Abstract
시각적 개체의 스케일과 이미지에 존재하는 고해상도 픽셀같은 영역에서 언어에서 시각으로 트랜스포머를 적용시키는데에 문제가 있고, 이를 해결하기 위해 본 저자는 Shifted Window를 통해 representation을 계산하는 Hierarchical Transformer 구조를 제안한다.
이 구조는 self-attention 계산할 때 효과적이면서, Cross-Window 연결이 가능하도록 한다. 그리고 다양한 이미지 스케일을 적용시킬 때 효과적이고, 선형적인 계산 복잡도를 가진다.
결과적으로 COCO나 ADE20K를 포함한 classification, object detection, segmentation 등 다양한 vision task에서 SOTA를 기록하며 Transformer 기반의 백본 모델의 잠재력을 보여줬다.
1. Introduction
CNN의 구조는 AlexNet 모델을 시작으로 점점 높은 스케일과 깊은 연결 그리고 정교한 구조로 발전되어 가면서 성능을 향상시키는 방향으로 발전되고 있다.
반면, NLP 분야는 Transformer라는 대중적인 방향으로 발전되어 갔다. Transformer는 시퀀스 모델링 및 변환 작업을 위해 설계되어 데이터의 긴 범위의 종속성에 대해서 주의를 기울이는 것으로 유명하다.
NLP 분야의 이러한 성공적인 연구는 Vision 분야로의 적용에 대한 연구를 이끌었고, 특히 image classification이나 vision-language modeling 분야에서 좋은 결과를 보였다.
본 저자는 이러한 NLP에서 Vision 분야로 Transformer를 적용하는 과정에 있어서 두 가지 큰 차이점이 있다고 주장한다.
첫 번째는 스케일이다. NLP에서의 Transformer는 기본적으로 단어 토큰을 사용하지만, Vision에서의 시각적 요소는 스케일에 따라 상당히 달라 질 수 있는데 기존 Transformer는 고정된 크기의 토큰을 사용하기 때문에 적용하기 어렵다는 문제점이 있다.
두 번째는 텍스트의 구절에 비해 이미지에 있는 픽셀의 해상도가 훨씬 높다는 점이다. 특히, 픽셀 단위로 추론이 이뤄지게되는 segmentation task에서 self-attention의 이차원의 계산 복잡도로 인해 적용하기가 힘들어지게 된다.
이를 해결하기 위해 계층적인 feature map 구조를 가지고, 이미지 크기에 선형적인 계산 복잡도를 가진 Swin Transformer를 제안했다.
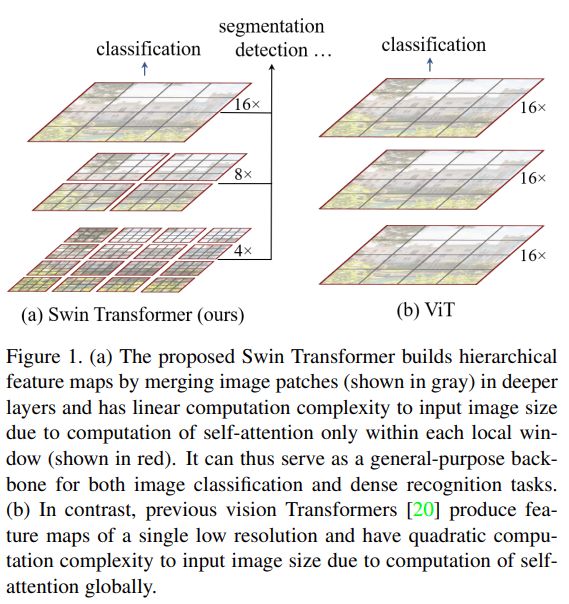
이러한 Hierarchical 구조는 FPN이나 U-Net과 같은 구조를 효과적으로 적용시킬 수 있다. 그리고 위에서 보이는 붉은 선은 window를 의미하는데, window마다 self-attention을 적용함으로써 선형 계산 복잡도가 가능해진다. 각 window별 patch 수는 고정되어 있고, 계산 복잡도는 이미지 크기에 선형적으로 증가한다.
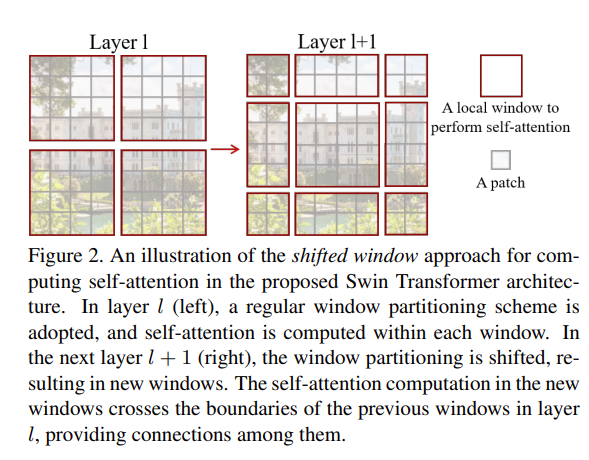
Swin Transformer의 핵심 아이디어는 위와 같이 연속된 self-attention layer 사이에서 window를 이동시키는 것이다. 이동된 window는 이전 계층의 window와 연결되어 모델링 성능을 크게 향상시킨다. 또한, 이 전략은 동일한 window내에 존재하는 모든 쿼리 patch들은 키 patch와 동일하므로 하드웨어에서 메모리 엑세스에 용이하다는 장점이 있다.
2. Related Work
CNN and variants
CNN은 AlexNet 모델을 시작으로 VGG, GoogleNet, ResNet, DenseNet, HRNet, EfficientNet 등의 발전된 모델 구조들이 제안되어왔다. 추가적으로 convolution layer에 대한 연구도 진행되었는데 대표적으로 depth-wise convolution, deformable convolution이 이에 해당된다.
Self-attention based backbone architectures
NLP 분야에서 self-attention layer와 Transformer가 좋은 성능을 보였고, 최근에는 ResNet의 일부 layer를 self-attention layer로 교체하여 사용하는 시도를 했다. 그리고 계산 최적화를 위해 각 픽셀의 local window에서 self-attention을 계산해서 기존 ResNet 구조보다 약간 더 높은 accuracy/FLOPs를 기록했다.
하지만, 비용이 많이 드는 메모리 엑세스로 인해 실제 지연 시간이 convolution network보다 더 길어지는 문제가 있다. 그래서 본 논문에서는 sliding 방식이 아닌 shift 방식을 사용하여 하드웨어 측면에서 더 효율적으로 해결한다.
Self-attention/Transformers to complement CNNs
또 다른 연구는 CNN 구조에 대해서 self-attention layer나 Transformer를 적용해서 강화시키는 방향으로 진행됐다. 최근에는 Transformer의 encoder-decoder 디자인 설계가 object detection이나 instance segmentation task에 적용됐다.
Transformer based vision backbones
본 논문과 가장 깊은 연관이 있는 모델은 ViT 및 이를 활용한 모델들[DeiT, T2T ViT, Pyramid ViT]이다. ViT는 Transformer 구조를 이미지에 그대로 적용했고, convolution layer에 비해 인상적인 speed-accuracy trade off를 보였다. 한편, ViT가 large-scale의 데이터 셋(JFT-300M)을 필요로 하는 반면에 DeiT는 ViT를 좀 더 적은 데이터 셋인 ImageNet-1K에서도 효과적으로 학습할 수 있는 전략에 대해서 소개한다.
ViT의 성능 향상은 놀랄만하지만, 이미지가 고해상도일때는 ViT의 저해상도의 feature map과 이차원의 계산 복잡도 증가 문제로 인해 적용하기 힘들어진다.
기존에는 직접적으로 upsampling을 하거나 deconvolution을 적용함으로써 ViT 모델을 object detection이나 semantic segmentation의 dense vision task에 적용할 수 있도록 시도했으나, 성능 하락을 피할 순 없었다.
3. Method
3.1. Overall Architecture
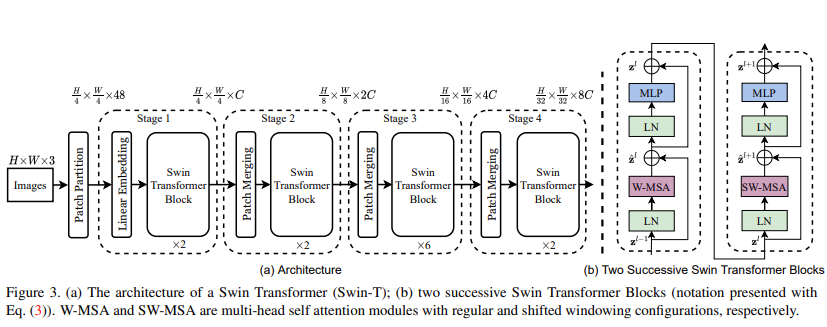
여기서, 각 Stage의 입력으로 들어가는 사이즈는 전체 이미지에 대한 Patch Height 수 x Patch Width 수 x Patch Feature Dimension을 의미한다.
Input
먼저, ViT와 유사하게 RGB 이미지를 non-overlapping patch 형태로 분할한다. 여기서, 각 patch는 token을 의미하고, 원본 RGB 픽셀의 연결로 특징이 구성된다. 본 논문에서는 4x4 사이즈의 patch를 사용했고, 각 patch의 feature dimension은 48(4x4x3)이다.
Stage 1
embedding layer는 앞선 feature들에 대해서 선형 embedding을 수행한다. 그리고나서 Swin Transformer block이 적용된다. 여기서, Stage 1은 Transformer block을 거쳐도 token수는 계속해서 유지된다.
Stage 2, Stage 3, Stage 4
Hierarchical representation을 얻기위해 network가 깊어짐에 따라 token을 합치면서 전체적인 patch 수를
감소시킨다. 첫번째 patch merging layer는 2x2 이웃 patch들의 feature를 연결한다. 그리고 4C 차원으로 연결된 feature에 선형 layer를 적용한다. 이 작업은 token의 수를 4의 배수로 줄이게 한다. [4 = 2(H) x 2(W)] 그리고 출력 차원은 2C로 설정된다. 그 후에 Swin Transformer block은 해상도를 H/8 x W/8로 유지한 채 feature transformation을 위해 적용된다.
Stage 3와 Stage 4는 Stage 2와 동일한 구조이며, 출력 해상도는 각각 H/16 x W/16, H/32 x W/32이다.
Swin Transformer block
Swin Transformer는 기존 Transformer의 multi-head self attention(MSA)를 shifted windows based 모듈로 대체한다. 다른 layer는 동일하다. Swin Transformer는 MSA 기반 shifted window 모듈로 구성되어 있고, GELU와 함께 2-layer MLP가 적용된다. 그리고 Layer Norm(LN)은 각 MSA 모듈 이전과 MLP 이전에 적용되고, residual connection이 각 모듈 이후에 적용된다.
3.2 Shifted Window based Self-Attention
표준 Transformer 구조는 global self-attention을 적용하는데, 이는 Vision 분야에서의 고해상도 이미지에 대해서 2차원적 계산 복잡도 문제로 인해 부적합하다.
Self-attention in non-overlapped windows
계산 효율성을 위해 본 논문은 local window에서 self-attention 계산하는 방식을 제안한다. window들은 서로 겹쳐지지 않는 상태로 균등하게 배열된다. 각 window는 M x M개의 patch들을 포함하는것으로 가정하면, Global MSA 모듈과 h x w 개의 패치를 가지는 이미지에서 window를 기반으로 한 계산 복잡도는 다음과 같다.
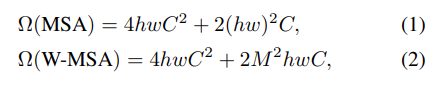
MSA의 경우는 전체 patch 수인 hw에 이차원의 복잡도를 가지지만, W-MSA의 경우 M이 고정(논문에선 7)되어 있으므로 선형 계산 복잡도를 가지게 된다.
Shifted window partitioning in successive blocks
windows-based self-attention 모듈은 윈도우 간의 연결에 결핍이 발생한다. 계산 복잡도의 이점을 가져가면서 윈도우간 연결성을 가지도록 본 논문에서는 shifted window partitioning configurations을 제안한다.
Figure 2를 참고하면, 기본적인 전략은 먼저, 좌상단 픽셀로부터 일반 window partitioning 전략과 같이 8 x 8 feature map을 2 x 2 window로 균일하게 나눈다. 여기서, 각 window는 4 x 4의 크기를 가진다. (M=4, patch 단위)
그 다음에는 window의 위치를 ([M/2],[M/2]) 만큼 이동시킨 뒤 규칙적으로 나눈다.
이 과정을 식으로 나타내면 다음과 같다.
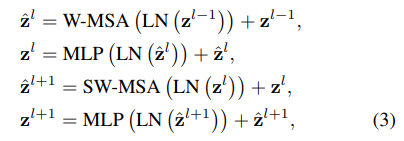
shifted window partitioning 전략은 이전 레이어에 존재하는 이웃하는 non-overlapping windows에 대해서 연결을 제공함으로써 효과적인 성능을 얻을 수 있다. (Table 4에 기재)
Efficient batch computation for shifted configuration
shifted window partitioning을 수행할 때 배치를 효과적으로 할 필요가 있는데, Figure 2를 보면 W-MSA의 window 수는 [h/M] x [w/M] 이지만, SW-MSA의 경우는 ([h/M] + 1) x ([w/M] + 1)으로 늘어난 것을 확인할 수 있다. 예를 들어, Figure 2의 경우처럼 2 x 2 window에서 3 x 3 window로 갯수가 증가했을때 연산량은 약 2.25배 증가하게 되어 비효율적이다.
그리고 어떤 window 들의 크기는 M x M 보다 작아질 수도 있게 된다. 이러한 경우 간단하게 M x M 크기로 패딩을 한 다음, 패딩 된 값에 마스킹을 적용하여 해결해야 된다. 하지만, 이 경우도 연산량이 증가하게 되는 문제점이 있다.
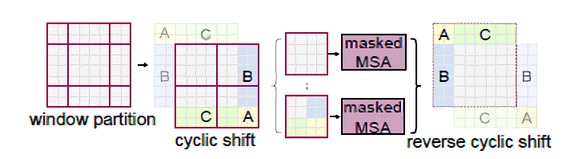
이를 해결하기 위해 본 논문에서는 위와 같이 top-left 방향으로 cyclic-shifting하는 효과적인 batch 연산 접근법을 제안한다.
이 shift 방법은 먼저 window partition으로부터 top-left로 이동시키게 되면, 위의 좌측 상단의 A, B, C 만큼의 영역이 나가게 되고, 우측 아래에 A, B, C 만큼의 영역이 새로 들어오게 된다. 이 때, A, B, C 영역 만큼을 다시 계산하지 않고 Mask 처리하여 진행한다. 이렇게 했을 때 window size는 2 x 2가 된다.
그리고 다시 [h/M] x [w/M] 만큼 이동했을 때 제일 오른쪽 그림처럼 좌측 상단에 또다시 A, B, C 영역이 나가고 우측 하단에 A, B, C 생기게 되는데 앞과 같이 Mask 처리를 한다. 이러한 방법으로 window size는 2 x 2로 유지되게 되어 low latency를 얻을 수 있다. (이동된 window 좌표를 다시 계산하지 않고 그대로 사용할 수 있다.)
Relative position bias
본 논문에서는 self-attention을 계산할 때, relative position bias[B ∈ RM2xM2]를 유사도 계산하는 각 head에 추가했다.
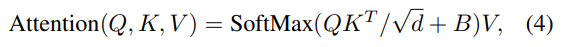
여기서, Q, K, V는 각각 query, key, value를 의미하고 M2xd 차원을 가진다. d는 query/key 차원이고, M2는 window에 존재하는 patch 수를 의미한다.
상대 위치는 각 축을 따라 [-M+1, M-1]의 범위에 존재하므로 bias matrix를 Bˆ∈R(2M−1)×(2M−1)
로 구성하여 이로부터 relative bias B의 값을 가져온다.
absolute position embedding과 비교했을 때 확연한 성능 향상을 얻을 수 있었다.
pretraining시에 학습된 relative position bias는 다른 window size로 bi-cubic 보간을 통해 fine-tuning하여 모델을 초기화할 수 있다.
3.3 Architecture Variants
본 논문의 base 모델은 Swin-B로 칭하며, ViT-B/Deit-B와 유사한 계산 복잡도를 지닌다.
그리고 Swin-T, Swin-S, Swin-L 모델은 각각 0.25, 0.5, 2배의 계산 복잡도를 지닌다. 여기서, Swin-T와 Swin-S는 각각 ResNet-50(DeiT-S) 그리고 ResNet-101과 계산 복잡도가 유사하다.
window 사이즈는 7을 defulat 값으로 사용했고, 각 head의 query 차원 d는 32로, 각 MLP의 expansion layer는 4로 사용했다.
4. Experiments
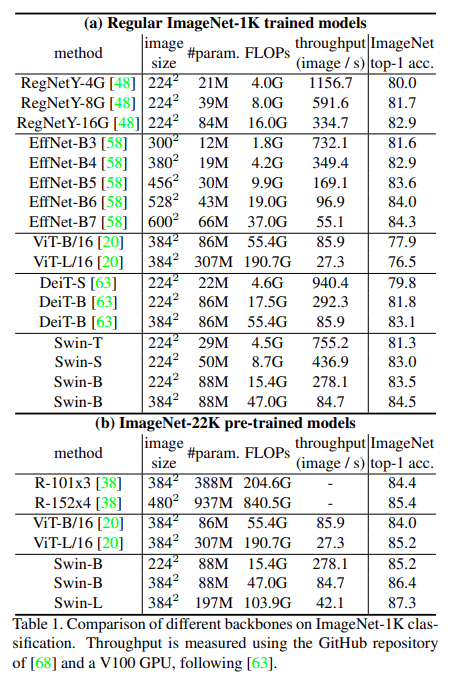
ImageNet-1K sota 성능 비교 결과
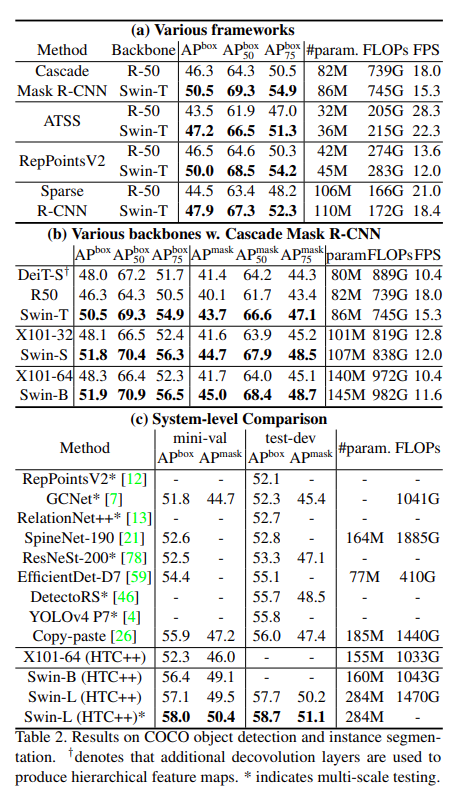
COCO sota 성능 비교 결과
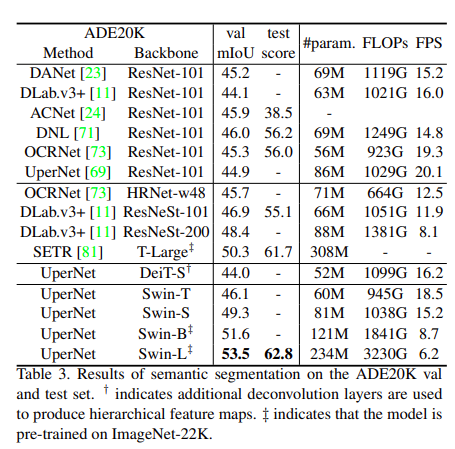
ADE20K sota 성능 비교 결과
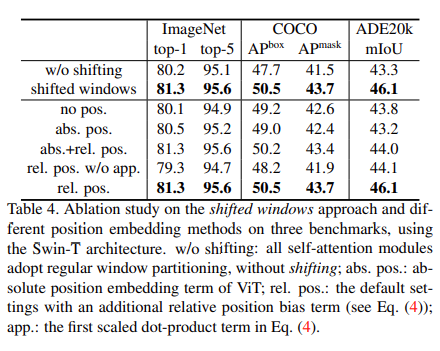
Ablation Study(position embedding, shift window)
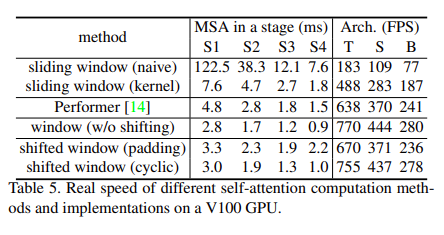
shift window 기법에 따른 연산 속도 측정 결과
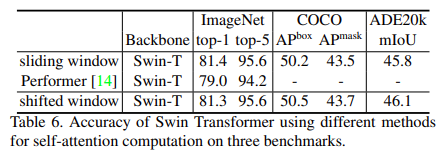
shift window 기법에 따른 성능 비교 결과
5. Conclusion
본 논문에서는 hierarchical feature representation과 선형적인 계산 복잡도를 생성하는 새로운 버전의 Transformer인 Swin Transformer를 소개했다. Swin Transformer의 핵심은 shifted window 기반 self attention 연산이고, 이를 통해 COCO object detection과 ADE20K semantic segmentation Task에서 SOTA를 달성했다.
