Abstract
2010년 ImageNet LSVRC 대회에서 약 120만의 이미지에 대해서 1000개의 클래스로 분류하기 위해 본 논문의 저자는 Deep Convolutional Neural Network를 학습했다고 한다. 여기서 Deep Convolutional Neural Network는 AlexNet을 의미한다.
Test 셋 환경에서 성능 평가를 한 결과, top-1과 top-5 error ratio는 각각 37.5%와 17.0%를 기록했으며 이는 이전 SOTA의 기록보다 훨씬 좋은 성능을 보였다.
모델은 약 6000만개의 파라미터와 65만개의 뉴런을 가지며, 5개의 CNN(Convolutional Layer)과 Max Pooling의 조합 그리고 3개의 FC(Fully-Connected) Layer와 1000개의 클래스를 구분하기 위한 Softmax로 구성되어있다.
학습을 빠르게하기 위해 비포화 뉴런과 Convolution Operation을 GPU로 구현했다. 한편, 과적합(Overfitting)을 피하기 위해 FC Layer에 대해서 Dropout을 적용했다.
최종적으로 ILSVRC 2012에서 top-5 error 15.3%로 두번째 기록인 26.2%보다 큰 차이로 우승했다.
1. Introduction
최근까지는 레이블된 데이터 수는 이미지에 비해 상대적으로 적었다. 물론 비교적 간단한 Recognition Task들은 적은 데이터셋에 대해서 Augmentation을 통해 해결될 수 있다. 예를 들어, Mnist 숫자 Recogntion Task가 그 경우이다. 하지만, 현실의 객체들은 상당한 가변성을 나타내기때문에 더 큰 데이터 셋으로부터 학습이 필요하다. 그리고 실제로 적은 데이터 셋의 단점은 계속 인식되어왔지만 최근에서야 수백만의 레이블된 이미지 데이터 셋이 생겨났다.
수백만의 이미지에 존재하는 수천개의 객체들을 학습하려면 큰 수용성(Capacity)을 가지는 모델이 필요하다. 하지만, Object Recognition Task의 엄청난 복잡성은 ImageNet과 같은 큰 데이터 셋으로도 해결하기 힘들기 때문에 모델은 우리가 가지고 있지않은 데이터들에 대해서 대응할 수 있도록 사전 지식을 학습해야 된다. Convolutional Neural Networks(CNNs)은 다양한 깊이와 너비를 통해 Capacity를 조절할 수 있고, 이미지의 특성(통계의 정상성, 픽셀의 지역성)을 강력하고 정확하게 가정(추정)함으로써 이를 만족 할 수 있다. 기존의 비슷한 사이즈를 가지는 FeedForward Neural Network와 비교했을때, CNN은 더 적은 연결과 파라미터를 가지면서 쉽게 학습을 할 수 있고, 이론적으로는 CNN의 최적 성능은 약간 나빠질 수도 있다.
CNN의 좋은 성능에도 불구하고, 여전히 고화질의 큰 이미지 데이터셋에 적용하기에는 무리가 있다. 최근 운이 좋게도 GPU가 2D Convolution의 최적화된 구현과 함께 사용할 수 있게되면서 큰 스케일의 CNN 학습이 가능해지고, ImageNet과 같이 많은 레이블 데이터를 포함한 최근 데이터 셋을 대상으로 과적합 없이 모델을 학습할 수 있게 되었다.
이 논문의 기여는 다음과 같다.
ILSVRC 2010, ILSVRC 2012에 사용된 ImageNet으로부터 Large CNN을 학습했고, 최고의 성능을 얻었다. 고도로 최적화된 2D Convolution 연산의 GPU 구현과 CNN을 학습하기 위한 이외의 연산들은 구현했다. 이외에도 성능과 학습 시간을 줄일 수 있는 새로운 방법과 과적합을 막을 수 있는 방법을 제안했다. 마지막으로, Convolution Layer와 Fully Connected Layer로 구성된 제안하는 모델에 있어서 깊이가 중요하다는 것을 알게 되었다.(Convolution Layer를 삭제해보니 성능이 떨어지는 것을 확인)
2. The Dataset
ImageNet은 약 1500만 개의 고화질 이미지 데이터 셋이며, 약 2만 2천개의 rough한 클래스를 포함한다. ILSVRC에서는 약 1000개의 이미지와 1000개의 클래스를 포함한 ImageNet의 서브 데이터 셋을 활용했다. 전체적으로는 약 120만 장의 Train 이미지와 약 5만 장의 Validation 이미지 그리고 약 15만 장의 Test 이미지들로 구성되어있다.
ILSVRC 2010은 유일하게 Test Set에 Label이 포함되어 있기 때문에 주로 연구에 사용되었고, ILSVRC 2012는 Test Set에 Label이 포함되어 있지 않기 때문에 결과만 제시했다. ImageNet에선 평가지표로 주로 top-1과 top-5 error를 사용했기 때문에 동일하게 사용했다.
ImageNet에는 다양한 해상도를 가진 이미지들이 존재하지만, AlexNet은 고정된 크기의 입력을 받기 때문에 256x256 크기로 Down Sample했다. Down Sample 방식은 width와 height중에서 짧은 부분을 256 크기로 resize한 뒤, 256x256 크기로 Crop하는 방법을 사용했다. 전처리는 각 픽셀에 대해서 평균값을 빼주는 것 외에는 따로 추가하지 않았다.
3. The Architecture

모델은 위와 같이 5개의 Convolution Layer와 3개의 Fully Connected Layer로 구성되어있고, 논문에서는 2개의 GPU를 통한 학습 과정을 묘사하고 있다.
3.1 ReLU Nonlinearity
Gradient Descent에 의한 학습 과정에 있어서 Tanh나 Sigmoid와 같이 비선형성을 포화하시키는 Function은 ReLU와 같이 비포화시키는 Function보다 시간이 오래 소요된다.
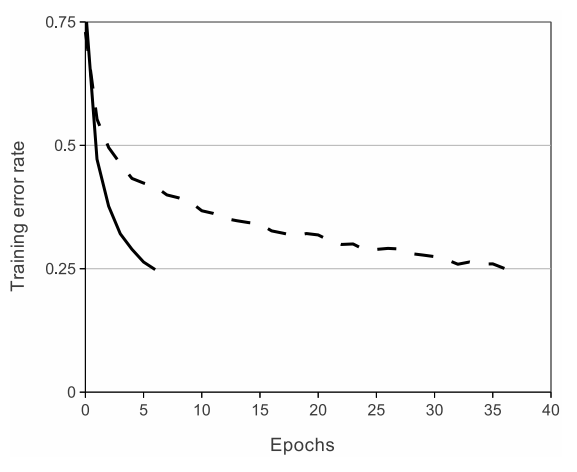
CIFAR-10 Dataset을 대상으로 성능을 비교한 결과, 4개의 Convolution Layer를 가지는 구조로부터 ReLU는 Tanh Function에 비해 25% Error를 가지기까지 훨씬 적은 Epoch 즉, 적은 학습 시간이 소요되었다. 이에 따라 포화 함수로는 Large Model을 학습시키기 어렵다는 것을 알 수 있다.
한편, 기존에는 Jarrettet가 Local Average Pooling에 이어서 의 대조 정규화를 적용했을 때 Caltech-101 Dataset에서 부분적으로 좋은 성능을 보였다고 했다. 하지만, 이 데이터셋의 주 목적은 과적합을 막는 것이었기 때문에 학습 속도와는 서로 무관하다고 저자는 주장했다.
3.2 Training on Multiple GPUs
약 120만 개의 Train Set을 Single Gpu로 학습하기에는 무리이므로 저자는 3GB의 Vram을 가지는 Gtx 580을 2개 사용했고, 모델 Network를 두 GPU로 펼쳐서 학습했다. 최근 GPU들은 다른 GPU로부터 직접 읽고 쓰기가 가능하기 때문에 병렬 처리에 적합하다.
병렬화 구조는 각 GPU에 절반의 Kernel 혹은 뉴런을 할당했고, 특정 Layer에서만 GPU 통신을 하는 트릭을 사용했다. 이 트릭은 위의 Figure 2를 보면, Layer 4는 동일한 GPU로부터 계산된 Layer 3의 결과를 입력으로 받는 것처럼 통신에 드는 통신 비용을 줄일 수 있게 된다.
결과적으로 제안하는 모델의 구조는 "columnar" CNN 구조와 비슷하지만, 각 열이 독립적이지 않다는 점이 다르다. Multi GPU를 사용한 효과로 top-1, top-5의 Error Rate를 줄일 수 있었고, 학습 시간 또한 Single GPU에 비해 감소되었다.
3.3 Local Response Normalization
ReLU는 입력 데이터들을 포화되도록 정규화가 필요하지 않는 장점이 있다. 하지만, 저자는 여전히 Local Normalization 구조가 일반화를 돕는다고 주장했다.
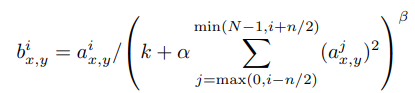
여기서, aix,y는 kernel i를 적용하고, ReLU를 적용한 (x,y) 위치의 결과 값을 의미한다. 그리고 N은 Layer에 존재하는 전체 커널 수를 의미하고, n은 인접한 kernel을 의미한다. , , , 는 하이퍼 파라미터이며, 본 논문에서는 각각 2, 5, 1e-4, 0.75의 값을 사용했다.
이러한 종류의 Response Normalization은 실제 뉴런에서 발견되는 Lateral Inhibition 효과를 통해 일반화 관점에서 유리하다.
결과적으로 top-1, top-5 Error Rate를 약 1.4%, 1.2% 감소 시켰고, CIFAR-10에 대해서도 13%의 기존 결과에 대해서 Normalization을 적용한 결과 11%의 Test Error Rate를 얻었다.
3.4 Overlapping Pooling
기존에는 Adjacent Pooling에 의해 요약된 이웃값들은 서로 겹치지 않는다. 좀 더 정확하게는 Pooling Layer는 s 픽셀 간격으로 구성된 그리드로 생각할 수 있으며, 각 위치를 중심으로 zxz의 이웃을 요약한다. 여기서 s=z인 경우가 기존의 CNN에서 주로 사용되는 Local Pooling을 의미한다. 그리고 s<z인 경우가 Overlapping Pooling을 의미한다. 본 논문에서는 s=2, z=3을 사용했다.
결과적으로 s=2, z=2의 Local Pooling 기법에 비해 top-1과 top-5 error를 약 0.4%, 0.3% 감소시켰고, 학습하는 과정에 있어서 Overlapping Pooling이 과적합을 막는데 유리하다.
3.5 Overall Architecture
Response Normalization Layer는 Convolution Layer 1, 2이후에 적용된다. 3.4에서 언급한 Max Pooling Layer는 Response Normalization과 같이 적용되고 추가적으로 Convolution Layer 5에도 적용된다. ReLU Function은 모든 Convolution Layer와 FC Layer에 적용된다.
모델 구조는 다음과 같다.
Input : 256x256x3
Input_Augmentation : 227x227x3
Layer 1 : Conv(11x11x3), Kernel 96, Stride 4 -> ReLU, LRN, Pooling -> 27x27x96
Layer 2 : Conv(5x5x48), Kernel 256 -> ReLU, LRN, Pooling -> 13x13x256
Layer 3 : Conv(3x3x256), Kernel 384 -> ReLU -> 13x13x384
Layer 4 : Conv(3x3x192), Kernel 384 -> ReLU -> 13x13x384
Layer 5 : Conv(3x3x192), Kernel 256 -> ReLU, Pooling -> 6x6x256
Layer 6 : Flatten -> FC Layer 4096 -> ReLU -> 4096
Layer 7 : FC Layer 4096 -> ReLU -> 4096
Layer 8 : FC Layer 1000 -> ReLU, Softmax -> 1000
Output : 1000여기서, Pooling Layer를 거친 뒤 width, height Size가 줄어든 이유는 Pooling의 Grid 사이즈(s)가 2이기 때문이다.
4. Reducing Overfitting
제안하는 모델은 약 6000만 개의 파라미터를 가진다. 이는 과적합없이 수많은 파라미터를 학습하기 어렵게 한다. 본 논문에서는 과적합을 제어하기 위해 두 가지 방법을 제안한다.
4.1 Data Augmentation
이미지 데이터를 대상으로 과적합을 줄이기 위한 가장 쉽고 일반적인 방법은 레이블은 유지한 채 Transformation을 통한 데이터 셋 확장이다. 본 논문에서는 원본 이미지로부터 적은 연산을 사용하여 Disk에 메모리가 저장될 필요가 없는 두 가지 방법을 제안한다. GPU가 이전 Batch에 대해서 학습하고 있는동안, CPU가 Augmentation 연산을 수행하기 때문에 Data Augmentation 구조는 연산적으로 비용이 들지 않게 된다.
첫번째 Data Augmentation은 이미지 변환과 수평 반사이다. 먼저, 256x256의 이미지로부터 랜덤으로 224x224 patch와 수평 반사를 추출하고, 모델을 통해 학습한다. 이 방법으로 Train Dataset을 약 2048배로 확장할 수 있었다. 이 방법이 없으면 논문에서 제안한 모델은 상당히 과적합으로 부터 어려움을 겪게 되고, 더 작은 네트워크에선 이러한 방법이 거의 필수이다. Test시에는 224x224 patch를 랜덤으로 5개 추출하고, 이에 대한 수평 반사를 포함하여 총 10개의 patch 모음에 대한 추론 결과를 평균을 통해 구한다.
두번째 Data Augmentation은 Train 이미지의 RGB 채널 강도를 변경하는 것이다. 구체적으로 ImageNet Train Dataset의 RGB Pixel에 대해서 PCA를 수행한다. 고윳값에 평균이 0이고 표준편차가 0.1인 가우시안에서 추출한 확률 변수를 곱한 값에 비례한 크기를 가지는 주성분을 각 Train 이미지에 추가한다. 이 방법은 이미지의 주요 특징, 즉 조명의 색과 강도의 변화에 불변인 객체 정체성을 잘 찾아낸다. 이 방법을 통해 top-1 Error를 1% 감소시켰다.
4.2 Dropout
추론시에 많은 다른 모델의 추론 결과를 합침으로써 Error를 줄일 수 있지만, 학습시키는데 몇일이 소요되는 큰 모델에 대해서는 비용이 비싸다. 이에따라 학습하는 과정에서 효과적으로 적용할 수 있는 최근 소개된 "dropout"이라 방법을 적용한다. 이 방법은 뉴런의 출력을 50%의 가능성으로 0으로 만드는 것이고, forward pass에 기여하지 않고 back propagation에 참여하지 않는다. 이에 따라 input은 계속해서 존재하고, 파라미터를 공유하는 다른 구조의 Neural Network를 만들어낸다. 이 기술은 서로 다른 뉴런의 존재에 기댈수 없게 하면서, 뉴런의 복잡한 공동 적응을 줄인다. 따라서, 다른 뉴런의 다양한 무작위 하위 집합과 함께 유용한 robust feature들을 더 학습하도록 한다. Test시에는 모든 뉴런을 사용하지만, 출력에 dropout 네트워크에서 생성된 기하급수적으로 많은 예측 분포의 기하 평균을 취하는 합리적인 근사치인 0.5를 곱한다. dropout을 사용하지 않으면, 제안하는 모델은 상당히 과적합을 겪게 된다. dropout은 제안하는 모델의 앞에서 두 FC Layer에 사용되었다.
5. Details of learning
저자는 128 batch Size, 0.9 momentum, 0.0005 weight decay를 가지는 SGD(Stochastic Gradient Descent)를 적용했다. 저자는 여기서 weight decay가 학습하는데에 있어서 단순하게 Regularization 역할만 하는 것이 아니라 Error를 감소시키는 역할을 수행한다고 주장했다.
평균이 0이고, 표준편차가 0.01인 가우시안 분포를 통해 각 layer의 가중치를 초기화시켰다. 편향의 경우, Convolution Layer 2, 4, 5와 FC Layer에 대해서 1로 초기화하였다. 다른 Layer의 경우는 0으로 초기화하였고, 이는 ReLU에 양의 입력값을 줌으로써 학습의 초기단계를 가속화하였다.
학습률은 모든 Layer에 대해서 동일하게 적용하고, 학습하는 과정에 수동으로 조절했다. 학습률은 0.01로 초기화했다. 약 120만장의 이미지로부터 5-6일 동안 대략 90번정도 반복하여 학습했다.
6. Results
ILSVCR 2010의 test set에 대해서 top-1, top-5 error를 각각 37.5%와 17.0%를 달성했다. ILSVRC 2012의 test set의 Label은 공개되어있지 않다. 단, 본 논문은 대회에 제출한 Test Set과 Validation Set를 비교했을때 경험적으로 적은 차이가 나는 것을 알 수 있으므로 교환해서 사용했다. 논문에서 제안한 CNN Model의 경우 18.2%의 top-5 error를 보였다. 한편, 5개의 CNN에 대해서 추론 결과를 Average한 경우는 약 16.4%를 보였다. 그리고 6개의 Convolutional Layer와 Pooling Layer로 구성된 모델에 대해서 ImageNet Fall 2011를 대상으로 pretrain후에 ILSVRC 2012에 대해서 fine tuning 성능평가한 결과 Single Model임에도 불구하고 16.6%의 error rate를 얻을 수 있었다.
6.1 Qulitative Evaluations

Figure 3은 네트워크의 두 데이터 연결 계층에 의해 학습된 Convolutional Kernel을 보여준다. 여기서 네트워크는 다양한 주파수 및 방향 선택 커널과 다양한 colored blob들을 학습했다. GPU 1의 Kernel은 주로 색에 구애받지 않았고, 이에 반해 GPU 2의 Kernel은 색에 따라 다르다는 것을 알 수 있다.

Figure 4는 모델의 정성적 평가를 보여준다. 먼저, 진드기와 같이 중앙에 떨어진 객체라도 인식할 수 있는 것을 알 수 있다. 그리고 leopard의 경우를 보면 다른 고양이 종류에 대해서 고려되는 것을 보면, top-5 label들이 합리적인 결과라는 것을 알 수 있다. 하지만, 일부는 사진의 의도된 초점에 대해 모호성이 존재한다.
네트워크의 시각적 지식에 대한 증명을 하는 또 다른 방법은 Feature를 이용하는 것이다. 여기서는 4096 차원의 은닉층에 생성된 feature를 의미한다. 만약 두 이미지의 feature에 대한 유클리디안 거리가 작다면, 우리는 두 이미지가 서로 유사하다고 할 수 있다. Figure 4의 우측 이미지들은 가장 왼쪽의 이미지와 위의 방법을 통해 얻은 가장 근접한 유클리디안 거리를 가진 이미지들을 추출한 결과이다.
유클리디안 거리법을 통해 4096 차원의 실제 벡터 값을 계산하는 것은 효율적이지 않다. 이에 대해 feature 벡터로부터 이진 코드를 생성하는 auto encoder를 이용한다면 효율적으로 해결할 수 있다.
7. Discussion
본 논문의 연구는 Large, Deep Convolutional Network가 어려운 Dataset을 대상으로 지도 학습을 통해 기록을 달성할 수 있었음을 보여준다. 한편, 하나의 Convolutional Layer라도 제거되면 성능이 많이 떨어진다는 점을 주의해야한다.
궁극적으로 본 논문은 시간 구조가 정적인 이미지에서는 누락되거나 훨씬 덜 분명하지만, 매우 유용한 정보를 제공하는 비디오 시퀀스에 대해서 매우 크고 깊은 Convolution Network를 사용하는 것을 목표로 한다.

Vision AI Engineer