Lumiere: A Space-Time Diffusion Model for Video Generation

Abstract
논문에서는 Lumiere라는 Text-to-Video diffusion model을 소개한다. Lumiere는 Space-Time U-Net architecture를 통한 single pass로 전체 비디오를 한번에 생성하는 방식으로 기존 video model의 key frame 합성 및 temporal super resolution 방식보다 temporal consistency를 잘 유지할 수 있다고 주장한다.
Introduction
이미지 생성 모델은 최근 많은 발전을 이루었지만, Text-to-Video(T2V) 모델은 여전히 오류에 민감하고, 추가된 temporal dimension으로 인한 메모리 및 계산 복잡성으로 인해 제한이 존재한다.
기존 T2V 모델은 일반적으로 base model로 key frame들을 생성하고, temporal super resolution(TSR) 모델을 통해 key frame 간의 누락된 frame을 보강하는 방식으로 설계되었다. 이 방식의 경우 메모리 측면에서 효율적이지만 다음과 같은 문제점이 존재.
i) base model은 과도하게 downsampling된 key frame을 생성하므로 빠른 모션의 상황에서 temporal aliasing이 발생하여 모호한 상황이 발생한다.
ii) TSR 모듈은 고정된 작은 temporal context window로 제한되어 비디오 전체에 걸친 temporal aliasing ambiguity를 해결하기 어렵다.
iii) 단계적으로 학습을 하게 되면, 학습에 사용된 데이터 셋의 도메인 차이가 발생하게 된다. 여기서, TSR 모듈의 경우는 실제 저해상도의 비디오로 학습되는데 실제 추론시에는 생성된 key frame을 보간하는데 사용되어 오류가 누적된다.
이 문제를 해결하기 위해 논문에서는 Space-Time U-Net(STUNet) 아키텍처를 제안하여 공간 및 시간에서 신호를 downsampling한 뒤 대부분의 연산을 수행한다. 그 결과, 이전 작업에 비해 일관된 모션을 생성할 수 있었고, 단일 모델로 80frame을 16fps로 생성했다. 여기서, 이전 모델들은 아키텍처에 spatial downsampling 및 upsampling만 포함하고 고정된 time resolution을 유지했다는 점을 문제삼았다.

논문에서 제안하는 Lumiere pipeline은 위와 같다. 여기서 기존에는 Spatial Super Resolution(SSR) 솔루션을 생성된 비디오 프레임에 대해서 겹치지 않는 segment로 나눈 후 temporal window를 통해 해상도를 높이고 결과를 합치는 방식을 적용했지만, temporal window의 외곽에서 일관성이 부족한 문제가 발생해서 논문에서는 multi diffusion을 temporal domain으로 확장하여 해결했다.
Lumiere
제안하는 프레임워크는 베이스 모델과 SSR 모델로 구성된다. Fig 3(b)와 같이 베이스 모델은 낮은 해상도에서 전체 클립을 생성하고, temporally-aware SSR 모델을 통해 공간적으로 upsampling하여 고해상도 비디오를 생성한다.
Space-Time U-Net (STUNet)

논문에서는 input data를 시간과 공간 차원에서 모두 downsampling하고, 대부분의 연산을 수행하는 STUNet을 제안한다. 모델 구조는 위와 같다. 기존 T2I 아키텍처에 temporal block을 교차로 배치하고, pretrained spatial resizing module 뒤에 temporal downsampling과 upsampling module을 삽입한다.
temporal block은 temporal convolution(Fig 4.b)과 temporal attention(Fig 4.c)을 포함한다. temporal convolution은 3D convolution에 비해 비선형성을 증가시킬 수 있고, 1D convolution에 비해 표현력을 증가시킬 수 있는 장점이 있다. temporal attention의 계산 비용은 frame 수의 제곱에 비례하기 때문에 coarest resolution에서 적용된다. 이를 통해 저차원 feature map에서 동작하므로 여러 temporal attention을 적용할 수 있는 장점이 있다.
Video LDM에서 제안하는 것과 같이 pretrained T2I 모델의 가중치는 고정하고, 추가된 가중치만 학습한다. 여기서, common inflation 방식은 초기화시에 T2V 모델이 pretrained T2I와 동일하도록 보장하는데 Lumiere는 temporal downsampling과 upsampling 모듈로 인해 이를 만족하기 어려웠고, 경험적으로 초기화후에 nearest-neighbor down-upsampling을 수행하도록 하여 좋은 결과를 얻을 수 있음을 확인했다.
Multidiffusion for Spatial-Super Resolution
메모리 제약으로 인해, SSR 모델은 video의 short segment에서만 동작한다. temporal boundary artifact를 피하기 위해 논문에서는 Multidiffusion을 도입하여 temporal axis를 따라 temporal segment 사이를 smoothing했다.
이 과정은 먼저, input video 를 overlapping segments 로 분리한다. 여기서, 는 i번째 segment를 의미한다. 그리고 SSR prediction 를 조화시키기 위해 optimization를 다음과 같이 정의했다.

Application

Stylized Generation
기존 연구에서 특정 스타일을 생성할 수 있는 사용자 정의된 T2I 모델을 대체하면 원하는 스타일의 비디오를 생성할 수 있었다. 하지만, 논문에서는 이러한 경우 temporal layer가 finetuning된 spatial layer와 크게 차이나기 때문에 종종 왜곡이 발생한다고 주장했다. 이를 해결하기 위해 finetuning된 T2I 모델과 기존 T2I 모델에 대해서 선형 보간을 적용했다.

Conditional Generation
여기서는 image 혹은 mask의 추가적인 입력으로부터 conditioned video generation을 소개한다. 논문에서는 단순하게 text prompt와 noisy video 에 추가적으로 mask conditioning video 와 binary mask 를 결합하고 first convolution layer의 channel dimension을 3에서 7로 수정하고, 에 기반하여 의 noise를 제거하도록 finetuning했다.
Image-to-Video
여기서는 에 대해서 첫 프레임에 이어서 나머지는 공백 frame으로 할당하고, 에 대해서는 첫 프레임은 1로 채우고 나머지는 0으로 채워서 위와 동일하게 video를 생성한다.

Inpainting
Video Inpainting의 condition은 사용자가 제공한 비디오 와 비디오에서 생성할 영역을 표현하는 으로 구성된다.

Cinemagraphs
논문에서는 특정 영역에 대해서만 모션을 생성할 수 있는 방법에 대해서도 제안했다. 는 전체 비디오를 복제한 입력 이미지이며, 은 첫 프레임은 전체를 1로 설정하고, 이후 프레임은 사용자가 지정한 영역에 대해서만 1로 설정한다.

Evaluation and Comprisons
제안하는 모델은 30M video를 포함한 데이터 셋에서 학습되었고, 각 비디오는 16fps의 80 frame으로 이루어져 있다. base model은 128x128 resolution에서 학습되었고, SSR은 1024x1024 frame을 생성한다. 평가는 UCF101 Dataset에서 zero-shot evaluation protocol을 채택하여 진행했다.
 User Study
User Study
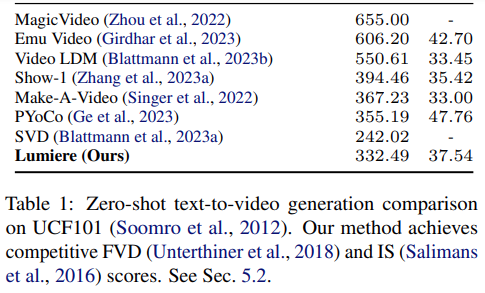 Quantitative Evaluation
Quantitative Evaluation
Conclusion
논문에서는 STUNet을 통해 spatial and temporal up-downsampling module을 통합하여 전체 비디오의 프레임을 생성할 수 있는 모델인 Lumiere를 제안했다. 이를 통해 SOTA 생성 결과를 시연했으며, 제안하는 방법론이 Image-to-Video, Video Inpainting 및 Stylized Generation 등 다양한 응용 분야에 적용 가능함을 보였다.
