Hierarchical Multi-Scale Attention for Semantic Segmentation
Abstract
Multi-Scale Inference는 Semantic Segmentation의 결과를 개선하기 위해 일반적으로 사용된다. 그리고 여러 이미지 스케일의 출력 결과에 대해서 Max Pooling이나 Average Pooling을 적용한다. 이 논문에서는 이 작업을 Attention 기반 접근 방식을 통해 해결하고자 한다.
이 논문의 저자는 부분적으로 특정 스케일로 추론한 결과가 더 좋으며, 제안하는 Network가 이러한 정도를 학습할 수 있음을 주장한다. 또한, 제안하는 Attention Mechanism은 다른 최신 기법에 비해 약 4배의 메모리 효율을 가질 수 있다고 한다. 게다가 더 빠른 속도로 학습을 할 수 있고, 더 큰 사이즈로 Crop하여 모델의 정확도를 올릴 수 있다고 한다.
본 논문은 CityScapes와 Mapillary Vistas Dataset으로 연구를 진행했고, 특히 CityScapes는 Coarse한 Labeling을 제공하므로 Auto Labeling 기법을 통해 일반화를 개선시켰다.
최종적으로 Mapillary에선 61.1 IOU와 CityScapes에선 85.1IOU를 얻으면서 Sota를 달성했다.
1. Introduction
Semantic Segmentation 작업은 특정 대상에 따라 낮은 해상도에서 더 잘 처리되거나, 높은 해상도에서 더 잘 처리되기도 한다. 이 현상을 Class Confusion이라고 한다.
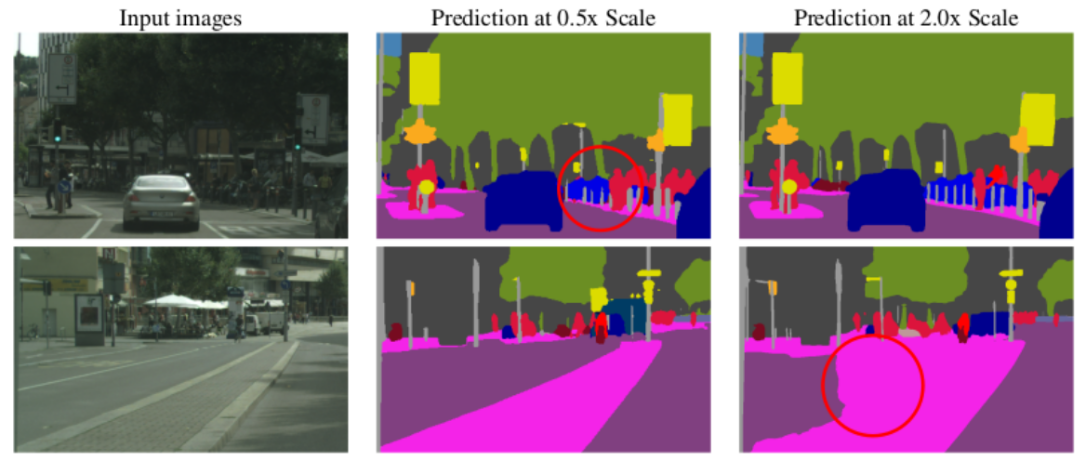
위의 그림은 스케일에 따른 Semantic Segmentation 실패 예시이다. 그림에서 0.5 Scale의 추론은 얇은 포스트를 잘 탐지하지 못하고, 2.0 Scale은 큰 도로 영역을 잘 탐지하지 못한다.
일반적으로 이러한 Class Confusion을 해결하기 위해 기존에는 Pooling Layer를 주로 사용했다. 하지만, Pooling Layer의 경우 Multi-Scale의 추론 결과를 평균내거나 특정 스케일의 결과 하나만을 사용하기만 할뿐이지 Multi-Scale의 추론 결과를 가중치 조합으로 최적 결과를 얻을 순 없다.
이 문제를 해결하기 위해 본 논문 저자는 Scale간의 상대적 가중치를 예측하는 Attention Mechanism을 제안했다. 기존의 Attention Mechanism인 Explicit Method은 추론중에 다른 Scale을 추가하려면 새로 학습해야하는 문제점이 있지만, 제안하는 Hierarchical Method는 구조적 특성으로 재사용이 가능하다. 또한 (0.5, 1.0, 2.0)의 Multi-Scale을 학습하는 경우, Explicit Method는 약 4.25배의 추가 Train Cost가 발생하지만 Hierarchical Method는 약 0.25배의 추가 Train Cost만이 필요하므로 연산 측면에서 더 유리하다.
한편, CityScapes의 Coarse Label을 해결하기위해 Auto Labeling을 적용했고, 메모리와 Dist I/O Cost 부담을 줄이기 위해 Soft Labeling이 아닌 Hard Labeling을 적용했다.
2. Related Work
Multi-Scale Context Methods
최근 Semantic Segmentation Network는 낮은 Output Stride를 주로 사용하는데, 이는 미세한 특징을 잘 얻을 수 있지만, Receptive Field를 축소시키게 된다. 이를 해결하기 위해 PSPNet은 여러 Pooling Layer와 Convolution 연산을 통해 얻은 Feature를 여러 Scale로 조합하는 Spatial Pyramid Pooling을 제안했다. 그리고 DeepLab에서는 여러 레벨의 dilation을 적용한 atrous convolution 연산을 포함한 ASPP(Atrous Spatial Pyramid Polling)을 사용하여 조금 더 세밀한 Feature를 얻는다. 이외에도 최근 ZigZagNet과 ACNet은 Trunk의 마지막 Feature가 아닌 중간 Feature를 활용하여 Multi-Scale Context를 생성했다.
Relational Context Methods
Pooling이나 Dilation은 전형적으로 Pyramid Pooling은 대칭 방식으로 사용되기 때문에 Pyramid Pooling은 고정된 정사각형 Context 영역에 주의를 기울인다. 또한, 이러한 기술들은 정적이고 학습되지 않는 경향이 있다. 이에 반해 Relational Context Method는 픽셀간의 관계에 주의하여 Context를 구축하므로 정사각형 영역에 구속되지 않는다. 학습된 Relational Context Method를 통해 이미지 구성을 기반으로 Context를 구축할 수 있다. 이와 관련된 모델은 OCRNet, DANET, DANET, CFNET, OCNet 등이 있다.
Multi Scale Inference
Relational Context Methods나 Multi-Scale Context Methods들은 최고의 결과를 얻기 위해 Multi-Scale 평가를 사용한다. 기존에는 Multi-Scale의 결과를 합치기 위해 주로 Average Pooling이나 Max Pooling을 사용하고 특히 Average Pooling이 일반적으로 더 사용된다. 하지만, Average Pooling의 경우는 동일하게 Multi-Scale의 결과를 합치는 차선책이다. 이 문제를 해결하기 위해 기존에는 Attention Mechanism을 Multi-Scale의 결과를 합치기 위해 사용했다. Chen은 Network의 마지막 Feature를 통해 Attention Head를 전체 Scale에 대해서 동시에 학습시켰다. Chen이 특정 Layer에서 Attention을 사용한 반면에 Yang은 다른 Network Layer에서 Feature들의 조합으로 학습시켰다. 하지만, 이 두 방법 모두 고정된 Scale의 조합으로 학습된다는 문제가 있다. 만약, 추론시에 이 Scale의 조합이 아닌 다른 Scale을 사용하고 싶은 경우에는 새로 학습을 진행해야된다.
Auto Labeling
최근 CityScapes Dataset에 대해서 약 20,000개의 Coarse Label이 지정된 이미지를 그대로 활용했다. 하지만, 이미지 대부분 Coarse Label로 인해 Label이 지정되지 않는 문제점이 있다. 이를 해결하기 위해 본 논문의 저자는 Auto Labeling 방법을 제안하여 이미지의 전체 컨텐츠를 활용할 수 있도록 했다. 기존에는 주로 Soft Labeling 방법을 사용했지만, 저장 효율성과 Train 속도를 위해 본 논문은 Hard Labeling을 사용했다.
3. Hierarchical Multi Scale Attention
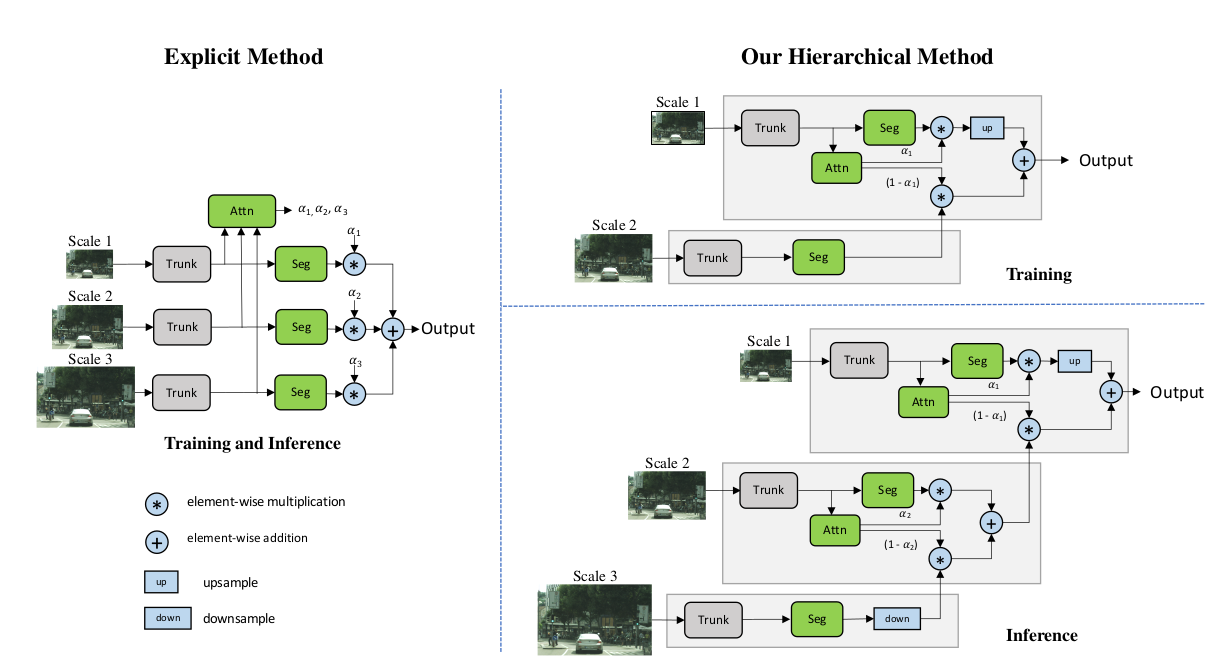
Chen의 방법을 Explicit Method로 명명한다. Explicit Method는 고정된 Scale 집합으로부터 Attention을 학습한다. 이에 반해, Hierarchical Method는 인접한 Scale간의 상대적인 Attention을 학습한다.
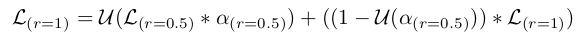
위의 수식은 학습하는 과정을 표현한 것이다. 여기서, r은 이미지 Scale을 의미하고, U는 upsampling을 의미한다. 즉, 0.5 Scale과 1.0 Scale에 대해서 학습한 Attention Head로부터 Attention Mask()를 구하고 각 추론 결과에 Pixel-Wise로 곱한 뒤 upsampling을 적용하여 최종 결과를 합치는 과정으로 진행된다.
추론시에는 Hierarchical Method는 서로 다른 N개의 Scale의 출력 결과를 합치기 위해 계층적으로 Attention을 적용하는데 이때, 낮은 Scale에게 우선순위를 줘서 상위 Scale까지 진행한다. 왜냐하면, 높은 Scale은 Global Context 정보를 더 가지고 있고, 정제될 필요가 있는 높은 Scale의 출력 결과로부터 출력을 선택할 수 있도록 하기 위해서다.
Hierarchical Method 구조로부터 크게 두가지 이점을 얻을 수 있다.
1. 추론을 할 때, Scale을 보다 유연하게 선택할 수 있다.
2. Train 효율성을 높일 수 있다.여기서, 논문에서는 연산량은 이미지 Scale2(=width x height)에 비례하다고 가정하고 Train Cost를 계산하여 비교했다.
3.1 모델 구조
본 논문에서 제안하는 모델의 구조는 크게 Trunk, Segmentation Head, Attention Head로 구성되어 있다. Trunk는 ablation 연구를 위해 ResNet-50 구조를 사용했으며, SOTA에선 HRNet-OCR 구조를 사용했다. Segmentation Head는 (3x3 conv, Batch Normalization, ReLU) 및 1x1 conv로 구성되어있고, Attention Head도 동일하다. 단, Attention Head는 Output 채널이 1이다.(클래스별 확률이 아닌 특정 Scale의 출력을 얼마나 사용할지에 대한 Attention 확률이므로)
3.2 분석

Mapillary Validation Set 환경에서 비교한 Multi-Scale Inference 비교 결과이다. 모델 구조는 DeepLabV3+를 사용했다. 표에 나와있는것처럼 Hierarchical Method가 Train 시간 및 연산 그리고 정확도 면에서 가장 높은 성능을 보였다. 특히, Average Pooling은 0.25 Scale을 추가함으로써 정확도가 떨어진 반면에 Hierarchical Method는 정확도가 향상되었고, 동일한 Eval Scales에 대해서 Explicit Method보다 적은 학습 연산 및 시간에 비해 높은 정확도를 달성했다.
한편, 본 논문에서는 학습시에 인접한 두 Scale의 Feature를 모두 사용하지 않고, 작은 Scale의 Feature만을 Attention Head를 학습하는데 사용했다.
4. Auto Labeling on CityScapes
본 논문은 CityScapes에 대해서 Auto Labeling을 적용한다. CityScapes는 약 20,000개의 Coarse Label이 지정된 이미지와 약 3,500개의 finely Labeled 이미지로 구성되어 있고, 이미지 품질이 매우 낮다.
기존 Soft Labeling은 Teacher Model로부터 구한 출력으로 각 픽셀마다 각 클래스 별 확률을 레이블링하는 방식인데, CityScapes에 대해서 적용할 경우 약 3.2TB의 저장소가 필요하다. 이에 반해, Hard Labeling은 Teacher Model로부터 구한 픽셀 별 출력중에서 가장 큰 클래스의 확률이 임계치(논문에선 0.9 사용) 이상인 경우 해당 클래스로 레이블링하고 아닌 경우 무시할 수 있는 클래스로 레이블링하는 방식인데, CityScapes에 대해서 약 0.17TB만이 필요하므로 더 효율적이다.
5. Result
5.1 Auto Labeling Result
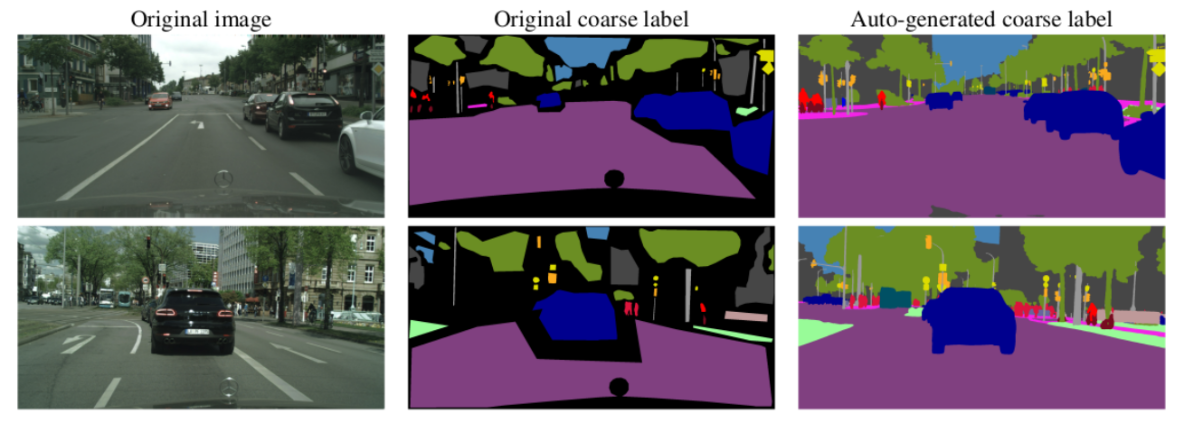
제안하는 Hard Labeling을 통한 Auto Labeling 결과이다. 보다 섬세한 레이블을 제공함으로써, 크고 작은 객체들을 모두 표현하고 Label의 분포가 향상된 것을 확인할 수 있다.
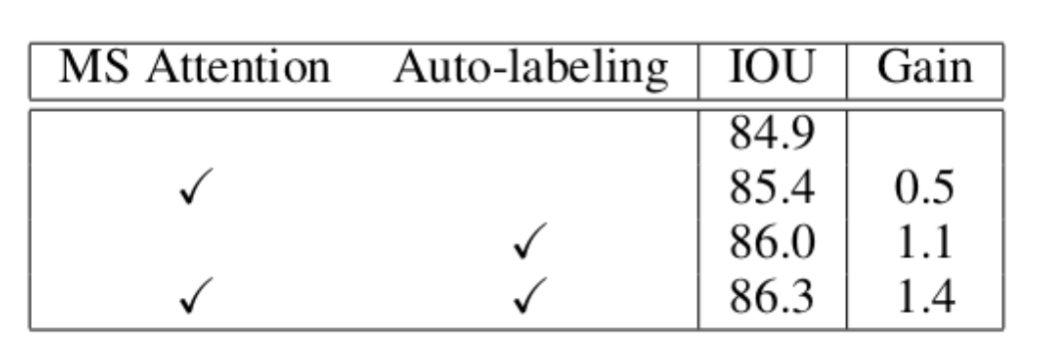
CityScapes Validation Set에 대해서 제안하는 Multi-Scale Attention(Hierarchical Method)와 Auto Labeling을 적용한 결과, 성능 향상에 기여함을 알 수 있다.
5.2 Result on CityScapes

CityScapes Test Set에 대해서 Semantic Segmentation 모델들의 성능 비교 결과이다. 여기서, 논문의 저자는 Trunk로 HRNet-OCR을 더 큰 데이터 셋인 Mapillary Vitas로부터 Pretrain을 했다. 이 때, Loss는 RMI(Region Mutual Information)을 사용했으며, Auxillary Segmentation Head에선 RMI가 성능이 안좋아서 Cross Entrophy를 사용했다. 추론은 (0.5, 1.0, 2.0) Scale과 Image Fliping을 적용했다.
고찰
개인적으로 이 논문을 보면서 느낀점은 다음과 같다.
1. 낮은 정확도 향상 및 추론 시간 성능 평가 부재
Mapillary Validation Set 환경에서 비교한 Multi-Scale Inference 비교 결과를 보면, Explicit Method가 Average Pooling보다 IOU가 향상된만큼, Hierarchical Method는 Explicit Method에 비해 드라마틱한 성능 향상을 보이진 못한것 같다. 또한, 추론시에 Hierarchical Method는 중첩적으로 up/downsampling 및 Pixel-Wise dot, sum 연산이 더 수행되므로 추론 시간이 더 소요 될 것으로 보인다.2. 일정하지 않은 Multi-Scale 경우의 복잡한 로직
예를 들어, (0.5, 1.0, 1.5)의 Scale에 대해서 추론을 해야되는 경우에는 각각 (0.5, 1.0), (1.0, 1.5) Scale에 대한 별도의 학습이 필요하게 되고, 추론시에 Scale 조합별로 모델을 동작시켜야 하므로 복잡한 로직이 추가되어야 한다. (Nvidia에서 제공한 Github 코드에선 일정한 Multi Scale 코드만 제공)

Vision AI Engineer