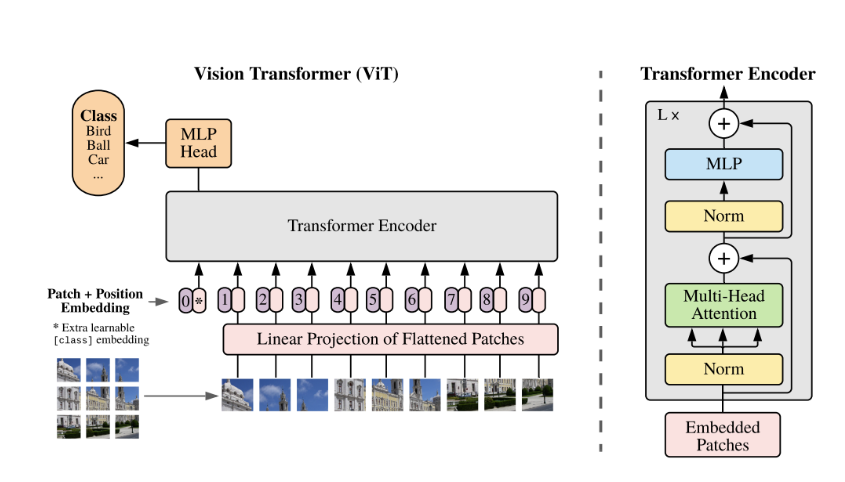
Vision Trnasformer는 기본적으로 Trnasformer의 Encoder를 가져와서 사용한다. 그렇기에 Transformer에 맞는 입력값을 그대로 가져와서 사용한다.
입력 데이터 만드는 과정
- 이미지를 패치 단위로 나누어 좌측 상단부터 우측하단까지의 순서로 데이터를 생성
- 각각의 패치를 flatten을 하여 벡터로 변환
- 각각의 벡터에 Linear 연산을 거쳐서 Embedding 작업
- Embedding 된 결과 앞에 class token을 하나 추가
- Positional Embeeding을 더해준다.
위 구조에서의 Multihead Attention은 Self Attention(query, key, value가 모두 같음)을 사용하였다. 인코더에서 나온 출력물은 MLP head에서 Class token만을 사용한다. 즉, 최종 output이 나왔을때 이미지에 대한 1차원 representation vector로써의 역할을 수행한다.
