이 글은 다음을 참고로 하여 작성함
위키독스 - Depp Learning Bible - 04. Q-Learning(Q-Table
Overview
Q-Table
- State-action 쌍에 대한 Q 값이 정리된 테이블
- 0으로 초기화하여 시작
Q-Table의 업데이트
Model Free Algorithm 참조
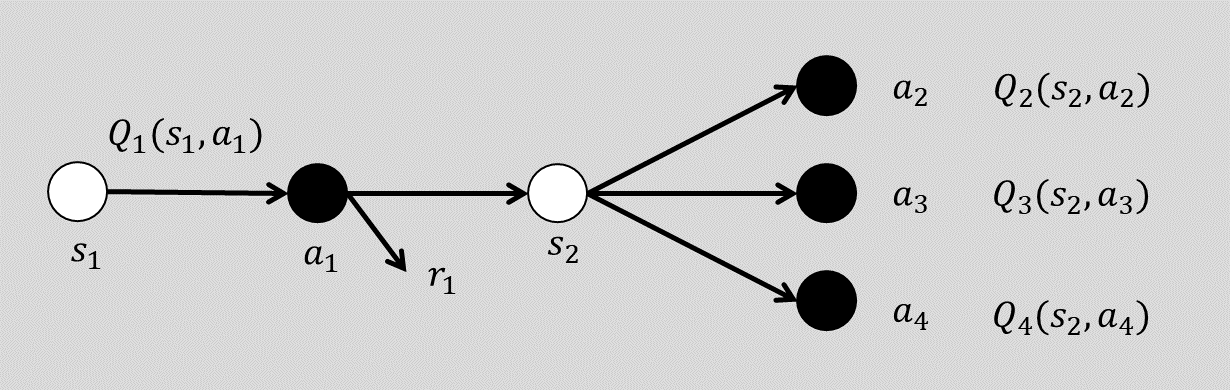
-
추정 Q값() 업데이트를 위해 next Q값 사용
-
가장 높은 Q값을 이용
- 의 업데이트에만 사용할 target action으로 취급
-
target Q 값을 식별했으므로,
- current action
실제 실행하는 action - target action
실제 실행과는 무관하게 현재 Q를 업데이트하기 위한 next의 가장 큰 Q값을 선택
- current action
-
선책은 -greedy policy에 따름
-
off-policy 학습
Q-Table의 생성
- initialization
- 모두 0으로 초기화
- -greedy에 따라 action 선택 후 Q 업데이트 (반복)
- Optimal 값으로 수렴
모든 time step에서 실측 값으로 업데이트 되므로 Q값이 정확해짐
- R = 실측 - maxQ = 추정 -> 실측 - Q - 추정 -> 실측
- episode를 더 많이 진행할 수록 Q-Table이 갱신되어 정확해짐
Optimal Q-Value
- -greedy는 가능한 한 많은 state와 action을 탐색하도록 권장함
- 더 많은 반복과 경로 탐색을 수행할수록 더 나은 Q-Value를 찾기 위해 사용 가능한 모든 옵션을 시도한 것이 됨
optimal Q-Value를 찾을 수 있는 이유
- 더 많은 반복과 경로 탐색을 수행할수록 더 나은 Q-Value를 찾기 위해 사용 가능한 모든 옵션을 시도한 것이 됨

개발자이고 싶은 미니 코딩쟁이... TIL 글을 주로 올립니다.