다음 글에 기반하여 작성하였습니다.
위키독스 - Deep Learning Bible - 한국어
Policy Based와 Value Based
Value function을 비교하면 어떤 policy가 더 나은지 비교할 수 있음
Optimal policy = the best policy = the highest value function
어떤 policy가 optimal하면 해당 policy의
- state value
- Q-value (state-action value)
도 optimal하다.
Policy Based Algorithm의 기본 동작
Policy Based -> Optimal PolicyValue Based Algorithm 기본 동작
Value Based -> Optimal Q-Value -> Optimal Policy(후에 다룰 DQN을 위주로 볼 것이므로 Q-Value에 대해서만 정리)
Optimal Q-Value to Optimal Policy
Optimal Q Value를 찾으면 highest Q-Value값을 가지는 action을 선택해 Optimal Policy를 알 수 있음
- 위 그림에서
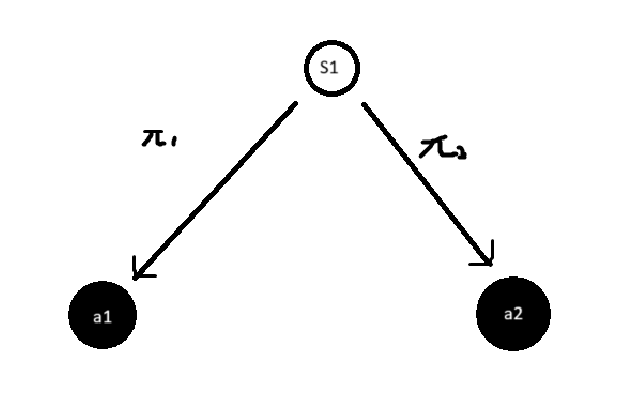
- Optimal Policy는 최상의 action으로 이어지므로 deterministic하다.
- 단, Q-Value가 동일하면 확률적으로 action을 선택한다.
model free 알고리즘의 분류
Look-up Table vs. Function approximator
| Look-up Table | func | |
|---|---|---|
| 특징 | 간단한 알고리즘에 주로 사용 | 복잡한 알고리즘에 주로 사용 (RL) |
| policy based | policy gradient, actor-critic | |
| Q-value based | Monte-Carlo Control, Sarsa, Sarsa-backward, Q-Learning | DQN |
model free 알고리즘의 기본 단계
RL 문제는 대수적 접근이 불가하며, 반복 알고리즘을 사용해야 함
RL은 기본적으로는 아래와 같은 단계를 거친다.
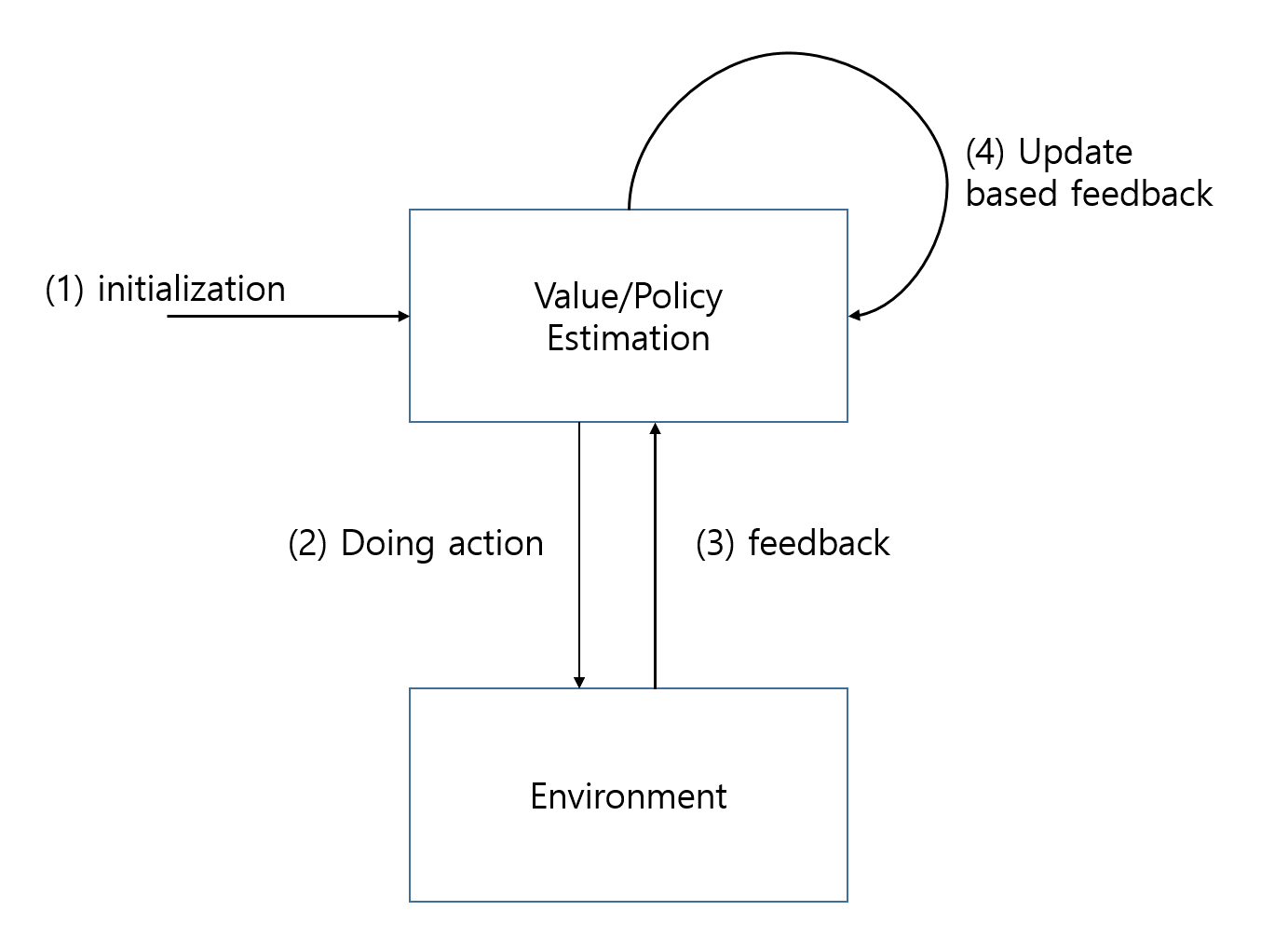
-
초기화
- Table 생성 후 0으로 초기화
- Value-based: Estimated Optimal Q-Value Table 생성
- Policy-based: Estimated Optimal Policy Table 생성
- Table 생성 후 0으로 초기화
-
action 수행
- 사용 가능한 모든 경로를 충분히 시도 후 최상의 옵션을 찾기 위해 탐색과 활용 사이에서 균형을 찾아야 함
- Exploration (탐색)
무작위로 action 선택 후 reward를 관찰함 - Exploitation (활용)
가능한 모든 action이 탐색되면 최대 reward를 내는 최상의 action 선택
- Exploration (탐색)
-
Policy Based
-
Policy Table
policy table에는 주어진 state에 대한 모든 action의 원하는 확률을 알려주는 optimal policy에 대한 지속적 추정이 존재
- 확률에 따라 action을 선택하며, action의 확률이 높을수록 선택될 가능성이 높아짐
-
-
Value Based - -greedy 전략
는 임의의 action을 선탯할 확률로, 의 확률로 최선의 행동을 선택함
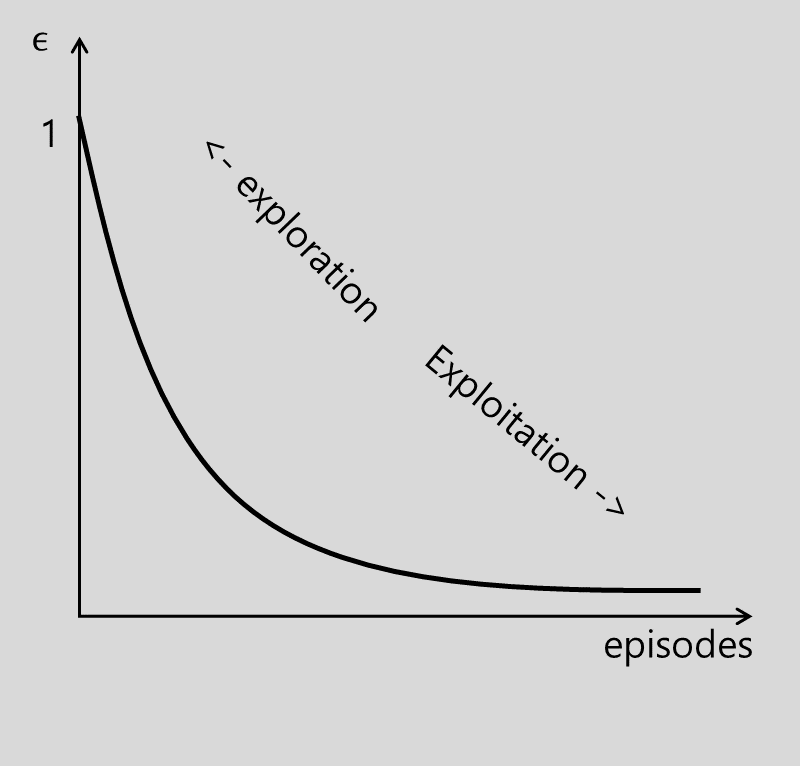
- 사용 가능한 모든 경로를 충분히 시도 후 최상의 옵션을 찾기 위해 탐색과 활용 사이에서 균형을 찾아야 함
-
feedback
action 수행 후 env.에서 reward의 형태로 feedback
-
추정 개선
feedback을 이용해 reward 기반의 estimated optimal policy/value 개선- policy-based
postive reward이면 선택했던 action의 선택 확률을 높임 - value-based
reward 기반으로 Belman Equatrion을 통해 Value를 증가 또는 감소- Q-value
- 오차
- 업데이트
- Q-value
- policy-based
추정치 향상을 위한 다른 방법
다른 방법으로의 변형은 아래와 관련 있음
- Frequency
업데이트 전에 수행된 forward steps 수 - Depth
업데이트를 전달하기 위한 backward step 수 - Formula
업데이트된 추정치를 계산하는 데 사용됨
