
동기
지난 번에 다양한 JPA 문제를 해결하고 비효율적으로 생성되는 쿼리를 최적화해 전체적인 서버 성능이 대폭 향상되었다. 하지만 리뷰 조회 API의 일부 요청의 경우 대폭 향상되었음에도 만족스러운 쿼리 처리 시간에 도달하지 못했다. 다양한 정렬과 필터링을 지원하는 조회 쿼리인만큼 대량의 데이터를 조건절, 정렬 적용하는데 많은 비용이 들고, 특히 리뷰의 분석 결과 중 '청결' 속성이 포함된 리뷰들이나 리뷰의 분석 결과 중 '청결' 속성의 '먼지' 키워드가 포함된 리뷰들과 같이 review 테이블과 연관되었으면서 가장 많은 데이터가 적재된 review_tag 테이블을 사용하는 쿼리들은 기본적으로 존재하는 클러스터링 인덱스와 외래키 인덱스로는 인덱스를 타지 않아 다른 쿼리 대비 80배 정도 더 긴 요청 처리 시간이 소요되었다. 이에 따라 쿼리를 하나하나 프로파일링해보며 수정하고 인덱스를 적용해 성능을 개선해보자.
성능 테스트
대시보드 API 성능을 측정하는 과정에서 연단위의 데이터를 생성했기 때문에, 성능을 다시 측정해야한다. 테스트 데이터치고는 조금 많은 데이터가 들어있지만 리뷰 54만 개는 프로덕션에서 상정할 수 있는 스케일이라고 생각한다.
테스트 데이터
- 여행상품: 30 (각 카테고리 10개씩, 숙소, 식당, 렌터카)
- 예약: 540,000 (카테고리 별 180,000)
- 여행상품 마다 18,000개의 예약
- 리뷰: 540,000 (카테고리 별 180,000)
- 모든 예약에 리뷰 작성
- 리뷰 태그: 2,700,000 (카테고리 별 900,000)
- 각 리뷰당 5개의 리뷰 태그
테스트 결과
첫 성능 테스트에 비해 4배의 데이터가 들어있기 때문에 모든 요청이 정확히 4배의 시간이 소요되었다. 인덱스를 타지 않고 Full Table Scan하고 있다는 것을 간접적으로도 알 수 있었다. 특히, 2543 ms, 7147 ms는 비정상적인데, 해당 요청들이 리뷰 태그의 속성과 키워드를 통해 필터링하는 요청이다. 그럼 해당 요청들을 본격적으로 최적화해보자.
2023-10-27 04:19:58.851 INFO 99446 --- [ Test worker] PERFORMANCE : ===== 성능 테스트 시작 =====
2023-10-27 04:19:58.851 INFO 99446 --- [ Test worker] PERFORMANCE : (4/5) 리뷰 API
2023-10-27 04:19:59.152 INFO 99446 --- [o-auto-1-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'
2023-10-27 04:19:59.152 INFO 99446 --- [o-auto-1-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
2023-10-27 04:19:59.152 INFO 99446 --- [o-auto-1-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 0 ms
2023-10-27 04:20:01.909 WARN 99446 --- [o-auto-1-exec-1] PERFORMANCE : uri: '/api/widget/v1/goodchoice.kr/products/123/reviews', method: 'GET', 요청 처리 시간: 2741.021375 ms, 쿼리 개수: 14, 쿼리 시간: 2543.819333 ms
2023-10-27 04:20:09.110 WARN 99446 --- [o-auto-1-exec-2] PERFORMANCE : uri: '/api/widget/v1/goodchoice.kr/products/123/reviews', method: 'GET', 요청 처리 시간: 7177.475416 ms, 쿼리 개수: 14, 쿼리 시간: 7147.840791 ms
2023-10-27 04:20:09.152 WARN 99446 --- [o-auto-1-exec-3] PERFORMANCE : uri: '/api/widget/v1/goodchoice.kr/products/123/reviews', method: 'GET', 요청 처리 시간: 31.841500 ms, 쿼리 개수: 14, 쿼리 시간: 18.417707 ms
2023-10-27 04:20:09.492 WARN 99446 --- [o-auto-1-exec-4] PERFORMANCE : uri: '/api/widget/v1/goodchoice.kr/products/123/reviews', method: 'GET', 요청 처리 시간: 332.011875 ms, 쿼리 개수: 14, 쿼리 시간: 314.414834 ms
2023-10-27 04:20:09.638 WARN 99446 --- [o-auto-1-exec-5] PERFORMANCE : uri: '/api/widget/v1/goodchoice.kr/products/4e16aa67-a2fd-4c92-ad11-775a3ad190e4/statistics/reviews', method: 'GET', 요청 처리 시간: 139.288167 ms, 쿼리 개수: 2, 쿼리 시간: 112.839875 ms
2023-10-27 04:20:10.348 WARN 99446 --- [o-auto-1-exec-6] PERFORMANCE : uri: '/api/widget/v1/goodchoice.kr/products/4e16aa67-a2fd-4c92-ad11-775a3ad190e4/statistics/tags', method: 'GET', 요청 처리 시간: 701.198125 ms, 쿼리 개수: 2, 쿼리 시간: 689.250418 ms최적화
원인 분석
문제가 되는 해당 요청은 "goodchoice.kr" 도메인에 id가 123인 여행 상품에 등록된 리뷰 중 청결(CLEANNESS) 태그를 가진 리뷰들을 10개 조회하는 요청이다.
GET /api/widget/v1/goodchoice.kr/products/123/reviews
{"property": "CLEANNESS"}따라서 다음과 같은 쿼리들로 구성되어 있다.
1. 조건을 만족하는 review들을 조회하는 쿼리
2초 가량 걸리는 요청에서 1683ms가 소요되는 쿼리로서, 성능 저하의 주요 원인이 되는 쿼리이다. 특히 리뷰에 포함된 태그들 중 하나라도 CLEANNESS가 포함되었다면 조회라는 쿼리를 QueryDSL any()를 통해 구현하였는데 서브쿼리로서 실행된다. 쿼리 실행 계획을 보면 <subquery2>와 reviewtags3_이 인덱스도 없이 엄청난 양의 rows를 다루고 있다. 따라서 이 부분이 최적화 포인트 1이다.
select
review0_.review_id as review_i1_8_,
review0_.created_at as created_2_8_,
review0_.updated_at as updated_3_8_,
review0_.content as content4_8_,
review0_.negative_tags_count as negative5_8_,
review0_.polarity as polarity6_8_,
review0_.positive_tags_count as positive7_8_,
review0_.rating as rating8_8_,
review0_.title as title9_8_
from
review review0_
where
exists (
select
1
from
review_tag reviewtags3_
where
review0_.review_id=reviewtags3_.review_id
and reviewtags3_.property=?
)
order by
review0_.created_at desc limit ?
10 rows retrieved starting from 1 in 1 s 683 ms (execution: 1 s 667 ms, fetching: 16 ms)
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | review0_ | null | ALL | PRIMARY | null | null | null | 448427 | 100 | Using filesort |
| 1 | SIMPLE | <subquery2> | null | eq_ref | <auto_distinct_key> | <auto_distinct_key> | 8 | reviewmate.review0_.review_id | 1 | 100 | null |
| 2 | MATERIALIZED | reviewtags3_ | null | ALL | FKea2voymuynf2rmdx7ph30cwoe | null | null | null | 2177808 | 10 | Using where |
2. 리뷰의 작성자 이름을 위해 연관된 reservation, customer 테이블을 그래프 탐색하는 쿼리
review 테이블에 지연 로딩되지만 작성자의 이름을 알기 위해 2개의 테이블을 그래프 탐색하기 위해 (리뷰 개수 * 2) 만큼의 쿼리가 발생되고 있다. 하지만 review 테이블에 작성자 이름을 비정규화하지 않는 이상 불가피한 탐색이며, 본 포스팅과 무관하지만 fetch join을 통해 쿼리 개수를 줄이는 시도도 하였지만, reservation과 customer에 있는 많은 컬럼들이 불필요하게 조회되는 것이 오히려 많은 시간일 소모시켰다. 이 쿼리들은 시간도 134 ms로 준수하므로, 넘어가도록 하자.
select
reservatio0_.reservation_id as reservat1_7_0_,
reservatio0_.created_at as created_2_7_0_,
reservatio0_.updated_at as updated_3_7_0_,
reservatio0_.customer_id as customer7_7_0_,
reservatio0_.end_date_time as end_date4_7_0_,
reservatio0_.live_feedback_id as live_fee8_7_0_,
reservatio0_.live_satisfaction_id as live_sat9_7_0_,
reservatio0_.partner_custom_id as partner_5_7_0_,
reservatio0_.review_id as review_10_7_0_,
reservatio0_.start_date_time as start_da6_7_0_,
reservatio0_.travel_product_id as travel_11_7_0_
from
reservation reservatio0_
where
reservatio0_.review_id=?
-- X 10
select
customer0_.customer_id as customer1_0_0_,
customer0_.created_at as created_2_0_0_,
customer0_.updated_at as updated_3_0_0_,
customer0_.kakao_id as kakao_id4_0_0_,
customer0_.name as name5_0_0_,
customer0_.partner_company_id as partner_8_0_0_,
customer0_.partner_custom_id as partner_6_0_0_,
customer0_.phone_number as phone_nu7_0_0_
from
customer customer0_
where
customer0_.customer_id in (
?, ?, ?, ?, ?, ?, ?, ?, ?, ?
)10 rows retrieved starting from 1 in 134 ms (execution: 111 ms, fetching: 23 ms)
3. Pagination의 totalCount를 위해 조건에 만족하는 review들을 카운팅하는 쿼리
IN 쿼리로 잘 최적화되어 있다.
select
count(review0_.review_id) as col_0_0_
from
review review0_
where
review0_.review_id in (
? , ? , ? , ? , ? , ? , ? , ? , ? , ?
)4. 조회된 review와 연관된 review_tag들의 데이터를 조회하기 위한 추가 쿼리
response DTO를 만드는 과정에서 요청되는 추가 조회 쿼리지만, 마찬가지로 IN 쿼리로 잘 최적화되어 있다.
select
reviewtags0_.review_id as review_i9_10_1_,
reviewtags0_.review_tag_id as review_t1_10_1_,
reviewtags0_.review_tag_id as review_t1_10_0_,
reviewtags0_.created_at as created_2_10_0_,
reviewtags0_.updated_at as updated_3_10_0_,
reviewtags0_.end_index as end_inde4_10_0_,
reviewtags0_.keyword as keyword5_10_0_,
reviewtags0_.polarity as polarity6_10_0_,
reviewtags0_.review_id as review_i9_10_0_,
reviewtags0_.property as property7_10_0_,
reviewtags0_.start_index as start_in8_10_0_
from
review_tag reviewtags0_
where
reviewtags0_.review_id in (
?, ?, ?, ?, ?, ?, ?, ?, ?, ?
)개선
select
review0_.review_id as review_i1_8_,
review0_.created_at as created_2_8_,
review0_.updated_at as updated_3_8_,
review0_.content as content4_8_,
review0_.negative_tags_count as negative5_8_,
review0_.polarity as polarity6_8_,
review0_.positive_tags_count as positive7_8_,
review0_.rating as rating8_8_,
review0_.title as title9_8_
from
review review0_
where
exists (
select
1
from
review_tag reviewtags3_
where
review0_.review_id=reviewtags3_.review_id
and reviewtags3_.property=?
)
order by
review0_.created_at desc limit ?
10 rows retrieved starting from 1 in 1 s 683 ms (execution: 1 s 667 ms, fetching: 16 ms)
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | review0_ | null | ALL | PRIMARY | null | null | null | 448427 | 100 | Using filesort |
| 1 | SIMPLE | <subquery2> | null | eq_ref | <auto_distinct_key> | <auto_distinct_key> | 8 | reviewmate.review0_.review_id | 1 | 100 | null |
| 2 | MATERIALIZED | reviewtags3_ | null | ALL | FKea2voymuynf2rmdx7ph30cwoe | null | null | null | 2177808 | 10 | Using where |
1. review_tag에 (review_id, property) 인덱스 적용
우선, 서브 쿼리가 발생하고 가장 많은 rows를 다루고 있는 review_tag 부분부터 적용해보자. 조건절에서 review_id와 property를 and 로 적용하고 있기 때문에, 복합 인덱스를 순서에 맞게 생성해야 한다. 그렇지 않으면 인덱스를 타지 않는다.
create index review_tag_review_id_property_index on review_tag (review_id, property);10 rows retrieved starting from 1 in 1 s 180 ms (execution: 1 s 166 ms, fetching: 14 ms)
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | review0_ | null | ALL | PRIMARY | null | null | null | 448427 | 100 | Using filesort |
| 1 | SIMPLE | <subquery2> | null | eq_ref | <auto_distinct_key> | <auto_distinct_key> | 8 | reviewmate.review0_.review_id | 1 | 100 | null |
| 2 | MATERIALIZED | reviewtags3_ | null | index | review_tag_review_id_property_index | review_tag_review_id_property_index | 775 | null | 2177808 | 10 | Using where; Using index |
생성한 인덱스가 정상적으로 타졌으며, 인덱스에 필요한 review_tag의 컬럼들이 모두 있으므로 커퍼링 인덱스가 작동한 모습이다. 실제로 1667 ms -> 1166 ms로 30%가 단축됐다.
Extra에 여러 전략들이 생겼는데,
Using where: 스토리지 엔진이 넘겨 준 데이터 (인덱스를 사용해 걸러진 데이터) 중에서 MySQL 앤진이 한번 더 걸려야 되는 조건 (필터링 혹은 체크 조건)이 있다는 표기다. 해당 조건을 만족하는 리뷰 태그가 있는지 확인하기 위해 사용한exist()로 인해 발생되는듯 하지만 불가피하다.
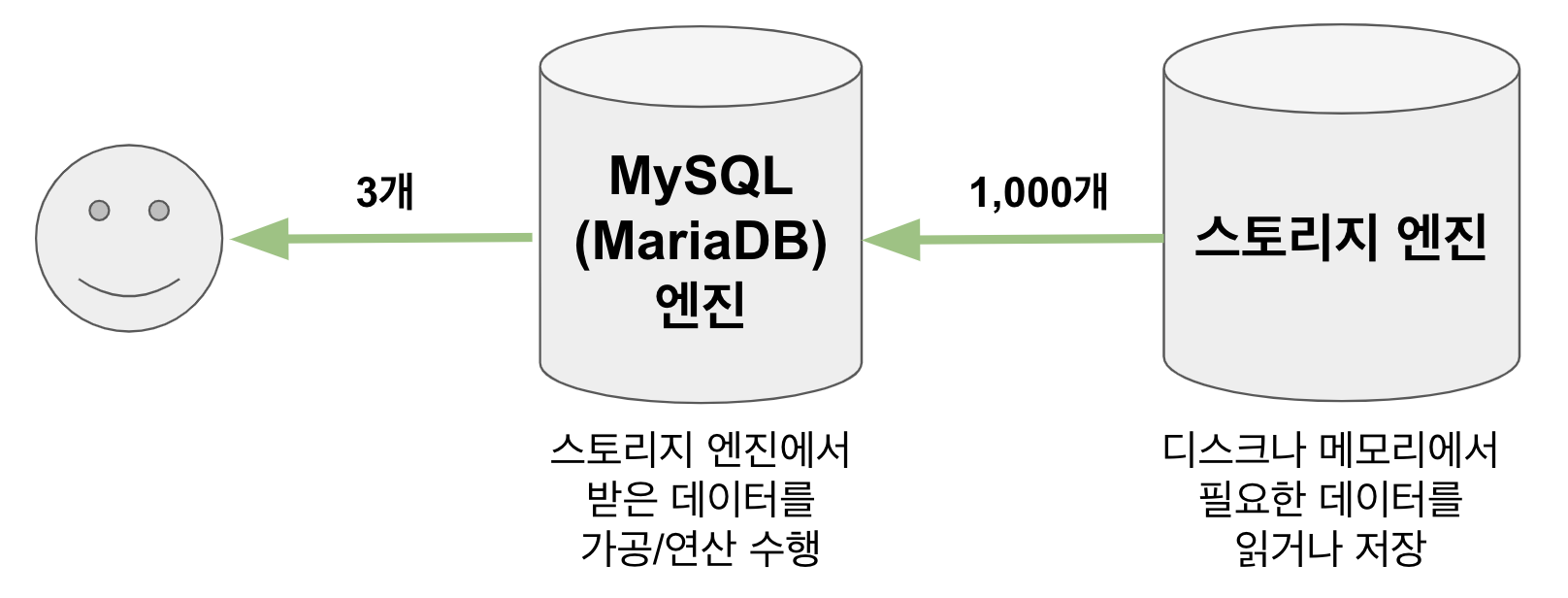
MySQL 내부 구조 - https://jojoldu.tistory.com/474
Using Index: 커버링 인덱스가 적용되었다는 표기로써, 사용되는 컬럼이 순서에 맞게 모두 인덱스에 포함되어 데이터에 직접 접근할 필요가 없어 쿼리 효율이 좋다.Using filesort: 인덱스로 정렬되어 있지 않은 레코드를 정렬되었다는 표기다.ORDER BY created_at로 인한 정렬을 뜻한다.
2. review에 (created_at) 인덱스 적용
review 테이블에 Using filesort가 표기가 있으므로, 정렬에 사용되는 created_at 또한 인덱스를 적용해보자.
create index review_created_at_index on reviewmate.review (created_at);10 rows retrieved starting from 1 in 998 ms (execution: 985 ms, fetching: 13 ms)
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | review0_ | null | index | PRIMARY | review_created_at_index | 9 | null | 10 | 100 | Backward index scan |
| 1 | SIMPLE | <subquery2> | null | eq_ref | <auto_distinct_key> | <auto_distinct_key> | 8 | reviewmate.review0_.review_id | 1 | 100 | null |
| 2 | MATERIALIZED | reviewtags3_ | null | index | review_tag_review_id_property_index | review_tag_review_id_property_index | 775 | null | 2177808 | 10 | Using where; Using index |
마찬가지로 생성한 인덱스가 정상적으로 타졌으며, 1166 ms -> 998 ms로 15%가 단축됐다. 하지만 이번에는 새로운 Extra가 생겼다.
3. Descending index 적용
Backward index scan는 인덱스 리프 노드를 오른쪽 페이지부터 왼쪽으로 스캔하고 있다는 뜻이다. 다른 인덱스들에는 나타나지 않는 실행계획인데, 왜 여기서만 나타날까? 굉장히 간단한데, 그 전에 이와 관련된 용어를 정리해보자

용어 설명 - https://tech.kakao.com/2018/06/19/mysql-ascending-index-vs-descending-index/
- Ascending index : 작은 값의 인덱스 키가 B-Tree의 왼쪽으로 정렬된 인덱스
- Descening index : zms 값의 인덱스 키가 B-Tree의 왼쪽으로 정렬된 인덱스
- Forward index scan : (인덱스 키의 크고 작음에 관계없이) 인덱스 리프 노드의 왼쪽 페이지부터 오른쪽으로 스캔
- Backward index scan : (인덱스 키의 크고 작음에 관계없이) 인덱스 리프 노드의 오른쪽 페이지부터 왼쪽으로 스캔
MySQL 8.0 이전에는 문법만 존재하고 지원하지 않던 Descending index인데, 안그래도 인덱스가 많을수록 트레이드 오프가 큰 인덱스인데 Ascending index를 설정해 스캔 방향만 바꾸면 되지 왜 별도의 인덱스가 존재하냐고 생각할 수 있다. 또한 InnoDB 스토리지 엔진에서 Forward & Backward index scan 페이지 간에는 Double linked list로 이루어져 있으므로, 스캔 방향에 따른 성능 차이는 이해가 되지 않는다. 하지만 Backward가 Forward에 비해서 느릴 수 밖에 없는 2가지 이유가 있다.
1. Forward index scan에게 적합한 페이지 잠금 구조
InnoDB의 B-Tree 리프 페이지는 Double linked list로 연결되어 있기 때문에, 사실 어느 방향이든지 이동 자체는 차이가 없다. 하지만 InnoDB 스토리지 엔진에서는 페이지 잠금 과정에서 데드락을 방지하기 위해 B-Tree의 왼쪽에서 오른쪽 방향(Forward)로만 잠금을 획득하도록 하고 있다. 따라서 Forward index scan에서는 다음 페이지 잠금 획득이 매우 간단하지만, Backward index scan에서 이전 페이지 잠금을 획득하는 과정은 상당히 복잡한 과정을 거쳐야 한다
2. 단방향으로만 연결된 페이지 내의 인덱스 레코드 구조
클러스터링 인덱스의 경우 B-Tree의 리프 노드가 레코드가 아니며 여러 레코드가 하나로 구성된 페이지(Block)가 리프 노드로 구성되어 있다. 따라서 InnoDB 엔진이 특정 레코드를 검색할 때, 검색 대상 레코드(인덱스 레코드)가 저장된 페이지까지는 B-Tree를 이용해서 검색할 수 있다. 일반적으로 16K 사이즈인 인덱스 페이지라면 600여개 이상의 레코드가 저장될 수 있다. InnoDB가 600여개 레코드를 하나씩 다 순차적으로 비교한다면 레코드 검색이 상당히 느릴 것이다.
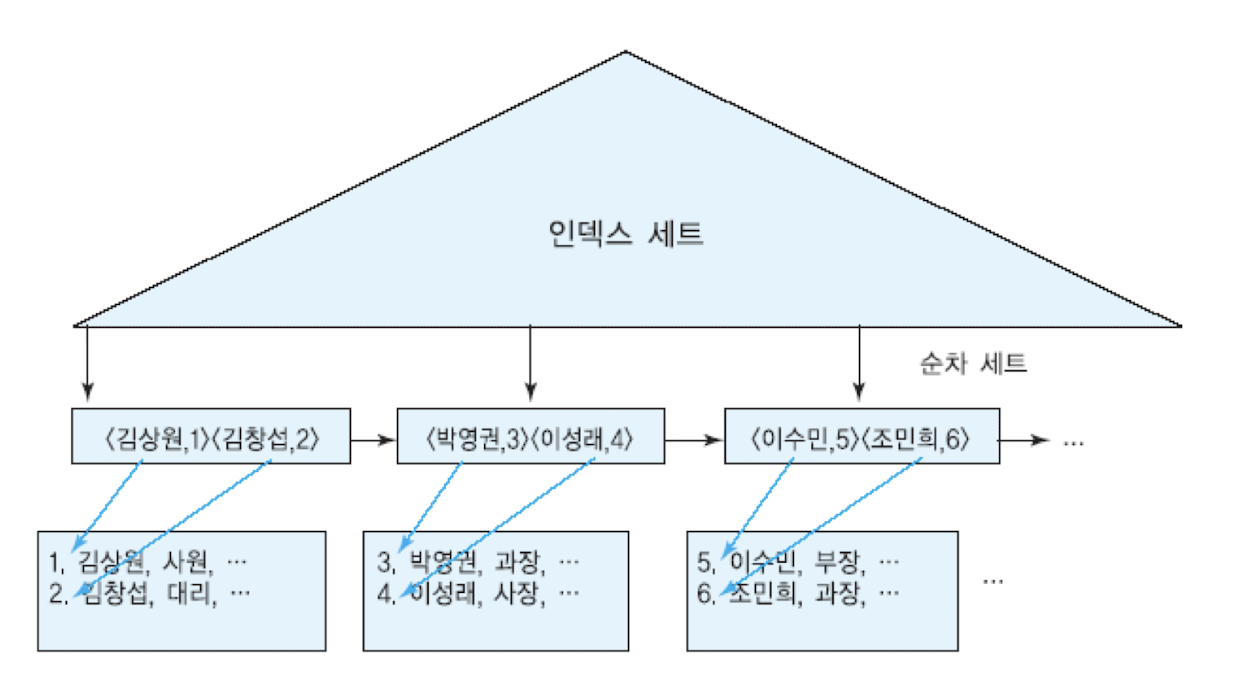
클러스터링 인덱스 구조 - https://velog.io/@kbpark9898/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%EC%9D%B8%EB%8D%B1%EC%8A%A4-B-tree-1
따라서 하나의 페이지 내에서 순차적으로 정렬된 레코드 4~8개 정도씩 묶어서 대표 키(가장 큰 인덱스 엔트리 키 값)를 선정한다. 그리고 이 대표 키들만 모아서 별도의 리스트를 관리하는데, 이를 페이지 디렉토리(Page directory)라고 한다. InnoDB는 특정 키 값을 검색할 때 이진탐색으로 대표 키를 검색하고, 대표 키를 찾으면 그때부터 인덱스 키 값 순서대로 연결된 Linked list를 이용해 대상 레코드를 검색한다.
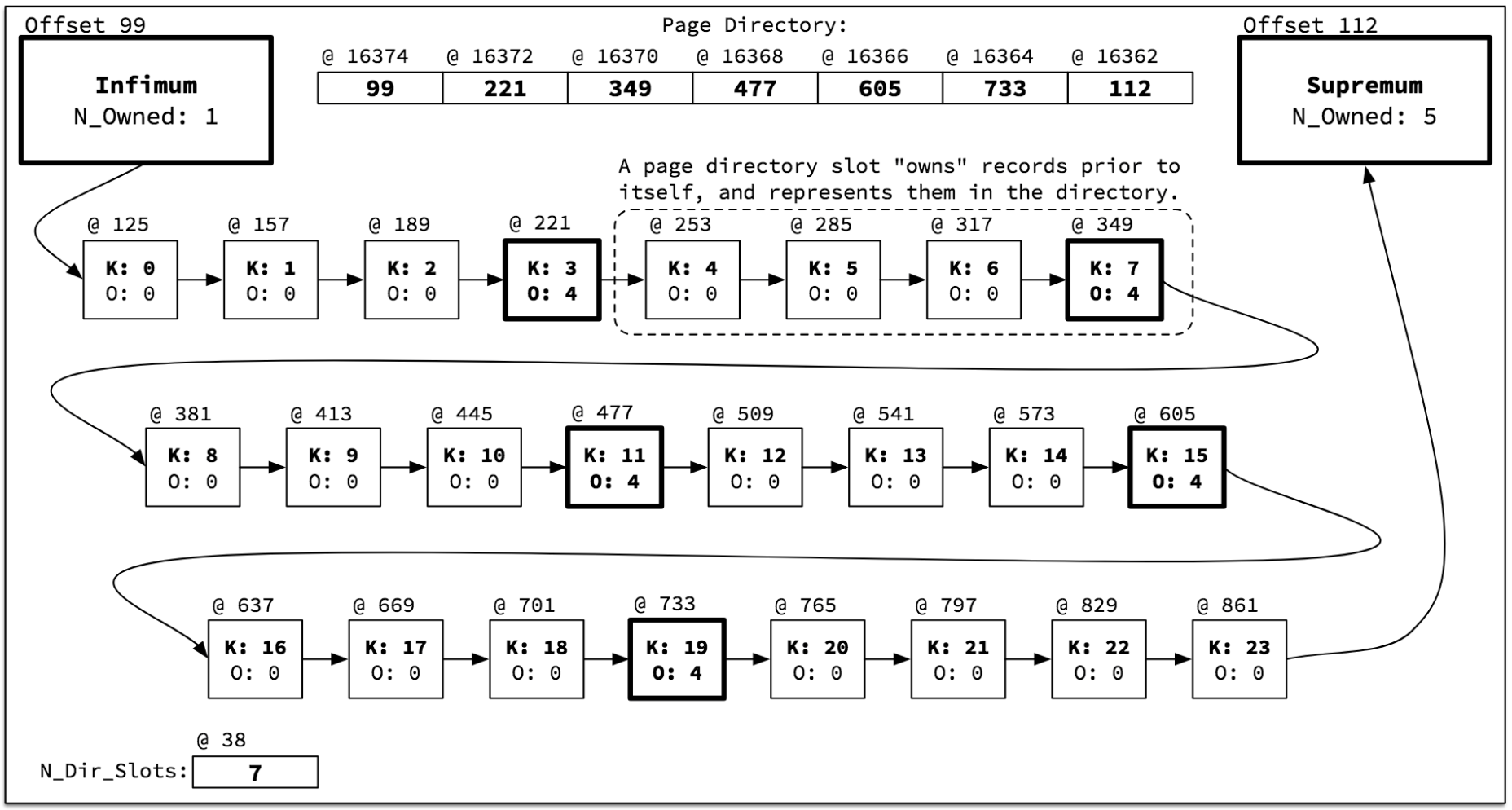
InnoDB page directory 구조 - https://tech.kakao.com/2018/06/19/mysql-ascending-index-vs-descending-index/
문제는 Double linked list로 연결된 B-Tree 리프 페이지 구조와는 달리, 페이지 내부의 레코드들은 Single linked list 구조로 구성되어 있다. 따라서 Ascending index에서 Forward index scan과는 달리 Backward index scan은 온전히 속도의 이득을 보지 못하는 것이다.
또한, 비즈니스 요구사항 상 늘 created_at 정렬은 최신순(desc)만 적용된다.
따라서 created_at 인덱스는 Backward index로 구성해야 한다.
create index review_created_at_index on reviewmate.review (created_at desc);10 rows retrieved starting from 1 in 901 ms (execution: 885 ms, fetching: 16 ms)
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | review0_ | null | index | PRIMARY | review_created_at_index | 9 | null | 10 | 100 | null |
| 1 | SIMPLE | <subquery2> | null | eq_ref | <auto_distinct_key> | <auto_distinct_key> | 8 | reviewmate.review0_.review_id | 1 | 100 | null |
| 2 | MATERIALIZED | reviewtags3_ | null | index | review_tag_review_id_property_index | review_tag_review_id_property_index | 775 | null | 2177808 | 10 | Using where; Using index |
관련해서 조사하는 과정에서 새로 배우는 내용이 많아 서론이 길었지만, 간단하게 적용할 수 있었다. 998 ms -> 901 ms로 10%가 단축되었다.
마무리
| origin | review_tag index | review index | Descending index | |
|---|---|---|---|---|
| 쿼리 처리 시간 | 1667 ms | 1166 ms | 998 ms | 901 ms |
| 이전 대비 단축률 | - | 30% | 15% | 10% |
| 최종 단축률 | 46% 단축 |
Datagrip을 통해 인덱스와 쿼리들을 조작하고 MySQL 실행 계획으로 적용되는 인덱스와 최적화 옵션을 확인하고, 복합 인덱스, 커버링 인덱스, 클러스터링 인덱스를 적용하여 subquery와 where, order by가 포함된 쿼리의 속도를 개선했다. 인덱스를 처음 배우고 적용해보았는데, 단순히 SQL을 잘 짜는 것을 넘어 MySQL 내부 원리를 이해하고 인덱스를 통해 쿼리 실행 동작을 최적화해나가면서 데이터베이스를 더 깊이 이해하고 배울 수 있었다.
참고자료
https://jojoldu.tistory.com/474
https://jojoldu.tistory.com/476
https://jojoldu.tistory.com/158
https://tech.kakao.com/2018/06/19/mysql-ascending-index-vs-descending-index/
https://velog.io/@kbpark9898/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%EC%9D%B8%EB%8D%B1%EC%8A%A4-B-tree-1
