Transparent Image Layer Diffusion using Latent Transparency

본 논문에서는 Pretrained LDM을 활용하여 Transparent 이미지 생성하는 방법을 제안한다. 이 방법은 "latent transparency"를 학습하는데, 이는 Pretrained LDM의 잠재 공간으로 alpha 채널의 투명성을 인코딩할 수 있도록 한다. 추가된 투명성은 잠재 공간에서 latent offset로써 조정되며, 기존 잠재 분포에 최소화된 변화를 가져온다. 이를 통해 기존 LDM을 조정된 잠재 공간으로 Fine Tuning하면 Transparent Image Generator로 활용할 수 있다.
Introduction
논문 저자는 먼저, 아래와 같은 Transparent 이미지 생성 연구의 어려움에 대한 지적을 한다.
- Transparent 이미지 생성 분야는 마켓의 수요와는 대조적으로 연구가 원활히 진행되지 않고 있다.
- Text-Image Dataset과는 달리 Transparent 이미지는 대부분 상업용으로 구성되어 있다.
- Stable Diffusion 모델의 경우 Latent Space Data Representation에 민감하기 때문에 이는 Data Representation을 조작하여 Transparent Image와 같은 추가 형식을 지원하는 것이 어렵다.
이러한 문제를 해결하기 위해 논문의 저자는 'latent transparency' 접근법을 제안했다. 'latent transparency'는 외부의 독립적인 모듈을 통해 encode / decode 되어, 사전 학습된 encoder와 decoder가 유지되도록 보장한다. 그리고 이를 통해 Pretrained LDM의 높은 품질 결과물을 보장할 수 있도록 한다. multiple layer 이미지를 얻기 위해 'shared attention mechanism'을 사용하여 각 layer 간의 consistency와 harmonious blending을 보장할 수 있도록 유도했고, 다양한 layer condition(e.g. foreground, background, structual control etc.)에 따른 LoRA 모델을 학습했다.
데이터 셋은 'Human-In-The-Loop' 방식으로 1M의 Transparent 이미지를 취득했으며, SOTA method를 활용하여 multi-layer sample로 확장하였다.
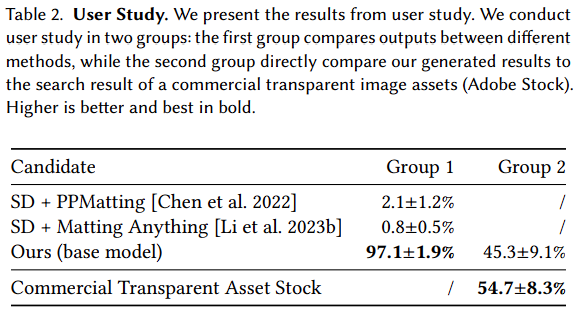
제안하는 방식은 기존의 generating-matting 방식보다 97%의 사람 선호도를 얻었고, Adobe Stock과 비교해도 유사한 선호도를 얻을 수 있음을 명시했다.
Related Work
Hiding Images inside Perbutations
다양한 분야의 연구에서 신경망은 전체적인 특징 분포를 변경하지 않으면서 기존 특징 내부의 미세한 변형에 특징을 숨길 수 있다고 밝혔다. 예시로 CycleGAN의 "face-to-ramen", Invertible Downscaling 등이 있다.
본 논문에서는 비슷한 원리로, small perturbation을 추가하여 이미지의 transparency feature를 Stable Diffusion의 latent space에 숨기면서, 전체적인 latent space의 분포를 변화시키지 않는 방법을 적용했다.
Diffusion Probabilistic Models and Latent Diffusion
Diffusion Probabilistic Model과 관련된 학습 및 샘플링 방법론인 DDPM, DDIM, Score-based Diffusion은 Large-Scale Image Generator의 기반이 되었다. 기존에 Diffusion Method는 Pixel Color를 직접적으로 학습 데이터로써 사용했는데, 이와 대조적으로 Latent Diffusion Model은 Latent Space에서 동작어 적은 연산량을 가지면서 쉽게 학습할 수 있는 장점이 있다.
이 방법론은 Stable Diffusion으로 확장되었으며, 최근 eDiff-I는 T5 text encoder와 CLIP의 text, image embedding encoder를 포함한 여러 Condition의 앙상블을 사용했다. Versatile Diffusion에서는 단일 모델에서 text, image, variation들을 생성할 수 있도록 다목적 diffusion framework를 적용했다.
Customized Diffusion Models and Image Editing
초기 Diffusion Model을 Customize하는 방법은 주로 Text-Guidance를 활용한 것이었다. Textual Inversion, Dreambooth는 동일한 주제나 오브젝트에 대한 몇개의 예시 이미지로 생성된 결과물을 개인화할 수 있다.
최근에는 text-to-image model에 추가적인 Condition을 부여하기 위해 Controlnet이나 T2I-Adapter와 같은 Control 모델들이 사용되었다. IP-Adapter는 text와 image feature를 분리하기 위해 cross-attention mechanism을 사용했으며, reference image의 control signal을 visual prompt로 사용할 수 있게 했다. 이외에도 Inversion-based Method에 대해서 소개한다. Inversion-based Method는 입력 이미지에 대해서 별도의 diffusion process로 생성될 필요 없이 최적화할 수 있다. 이를 기반으로 spatial cross-attention feature를 조작하거나 text prompt를 입력 이미지의 attention activation을 편집하고, DiffEdit과 같이 입력 이미지와 프롬프트 기반으로 편집하기 위한 region mask를 생성하는 등의 방법론들을 소개했다.
Transparent Image Layer Processing
Transparent image processing은 image matting과 같이 image decomposition, layer extraction, color palette processing과 연관되어 있다. 전형적으로 color-based decomposition은 RGB color space geometry 문제라고 볼 수 있고, 이 아이디어는 image layer의 향상된 blending으로 발전됐다. 언믹싱(unmixing) 기반 색상 분리는 image decomposition에 기여하며, semantic features는 soft segmentation에 활용될 수 있다. 본 논문에서는 실험과 논의를 위해 State-of-the-Art의 딥러닝 모델들과 비교를 진행했다. (Matting Anything, PPMatting)
본 논문에서 제안하는 방식은 Image Matting의 후처리를 사용하는 것이 아닌 Transparent Image를 생성하는 것에서 시작한다고 언급했다.
Method
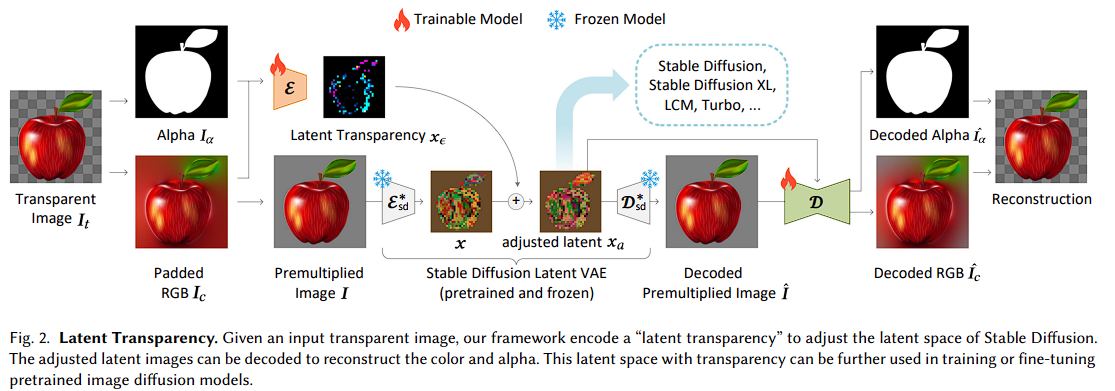
본 논문 3.1 섹션에서는 LDM latent space로 하여금 transparent image encoding/decoding이 가능하도록 조절할 수 있는 method를 소개한다. 그리고 3.2 섹션에서는 pretrained latent diffusion model을 적용하여 transparent 이미지를 생성한 결과물을 보여준다. 3.3 섹션에서는 joint 혹은 conditional layer 생성 방법에 대해 설명하고 마지막으로 3.4 섹션에서 신경망 훈련을 위한 데이터 셋 준비 및 구현에 대한 세부 사항을 설명한다.
정의
- Transparent Image :
- RGB Image : 단, 정의되지 않은 영역은 가우시안 패딩 적용.
- Alpha Channel :
- 여기서, 와 는 각각 [-1,1], [0,1]의 범위를 가진다.
Latent Transparency
본 논문의 목표는 Stable Diffusion과 같은 Large-Scale Latent Diffusion Model이 Transparency 지원을 가능하게 하는것이다.
여기서 중요한 점은 VAE와 Diffusion Model이 동일한 Latent Distribution을 공유해야 한다는 사실이다. 이를 위해선 Transparency를 지원하도록 Latent Space을 조정할 떄 기존의 Latent Distribution을 최대한 유지해야 한다. 논문에서는 이러한 목표를 간단한 측정으로 해결했다. 이는 바로 수정된 Latent Distribution이 사전 학습된 고정된 Latent Decoder에 의해 얼마나 잘 동작하는 지 확인하는 것이다.
RGB 이미지 와 사전 학습된 Stable Diffusion 모델의 고정된 Latent Encoder 와 Deocder 가 주어졌을 때, 일반적으로 이미지의 Latent Vector는 다음과 같이 표현된다.
그리고, Latent Vector 가 어떠한 오프셋 에 의해 조정된 경우 Latent Vector는 으로 표현될 수 있고 RGB 복원 과정은 다음과 같이 표현된다.
"harmfulness"는 위에서 구한 복원 이미지 와 원본 이미지 와의 차이를 계산하여 구할 수 있다.
위의 수식으로 구한 값의 크기를 통해 Latent Vector Offset 의 Latent Distribution에 미치는 영향을 파악할 수 있다.
또한, 대부분의 주류 VAE는 KLDivergence 또는 Diagonal Gaussian Distribution 모델이므로, 이러한 모델은 종종 Latent Space에서 표준 편차를 오프셋으로 사용하는 단순히 학습된 매개변수를 포함한다. 이 표준 편차를 로 표시하면, 이 사전 학습된 매개변수를 활용하여 다음과 같이 을 구성할 수 있다.
- x_{offset} : 새로 추가된 Encoder의 원시 출력
- x_{std} : 사전 학습된 VAE의 표준편차
- : 가중치 매개변수, 기본 값은
논문에서는 Transparency 이미지를 인코딩/디코딩하기 위한 Latent Transparency를 구축하기 위해 Latent Offset 을 활용하고, 구체적으로 RGB 채널 와 알파 채널 를 입력받아 픽셀 공간의 Transparency를 Latent Offset으로 변환하는 Latent Transparency Encoder 를 처음부터 학습한다.
그리고, 조정된 Latent Space로부터 Transparency 이미지를 추출하기 위해 조정된 Latent Vector 과 앞서 언급된 RGB 복원 를 입력으로 받는 또 다른 Latent Transparency Decoder 를 처음부터 학습한다.
reconstruction loss 측정 방법은 다음과 같다.
여기서, 논문 저자는 실험적으로 PatchGAN에 소개된 discriminator loss를 적용했을 때 결과가 좋다는 것을 발견했다고 언급했다.
최종 Loss 함수는 다음과 같다.
여기서, 이고 을 기본값으로 사용했다.
Diffusion Model with Latent Transparency
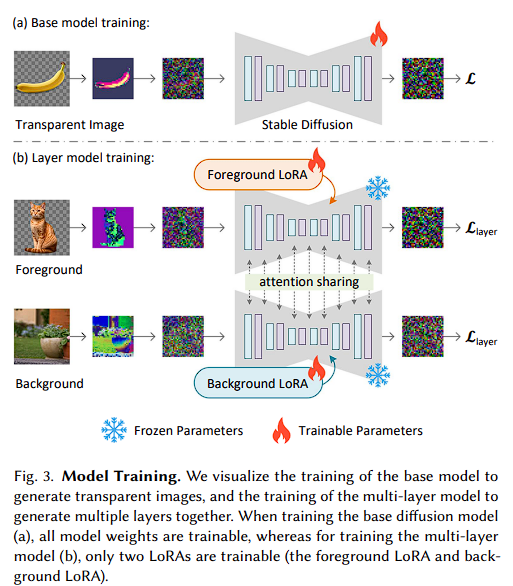
Timestep 와 텍스트 프롬프트 가 주어진 상태에서, Image Diffusion 알고리즘은 네트워크 를 학습한다.
Generating Multiple Layers
논문에서는 Fig 3.(a)에서 명시된 base model을 Fig3.(b)의 multi-layer model로 확장시키기 위해 attention sharing과 LoRA를 사용했다.
논문 저자는 전경에 노이즈가 포함된 Latent를 로 표현했고, 배경을 로 나타냈다. 그리고 latent 이미지의 노이즈를 제거하기 위한 2개의 LoRA 모델을 학습했는데 전경은 , 배경은 로 나타냈다.
두 모델이 독립적으로 Denosing하면 목적식은 아래와 같다.
그다음, 두 독립적인 diffusion 과정을 병합하여 일관된 생성을 달성한다. 확산 모델의 각 attention layer에서 두 이미지에 의해 활성화된 {key, query, value} 벡터를 모두 연결(concatenate)하여 두 패스를 병합하고, 공동 최적화된 대형 모델 (.)를 생성한다. 병합된 노이즈를 로 나타내며, 최종 목표는 다음과 같다.
이를 통해 Multiple Layer를 함께 일관성있게 생성할 수 있다. 또한, 간단한 수정을 통해 Foreground Conditioned Background Generation, Background Conditioned Foreground Generation과 같은 conditional layer를 지원할 수 있다. 구체적으로 noisy latent대신 foreground( 혹은 background noise()가 없는 clean latent를 사용하면 전경 혹은 배경 condition generator로 작동된다.
Dataset Preparation and Tranining Details
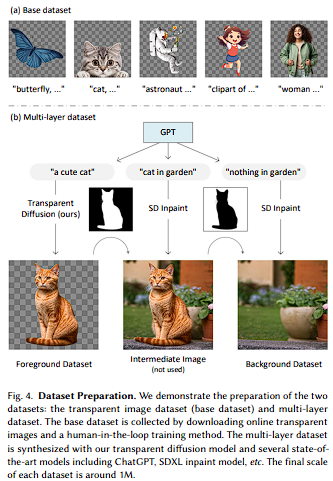
Base Dataset

논문 저자는 'human-in-the-loop' 방식으로 온라인의 약 2만 개 transparent 이미지로 데이터 셋을 구성했다.
먼저, 데이터 셋에 대해서 동일한 확률로 샘플링하여 SDXL VAE 모델을 학습하고, 이후에 동일한 방식으로 SDXL Diffusion 모델을 학습했다. 그 다음 총 25회에 걸쳐 아래 단계를 반복했다.
- 각 단계 시작시, 이전 단계에서 사용된 마지막 모델을 통해 약 1만 개의 랜덤 샘플을 생성한다. 여기서, 각 샘플은 LAIONPOP의 랜덤 프롬프트를 사용했다.
- 생성된 샘플 중 수동으로 1,000개의 샘플을 골라 훈련 데이터셋에 추가한다. 새로 추가된 샘플은 다음 단계의 훈련 배치에서 2배 높은 확률로 나타나도록 설정했다.
- Latent Transparency Encoder/Decoder와 Diffusion Model을 다시 학습한다.
25 단계를 반복하면 데이터 셋의 크기는 45K로 증가하고, 이후에는 사람의 개입없이 500만 개의 샘플 쌍을 생성하고, LAION Aesthetic 임계값 5.5와 CLIP 점수 정렬을 사용하여 100만 개의 샘플 쌍을 선택한다. 여기서, 투명 픽셀이 전혀 없거나, 전체가 투명한 이미지는 자동으로 제거한다.
마지막으로, 모든 이미지에 대해 LLaVA를 사용해 상세 텍스트 프롬프트로 캡션을 생성한다. VAE와 Diffusion 모델의 최종 학습은 이 100만 개의 데이터 셋을 사용하여 15,000 iteration step으로 진행된다.

표 1을 통해 각 라운드 별 학습된 모델에 대한 결함 이미지 수를 제시했고, 라운드가 진행될수록 그 수가 줄어드는 것을 확인할 수 있다.
Multi-layer Dataset
Fig-4(b)에 표현된 것과 같이 논문 저자는 {text, transparent image} 데이터 셋을 {text, foreground, background} 데이터 셋으로 확장하여 Multi-Layer Model을 학습할 수 있도록 했다.
- Foreground Caption : "a cute cat"
- Entire Image Caption : "cat in garden"
- Background Caption : "nothing in garden" (GPT에게 "nothing"을 추가하도록 요청)
여기서, 100,000개의 요청은 ChatGPT로 처리하였고, 이후 900,000개의 요청은 LLAMA2를 사용하였다.
데이터 셋 생성 과정은 다음과 같다.
1. Foreground Layer 생성 : 학습된 Transparent Image Generator와 Foreground Prompt로부터 Transparent Image를 생성한다.
2. Intermediate Image 생성 : SDXL Inpaint 모델을 통해 Transparent의 alpha값이 1보다 작은 모든 픽셀을 인페인팅하여 Entire Image Prompt에 맞는 이미지를 생성한다.
3. Background Layer 생성 : Alpha 마스크를 반전시킨 뒤, 가장자리를 k=8로 erode후에 Background Prmopt만을 사용하여 다시 인페인팅하여 Background Layer를 얻는다.
위 과정을 1M time 반복하여 데이터 셋을 생성한다.
훈련 세부 정보
- GPU : A100 * 4
- 학습 시간 : 약 1주일
- GPU 사용 시간 : 350 hour/A100
- 비용 : 약 1,000 USD
- 모델 정보
- AdamW learning rate : 1e-5- Pretrained Model : SDXL
- LoRA : 256 rank
- Human-in-the-loop : 라운드 별 약 10k iteration, 16 batch size
EXPERIMENTS
Qualitative Results


Conditional Layer Generation

Iterative Generation
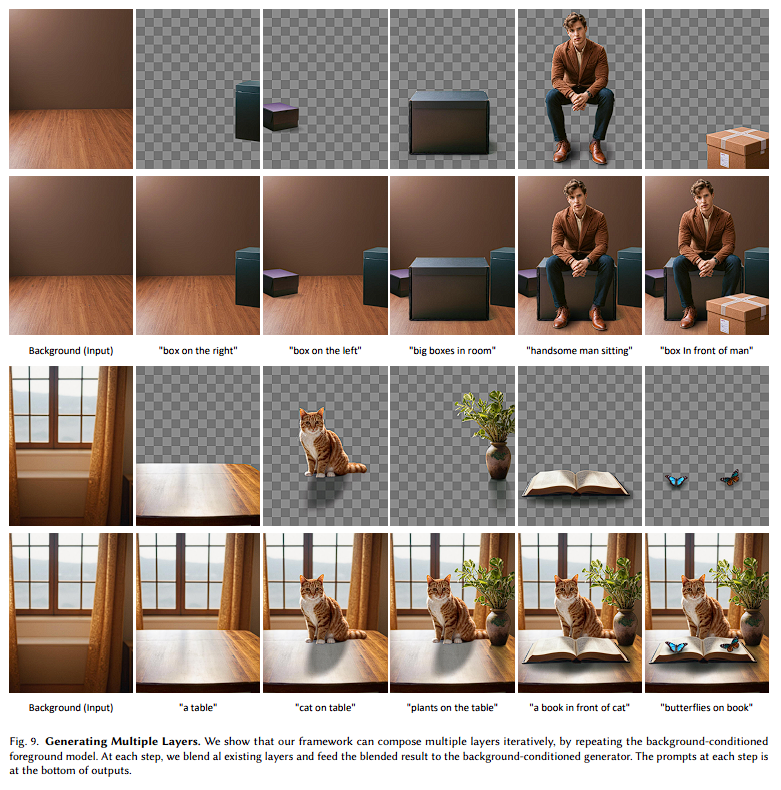
Controllable Generation

Ablation Study


Fig.12 : 더 복잡한 워크 플로우를 위한 대안 아키텍처를 제시
-
UNet에 0으로 초기화 된 채널을 추가
-
VAE를 사용하여 (Latent Transparency를 포함하거나 포함하지 않고) 전경, 배경 또는 레이어 조합을 조건으로 인코딩
-
이를 바탕으로 모델을 학습시켜 foreground / background / blended 이미지를 생성
Relationship to Image Matting
Raw RGBA Channels

Fig. 14 : RGB 채널을 "bleeding" 색상으로 패딩하여 aliasing을 피할 수 있다.
Limitations

Fig 17. Limitation
- 생성된 Transparent 이미지가 그림자 없이 생성되는 경우, 전경과 조화롭게 블랜딩되는 배경을 생성하기 어려움
- 배경을 조건으로 사용하여 전경을 생성하도록 유도하면 조화로운 블랜딩을 어느정도 강제할 수 있으나, 배경에 존재하는 조명이 투명 객체에 영향을 미치게 되어 생성된 전경 이미지의 재사용 가능성을 낮춘다.
Conclusion
이 논문은 "latent transparency"라는 새로운 접근법을 소개하며, 이를 통해 개별 투명 이미지 또는 일관된 투명 레이어 시리즈를 생성할 수 있다.
핵심 개념
투명 알파 채널을 Stable Diffusion의 잠재 분포(latent distribution)에 인코딩.
잠재 공간에 추가된 오프셋을 조정함으로써 대규모 이미지 확산 모델의 고품질 출력을 보장.
데이터 및 훈련
100만 쌍의 투명 이미지 레이어를 포함한 데이터셋을 사용하여 모델을 훈련.
데이터는 human-in-the-loop 방식으로 수집.
응용 분야
전경/배경 조건에 따른 레이어 생성.
레이어 결합.
구조 제어를 통한 레이어 생성 등 다양한 응용 분야 제시.
사용자 연구 결과
대다수의 경우, 사용자는 기존 방법(예: 생성 후 매팅 방식)보다 본 방법으로 생성된 투명 콘텐츠를 선호.
생성된 투명 이미지의 품질은 상업용 스톡 이미지와 비교해도 뒤처지지 않음.
이 방법은 이미지 생성과 투명도 표현에서 새로운 가능성을 열며, 고품질의 투명 이미지를 효과적으로 생성할 수 있는 실용적인 접근법을 제공한다.
Questions
- Base 모델 학습시에는 주로 배경이 아닌 전경 이미지만을 학습에 사용된 것 같다. 이게 이후 Multi Layer 모델을 학습할 때 배경 생성의 낮은 성능을 유도하게 되는 것은 아닌가?
- Multi Layer Dataset Prepare에서 Background Layer 생성시에 erode를 수행한 이유?
- 본문 3절에서 multi-layer 모델에서 Foreground-Condition 혹은 Background-Condition 방식으로 동작하는 법은 Clear Latent를 사용하면 가능하다고 했으나, 공식 Repository에서 제공되는 Layer Diffusion 모델의 가중치 파일은 각각 다른걸로 확인되는데 이유는?
- Fig 12를 제안하는 이유와 학습 방식에 대한 설명이 불친절한 느낌을 받음. 특히, Two-Stage background conditioned pipeline에서 마지막에 blend 이미지와 foreground 이미지를 구하고 다시 blending을 수행하는 이유가 무엇인지 의문
