저번 포스팅에서 퍼셉트론에 대해서 설명했다. 퍼셉트론은 복잡한 함수를 표현을 할 수 있지만, 가중치를 결정할 때 여전히 사람이 수동으로 정한다. 이것을 해결 해주는 것이 신경망이다.
그러니 이번 장에서 신경망에 대해서 알아보자.
Chapter 3
신경망이란?

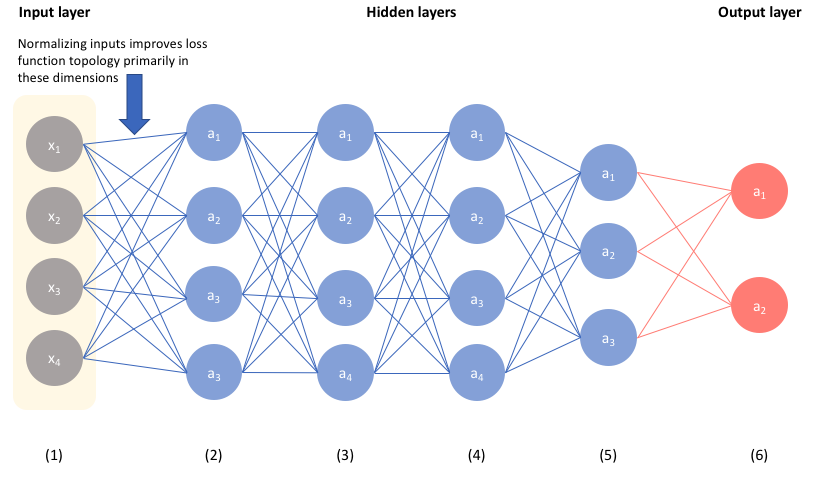
위의 보이는 사진은 신경망을 그림으로 나타낸 것이다.
앞에서 부터 0층으로 시작하면
0층 : 입력층
1층 : 은닉층
2층 : 출력층
이렇게 구성이된다.
활성화 함수 (activation function)
이 함수는 입력 신호의 총합을 출력 신호로 변환하는 함수이다.
여기서 h를 활성화 함수라고 한다.
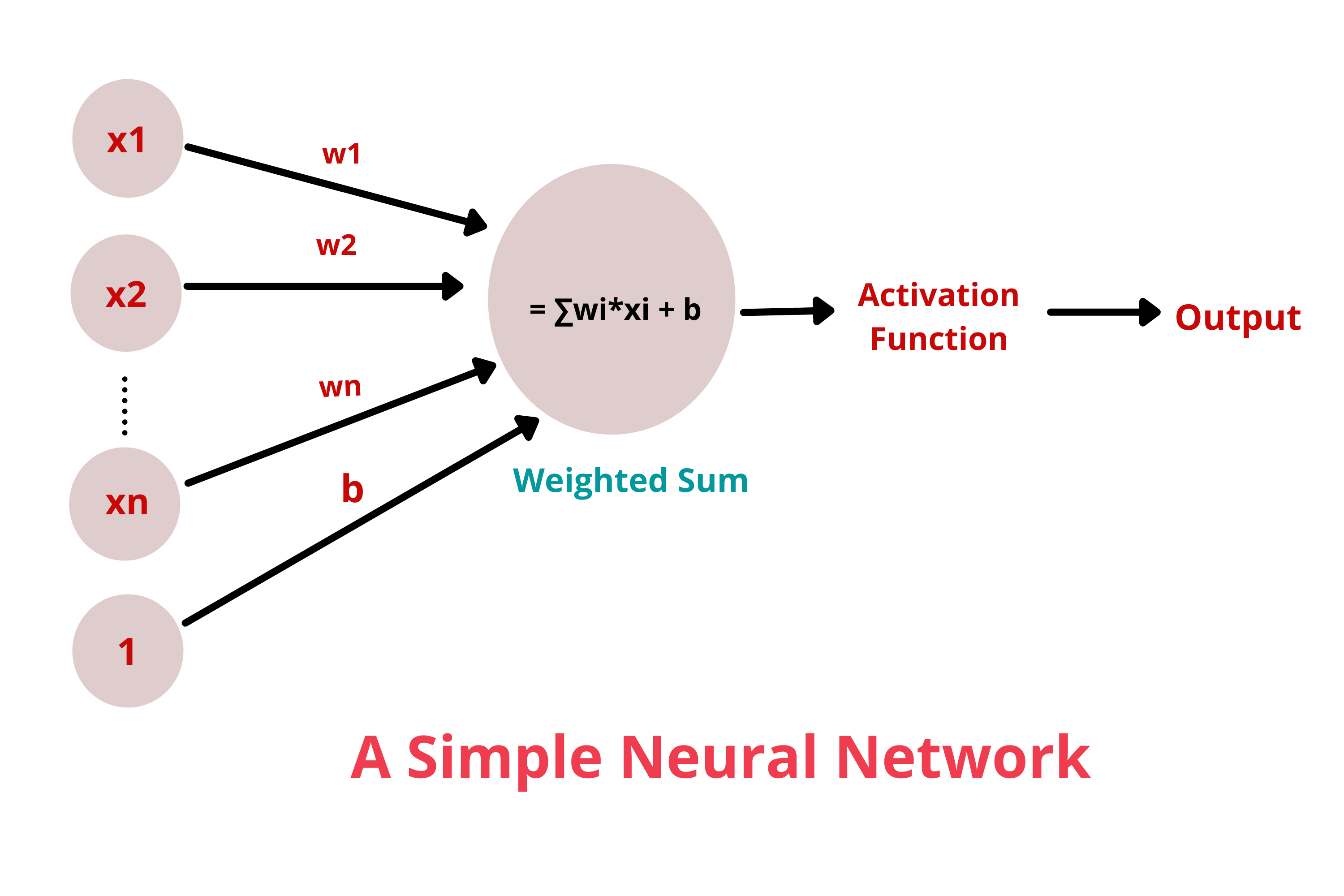
이런식으로 사용된다고 볼 수 있다.
퍼셉트론에서는 계단함수(step function)을 사용하지만 신경망에서는 주로 시그모이드함수(sigmoid function)을 사용한다.
sigmoid function

def sigmoid(x)
return 1/ (1+np.exp(-x))코드로 표현하면 이와 같다.
이 함수의 특징은 매끈함이다. 이것이 신경망 학습에서 아주 중요한 역할을 한다고 한다.
비선형 함수(non-linear function)
신경망에서는 활성화 함수로 비선형 함수를 사용하여야 한다. 이유는 선형 함수를 사용해버리면 층을 깊게 하는 의미가 없어지기 때문이다.
만약 h(x) = cx 라고 해버리면 h(h(h(x))) 는 결국, 곱셈을 3번한 함수가 되어버리기 때문에 은닉층이 없는 네트워크가 되버리기 때문이다. 이러한 이유로 신경망에서는 반드시 비선형 함수를 사용하여야 한다.
ReLU 함수 (Rectified Linear Unit)
최근에는 Relu함수를 주로 사용한다고 한다.
이 함수의 특징은 입력이 0을 넣으면 그 입력을 그대로 출력하고, 0 이하이면 0을 출력하는 함수이다.

def relu(x):
return np.maximum(0,x)출력층 설계
신경망은 분류와 회귀 모두에 이용된다. 다만 둘 중 어떤 문제냐에 따라, 출력층에서 사용하는 활성화 함수가 달라진다. 일반적으로 회귀에는 항등 함수를, 분류에는 소프트맥스 함수를 사용한다.
분류(classification) : 데이터가 어느 클래스에 속하느냐의 문제(사진 속 인물의 성별을 분류하는 문제)
회귀(regression) : 입력 데이터에서 수치를 예측하는 문제
항등함수(identity function)
입력을 그대로 출력하는 함수를 말한다.
소프트맥스 함수(softmax function)

분류에서는 소프트맥스 함수를 주로 사용한다. 분모를 보면 모든 입력에 영향을 받는다는 것을 알 수 있고, 그림을 보아도 알 수 있다. 출력층의 각 뉴런이 모든 입력신호에 영향을 받는다는 뜻이다. 그러나 이것을 코드로 표현하면 문제가 생긴다. 분자와 분모가 너무 큰 값이면 표현을 할 수 없게 된다.
위 식을 코드로 표현하면 아래와 같다.
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) #오버플로 대책
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y소프트맥스 함수의 출력은 0에서 1.0 사이의 실수이다. 또한, 소프트맥스 함수 출력의 총합은 1이 된다. 이 성질 덕분에 소프트맥스 함수의 출력을 '확률'로 해석할 수 있다. 소프트맥스 함수를 적용시켜도 각 원소의 대소 관계는 변하지 않는다. 결과적으로 신경망으로 분류할 때는 출력층의 소프트맥스 함수를 생략해도 된다. 이에 대해서는 4장에서 좀 더 알아가보자.
손글씨 숫자 인식
MNIST 데이터셋
이 데이터셋은 기계학습분야에서 아주 유명한 데이터셋이고, 아주 다양한 분야에서 실험용 데이터로 자주 쓰인다.
배치(batch)
배치는 하나로 묶은 입력데이터이다. 예를 들어 784(28x28)크기의 이미지가 데이터로 784개의 뉴런에 입력되면 출력에는 10개의 뉴런이 반응하고 이것이 100장 쌓이면 100x784의 입력 데이터 구조가 나온다. 여기서 100을 배치라고 한다.
배치 처리의 특징
- 수치 계산 라이브러리 대부분이 큰 배열을 효율적으로 처리할 수 있도록 고도로 최적화되어 있기 때문에 이미지 1장당 처리 시간을 대폭 줄여준다.
- 커다란 신경망에서는 데이터 전송이 병목으로 작용하는 경우가 자주 있는데, 배치 처리를 함으로써 버스에 주는 부하를 줄인다.(정확히는 느린 I/O를 통해 데이터를 읽는 횟수가 줄어, 빠른 CPU나 GPU로 순수 계산을 수행하는 비율이 높아진다.)
