Faster R-CNN : Towards Real-Time Object Detection with Region Proposal Networks
Computer Vision
Abstract
본 논문에서는 fully convolutional network 구조이고 이미지로부터 convolutional feature를 공유함으로써 추가 연산 비용이 들지 않으면서 이미지의 각 위치에서 Object의 경계와 유무에 대한 효과적인 추론이 가능한 Region Proposal Network(RPN)을 소개한다. 또한 RPN은 end-to-end 형태로 학습되며, 본 논문에서는 Fast-RCNN구조와 RPN을 병합한 하나의 single network를 제안한다.
1. Introduction
R-CNN, Fast R-CNN은 모두 Region Proposal을 구하기 위해 Selective Search를 사용했다. 그리고 R-CNN은 각 Region Proposal들을 CNN에 입력했기 때문에 많은 시간이 소요되었고, Fast R-CNN은 CNN으로부터 Feature를 계산하고, Region Proposal들을 이 Feature에 매칭하는 ROI Pooling을 통해 시간을 단축 시킬 수 있었다.
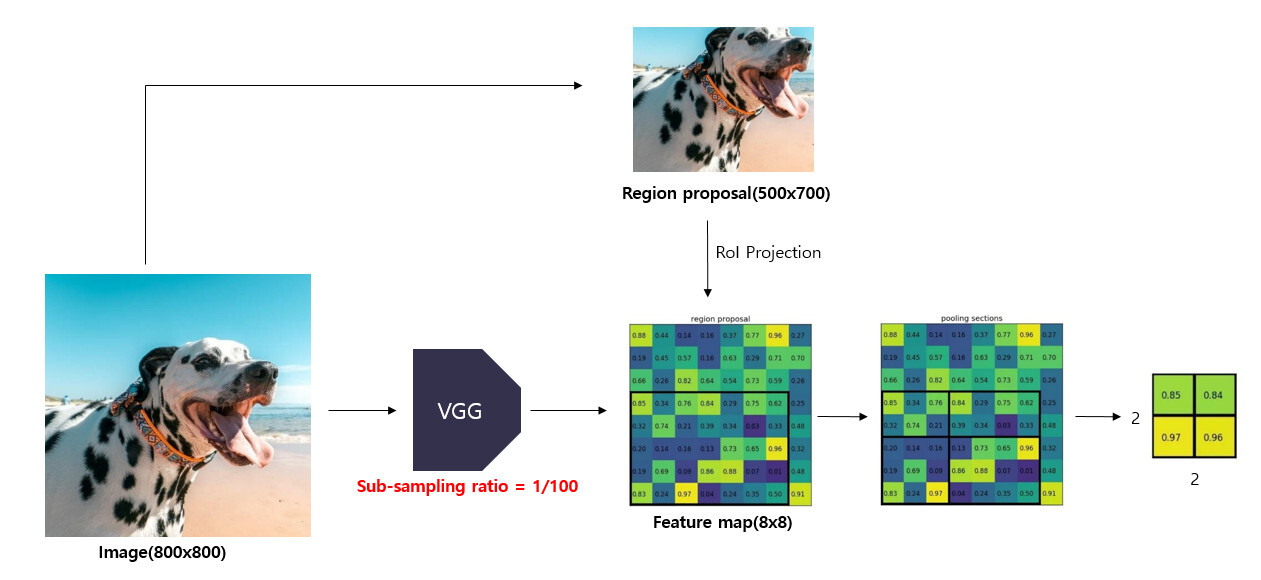
ROI Pooling
본 논문이 나오기 전엔 주로 region-based convolutional neural networks(e.g. R-CNN)들이 object detection 연구를 주도하고 있었다. 하지만, R-CNN의 경우는 각 Region Proposal에 대해서 CNN 연산을 독자적으로 수행하기 때문에 많은 시간이 소요된다. Fast R-CNN은 Region Proposal을 convolutional network에서 공유함으로써 시간을 단축시킬 수 있었다.
그러나 Region Proposal에 주로 사용되는 Selective Search는 cpu에서 구현된 경우 이미지당 2초가 소요될 정도로 느리고, 최근 EdgeBoxes 방법은 이미지당 0.2초가 소요되어 시간을 많이 단축했지만 여전히 detection network내에서 region proposal step은 많은 시간이 소요된다.
fast region-based CNN 네트워크들은 GPU의 이점을 활용했지만, region proposal 방법들은 주로 cpu에서 구현되었기 때문에 이러한 문제가 발생된다.
본 논문에서는 이러한 문제들을 해결하기 위해 region proposal 부분을 convolutional neural network로 계산하는 방법에 대해서 제안한다. 이를 위해 본 논문에서는 sota의 detection network들과 convolution layer를 공유하는 RPN(Region Proposal Network)를 제안했다.
convolution feature로부터 그리드의 각 위치에서 영역 경계와 객체 존재에 대한 점수를 동시에 회귀하는 몇가지 convolutional layer를 추가하여 RPN을 구성한다. RPN은 일종의 FCN(Fully Convolutional Network)이며, end-to-end 형태로 학습될 수 있다.
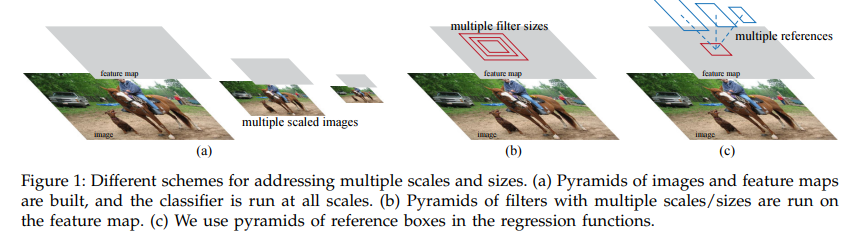
기존에는 Figure 1 (a)와 같이 여러 스케일의 이미지와 feature map에 대해서 classifier를 적용하는 반면에 본 논문에서는 Figure 1 (c)와 같이 하나의 이미지와 feature map에서 multiple scale과 aspect ratio를 가진 "anchor"를 적용해서 multiple scale/size에 대한 추론이 가능하게 한다.
본 논문에서는 RPN을 Fast R-CNN에 적용하기 위해 교대로 region proposal task와 object detection 사이에서 fine tuning하는 훈련 스키마를 제안한다.
Faster R-CNN은 test time에서 Selective Search에 대한 시간을 아낄 수 있고, GPU에서 5fps를 달성하여 속도와 성능면에서 유용함을 보인다.
2. Related Work
Object Proposal
object proposal는 많은 연구가 진행되고 있는 분야이고, 그중에서 대표적으로 grouping super-pixels(e.g. Selective Search, CPMC, MCG)와 이것을 베이스로 한 sliding windows(e.g. objectness in windows, EdgeBoxes)가 있다.
Deep Networks for Object Detection
R-CNN method의 경우는 proposal region들을 object category나 background로 분류하기위해 CNN을 end-to-end형태로 학습시킨다. 여기서 R-CNN은 region proposal module에 따라 성능이 크게 차이나게 된다. R-CNN은 OverFeat이나 MultiBox에서의 proposal 방법을 사용하는데, 이 proposal은 detection network나 proposal간에 서로 feature를 공유하지 않는 문제가 있다.
Faster R-CNN은 convolutional feature를 공유하면서 end-to-end 형태로 detector를 학습할 수 있게 하고, 설득력이 있는 정확성과 속도를 보인다.
3. Faster R-CNN
Faster R-CNN은 두 모듈로 구성되어있다. 첫번째 모듈은 region들을 propose하는 deep fully convolutional network이고, 두번째 모듈은 proposed region을 사용하는 Fast R-CNN detector이다.
전체 구조는 다음과 같다.
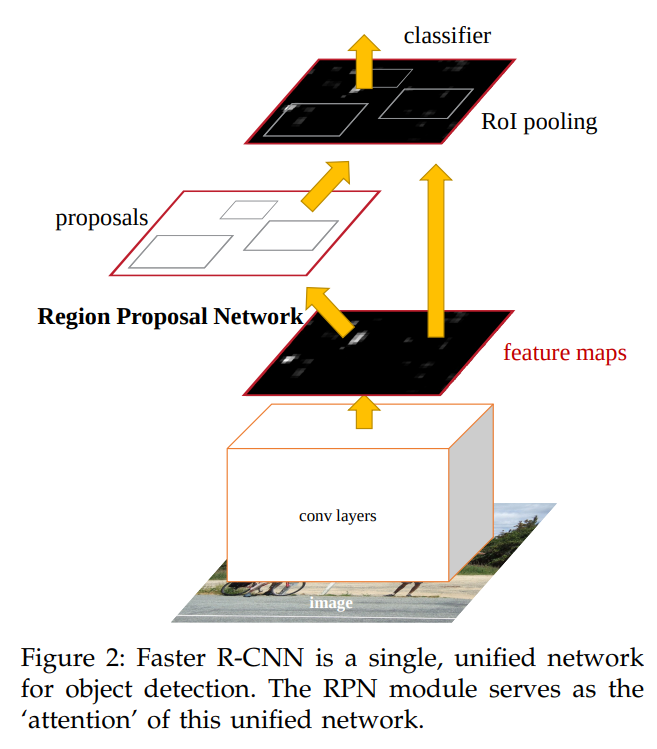
3.1 Region Proposal Networks
RPN(Region Proposal Network)는 이미지를 입력으로 받고, objectness score와 함께 직사각형의 object proposal의 집합을 output으로 한다. 이 네트워크는 Fast R-CNN과 feature를 공유하기위해 fully convolutional network로 구성된다.
RPN을 생성하기위해 먼저, 마지막으로 공유된 convolutional layer에서 small network를 slide한다. 이 network는 convolutional feature map로부터 n x n spatial window를 입력으로 갖는다. 각 sliding window은 저차원 feature로 매핑된다. (e.g. 256-d for ZF and 512-d for VGG, with ReLU following)
이 feature들은 이어서 두 개의 이웃한 fully connected layer로 연결된다.
1. box regression layer(reg)
2. box classification layer (cls)
본 논문에서는 입력 이미지의 유효 receptive field가 넓다는 점에서 n=3으로 사용했다. 여기서 주의할 점은, mini-network가 sliding-window 방식으로 작동하므로 fully-connected layer들은 모든 공간에서 공유된다. 구조는 n x n convolutional layer와 2개(reg, cls)의 이웃한 1 x 1 convolutional layer로 구성된다.
3.1.1 Anchors
각 sliding-window 위치에서 여러 region proposal을 동시에 예측하며, 여기서 각 위치에 대해 가능한 최대 proposal 수는 k로 표시된다. 그러므로 reg layer는 4k의 output을 가지고, cls layer는 2k의 output shape을 가진다. 여기서 k개의 proposal들은 anchor라 불리는 k개의 reference box에 관련하여 parameterized된다.
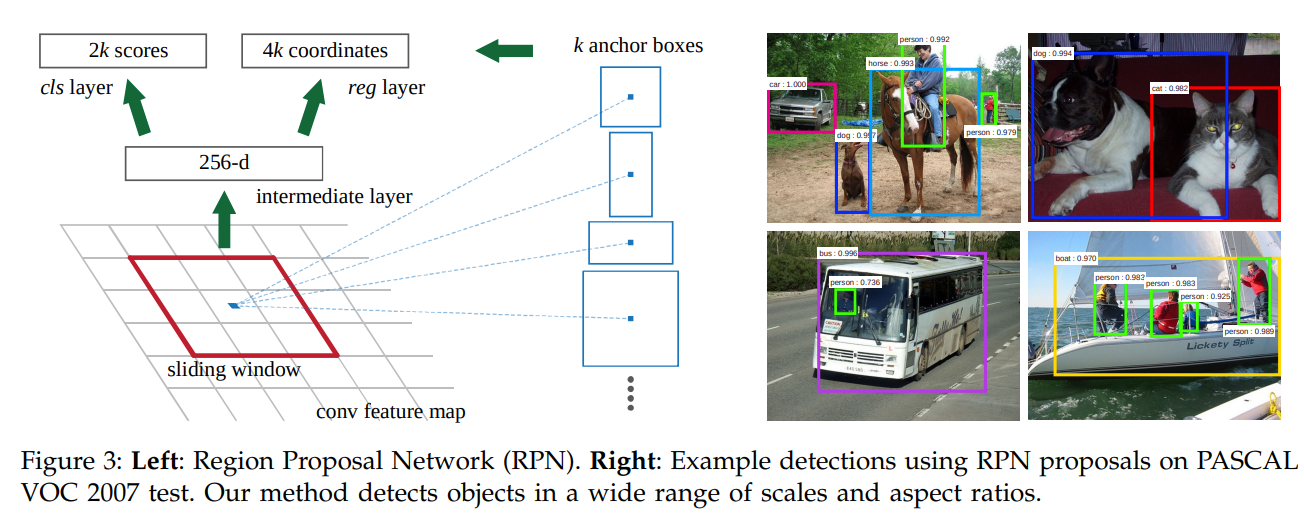
Anchor는 sliding window의 중심에 위치하며, 스케일 및 가로 세로 비율과 관련이 있다. 본 논문에서는 3 scale, 3 aspect ratio를 사용하여 k=9의 anchor를 각 sliding position에 사용한다.
Multi-Scale Anchors as Regression References
multiple scale 추론에는 대표적으로 Figure 1과 같이 multiple scale image/feature pyramid와 pyramid of filters 방법이 있다. multiple scale image/feature pyramid는 여러 스케일의 이미지에 대해서 리사이즈하고, 추론을 하기 때문에 시간이 많이 소요되고, pyramid of filters 또한 여러 스케일의 filter에 대해서 추론을 수행하기 때문에 시간이 많이 소요된다. 하지만, 본 논문에서 제안하는 방식은 각 single image, feature와 single filter를 사용하기 때문에 효율적이다.
3.1.2 Loss Function
RPN을 학습시키기 위해 본 논문의 저자는 binary class label을 각 anchor에 할당했다. 그리고 다음과 같은 anchor에 대해서 positive label을 할당했다.
1) gt bbox와 가장 높은 IOU를 가지는 anchor
2) gt bbox에 대해서 0.7 이상의 IOU를 가지는 anchor
그리고 모든 gt bbox에 대해서 0.3 이하의 IOU를 가지는 anchor는 negative label을 지정했으며, 0.3과 0.7사이의 IOU를 가지는 anchor는 학습에 사용하지 않았다.
Faster R-CNN loss function은 다음과 같다.
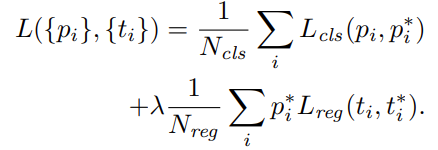
여기서, i는 mini batch에서의 anchor의 index를 의미하고, 는 i anchor의 object probability를 의미한다. 은 4개의 parameterized box coordinate를 의미한다.
그리고 는 mini-batch size를 의미하고 논문에선 256값을 가진다. 는 anchor locations의 수를 의미하고 논문에선 2400값을 가진다. 추가적으로 본 논문에서는 λ 값을 10으로 설정하여 cls와 reg loss가 유사하게 가중되도록 했다.
은 two classes(object vs not object)에 대한 log loss이고, Regression에 대한 Loss는 (,) = 이며, 여기서 R은 robust loss function(smooth )를 의미한다.
box coordinates를 parameterized한 식은 다음과 같다.
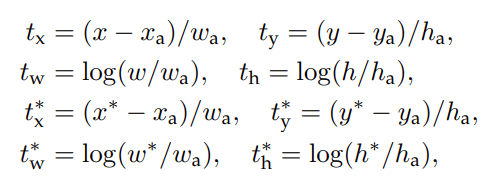
이 식은 anchor box에서 근처의 gt box로의 회귀라고 볼 수 있다.
3.1.3 Training RPNs
RPN을 학습할 때 모든 anchor에 대해서 학습시킬 수 있지만, positive anchor에 비해 negative anchor가 많으므로 편향이 발생할 수 있다. 본 논문에서는 256개의 anchor에 대해서 randomly sample하고, positive와 negative anchor에 대해서 1:1로 비율을 맞추는 작업을 수행했다.
3.2 Sharing Features for RPN and Fast R-CNN
본 논문에서는 Fast R-CNN과 RPN은 서로 독립적으로 학습되기때문에 서로 convolution layer를 공유하기위한 방법을 소개한다. i. Alternating training, ii. Approximate joint training, iii. Non-approximate joint training
(i) Alternating training : 먼저 RPN을 학습한 후에 Fast R-CNN에 대해서 proposal을 제공하여 학습하고, 그런 다음 Fast R-CNN에 의해 조정된 네트워크는 RPN을 초기화하는데 사용하여 이 과정을 반복한다.
4. Experiments
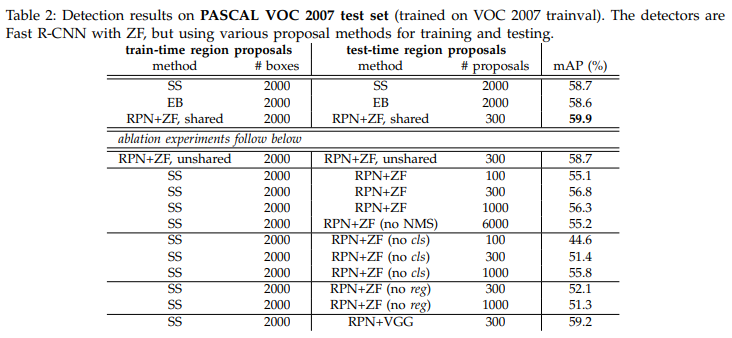
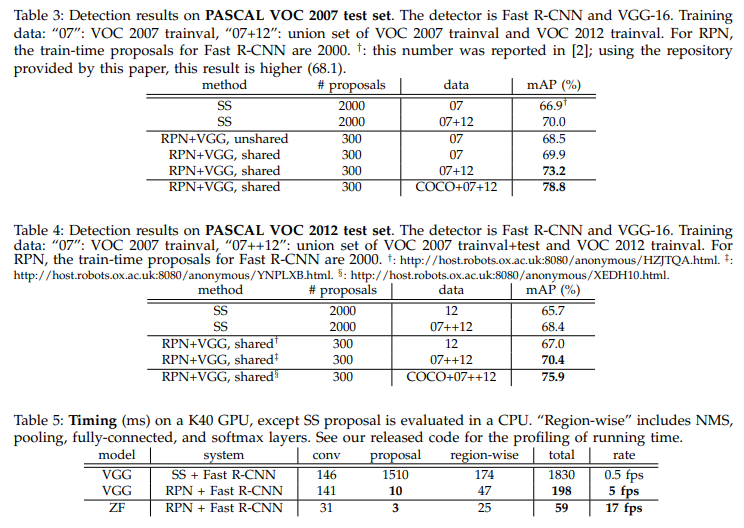
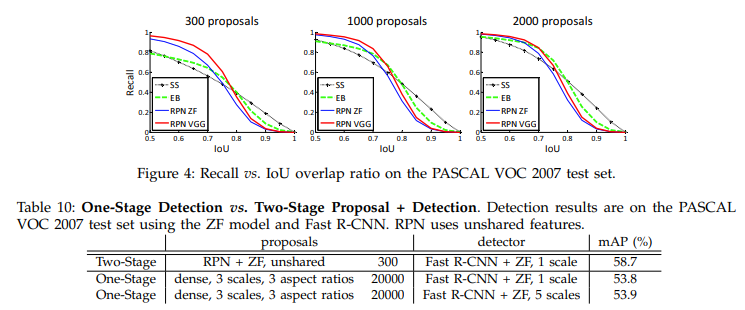

5. Conclusion
본 논문에서는 효율적이고 정확한 region proposal generation인 RPN 모델을 제시했다. down-stream detection network에 대해서 convolution feature를 공유함으로써 계산 비용을 줄일 수 있었다. 본 논문에서 제시한 알고리즘은 통합, deep learning 기반 object detection 시스템을 real-time에서 가능할 수 있도록 지원한다. 마지막으로 RPN은 region proposal의 quality를 높임으로써 object detection 성능을 올릴 수 있었다.
참조
