저번 장에서는 신경망을 배웠으니 이번 장에서는 신경망을 학습 시켜볼 것이다.
이번 장의 목표는 신경망이 학습할 수 있도록 해주는 지표인 손실 함수를 알아볼 것이고, 이 손실 함수의 결과 값을 가장 작게 만드는 가중치 매개변수를 찾는 학습을 할 것이다.
Chapter 4
기계학습(machine learning)이란?
흔히 머신러닝으로 알려져 있다. 머신러닝은 데이터가 생명이다. 데이터에서 패턴을 발견하고 데이터로 이야기를 만들기에 머신러닝의 중심에는 데이터가 존재한다. 보통 어떤 문제를 해결하려고 할 때 사람은 경험과 직관을 단서로 시행착오를 거듭하여 진행을 한다. 그러나, 머신러닝은 사람의 개입을 최소화하고 수집한 데이터로부터 패턴을 찾으려 시도한다. 머신러닝에서는 모아진 데이터로부터 규칙을 찾아내는 역할을 '기계'가 한다. 그러나, 이미지를 벡터로 변환할 때 사용하는 특징은 여전히 '사람'이 설계한다. 그러나 신경망(딥러닝)에서는 이미지에 포함된 중요한 특징까지도 '기계'가 스스로 학습을 한다.

우선 머신러닝에서는 훈련 데이터와 시험 데이터로 나눠 학습과 실험을 수행하는 것이 일반적이다.
훈련 데이터만을 사용하여 학습하면서 최적의 매개변수를 찾는다. 그 후 시험 데이터를 비교한다. 범용 능력을 평가하기 위해 훈련 데이터와 시험 데이터를 분리한다.
범용능력 : 아직 보지 못한 데이터로도 문제를 올바르게 풀어내는 능력이다.
범용능력이 곧, 머신러닝의 최종 목표이다. 그러나, 한 데이터에만 지나치게 최적화 되는 오버피팅을 피하는 것 또한 머신러닝의 목표이다.
손실함수
신경망에서 최적의 매개변수 값을 찾기 위해 사용하는 지표를 손실 함수라고 한다.
오차제곱합(sum of squares for error, SSE)
가장 많이 쓰이는 손실 함수이다.
y는 신경망의 출력, t는 정답 레이블, k는 데이터의 차원 수를 말한다.
def sum_squares_error(y, t):
return 0.5 * np.sum((y-t)**2)교차 엔트로피 오차(cross entropy error, CEE)
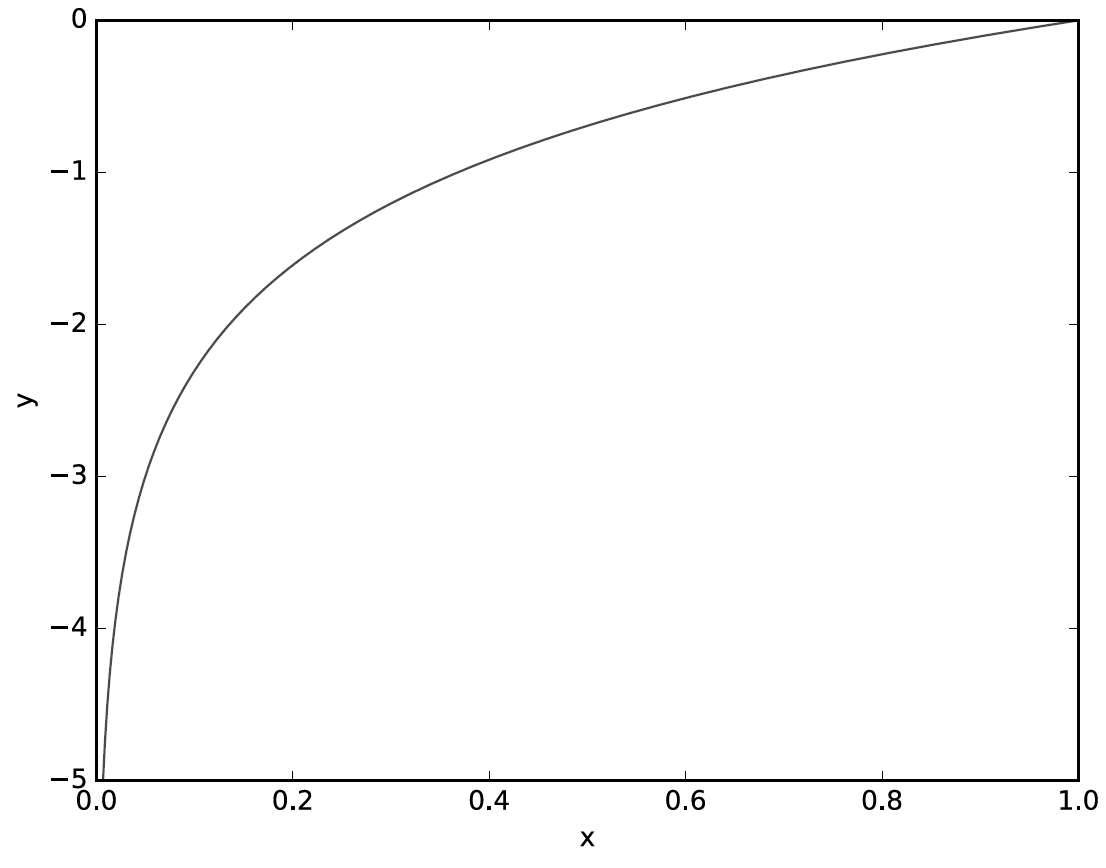
교차 엔트로피의 오차는 정답일 때의 출력이 전체 값을 정한다.
아래 그림에서 보듯이 정답에 해당하는 출력이 커질수록 0에 다가가다가, 그 출력이 1일 때 0이된다.
즉, 정답일 때의 출력이 작아질수록 오차는 커진다.
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))
# 배치를 고려한 교차엔트로피
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7) / batch_size
미니배치 학습
수식이 복잡해 보이지만, 데이터 하나에 대한 손실 함수인것을 단순히 확장했을 뿐이다. 마지막에 N으로 나누어서 정규화하고 있다. 나눔으로써, 평균 손실 함수를 구하게 된 것이다. 이렇게 평균을 구하게 되면 훈련 데이터 개수와 상관없이 언제든 통일된 지표를 얻게 된다. 그러나, 훈련데이터가 많을 경우 그 합을 구하기 위해서는 시간이 좀 걸린다. 그래서 그걸 해결하는 방안으로 일부 데이터를 추려 근사치를 구하는 것인데 신경망에서는 훈련데이터로부터 일부만 골라내는데 이걸 미니배치라고 한다.
import numpy as np
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = load_mnist(normalize = True, one_hot_label = True)
print(x_train.shape) # (60000, 784)
print(t_train.shape) # (60000, 10)
train_size = x_train.shape[0]
batch_size = 10
batch_mask = np.random.choice(train_size, batch_size) #60000장 10개 랜덤
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
손실함수를 왜 설정할까?
신경망 학습에서는 최적의 매개변수(가중치와 편향)를 탐색할 때 손실 함수의 값을 가능한 한 작게 하는 매개변수 값을 찾는다. 이때 매개변수의 미분(기울기)을 계산하고, 그 미분 값을 단서로 매개변수의 값을 서서히 갱신하는 과정을 반복한다.
신경망을 학습할 때 정확도를 지표로 삼아서는 안 된다. 정확도를 지표로 하면 매개변수의 미분이 대부분의 장소에서 0이 되기 때문이다.
정확도는 매개변수의 미소한 변화에는 거의 반응을 보이지 않고, 반응이 있더라도 그 값이 불연속적으로 갑자기 변화를 한다. 신경망 학습에서 중요한 성질은 기울기가 0이 되지 않게해야 신경망이 올바르게 학습을 할 수 있다. 이런 이유로 앞의 포스팅에서 시그모이드 함수일 때 매끈함의 중요하다고 한 것같다.
수치 미분(numerical differentiation)
단순한 차분을 이용하면 오차가 발생하게 된다. 그러므로, 이 오차를 줄이기 위해 이 책에서는 중심 차분을 사용하였다.
def numerical_diff(f, x):
h = 1e-4 # 0.0001
return (f(x+h) - f(x-h)) / (2*h)경사법
경사 하강법: 기울기를 잘 활용해 함수의 최솟값(가능한 작은값)을 찾는법
경상 상승법: 기울기를 잘 활용해 함수의 최댓값(가능한 큰값)을 찾는법
η기호는 갱신하는 양을 의미한다. 이를 신경망학습에서는 학습률이라고 한다.
def gradient_descent(f, init_x, lr = 0.01, step_num = 100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x