Llama 사용해보기
from huggingface_hub import notebook_login
notebook_login()를 동작시키려면 허깅페이스의 API KEY가 필요합니다.
그러려면 허깅페이스에서 세팅에 들어가서 키를 발급받아야 됩니다.
일단 저는 READ로 키를 발급 받고 사용해보겠습니다.
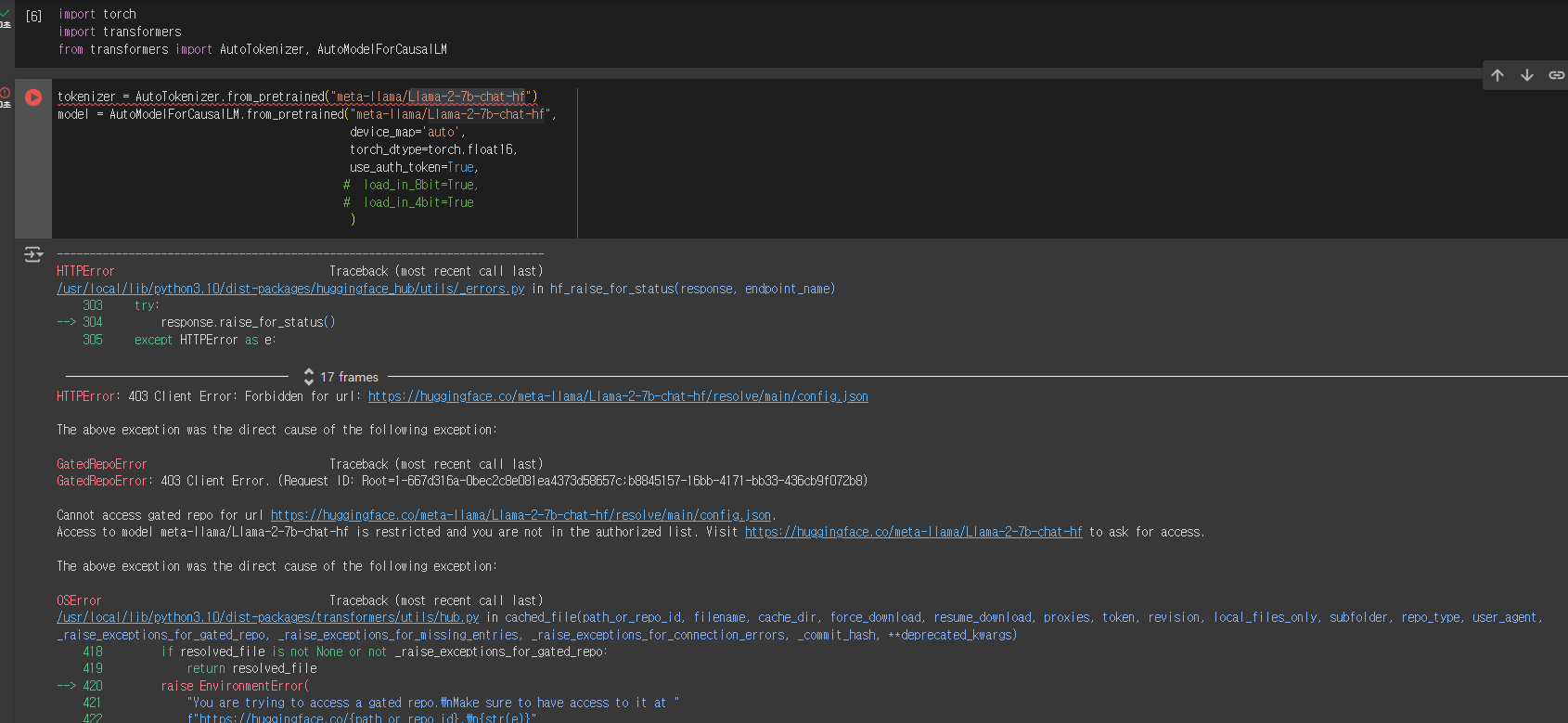
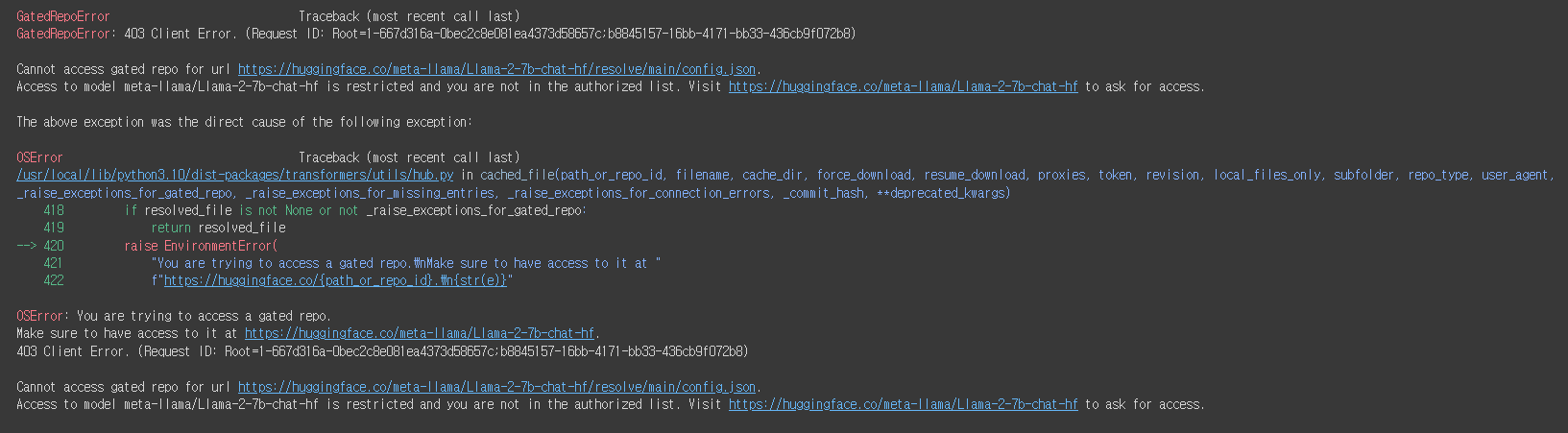
실행을 시키면 이러한 에러가 발생하게 됩니다.
이 에러의 주된 내용을 살펴보면 결론적으로 Visit https://huggingface.co/meta-llama/Llama-2-7b-chat-hf to ask for access. 즉 허깅페이스에서 meta에게 접근 허락을 받아야 된다는 것입니다.
그렇다면 시키는대로 https://huggingface.co/meta-llama/Llama-2-7b-chat-hf를 접속해서 접근 허락을 받도록 하겠습니다.
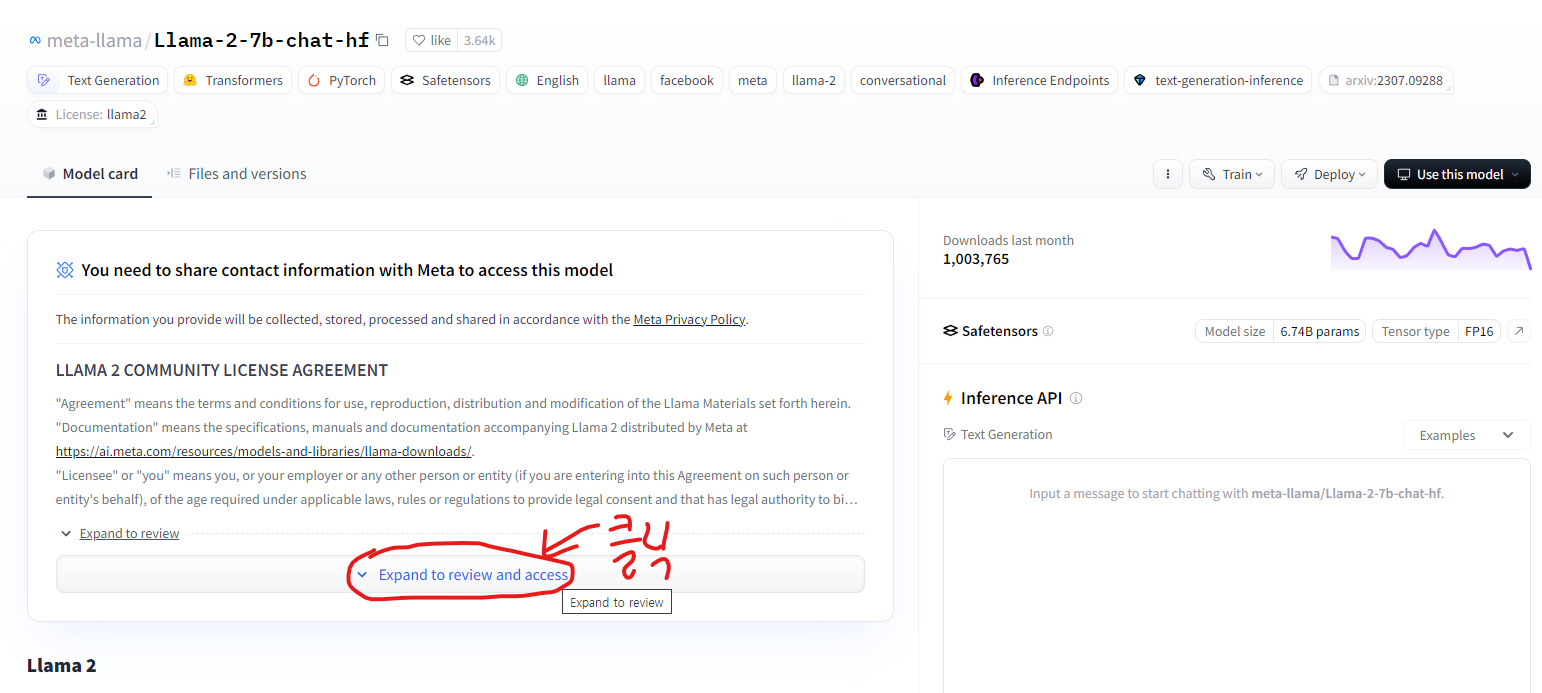
아래의 그림과 같이 Expand to review and access를 클릭합니다.
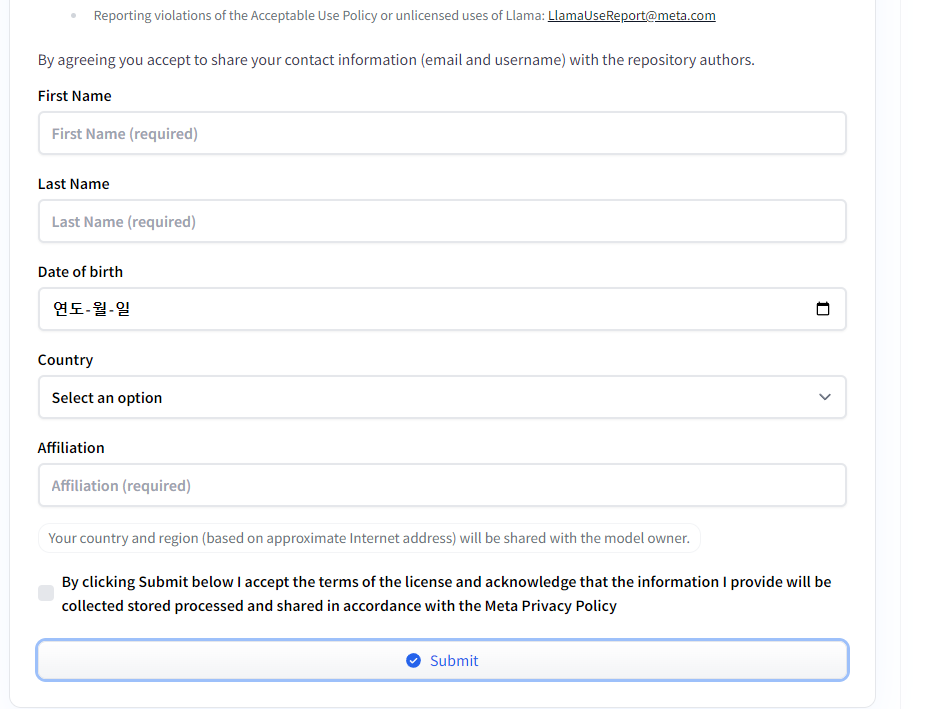
쭉 내리다보면 이렇게 정보를 입력하는 칸이 나오는데, 입력하라는 내용을 입력하고 Submit을 입력하면 됩니다.
Affiliation : individual 를 입력하시면 됩니다. (제 생각에 아직 대학 재학 중이시라면 그냥 대학명을 넣어주시면 될 거 같고 아니라면 그냥 개인 이라고 작성하면 되지 않을까 생각합니다.)
하지만 Submit을 하고나서 다시 실행하게 되면 도 다시 에러 메세지가 나오게 됩니다.
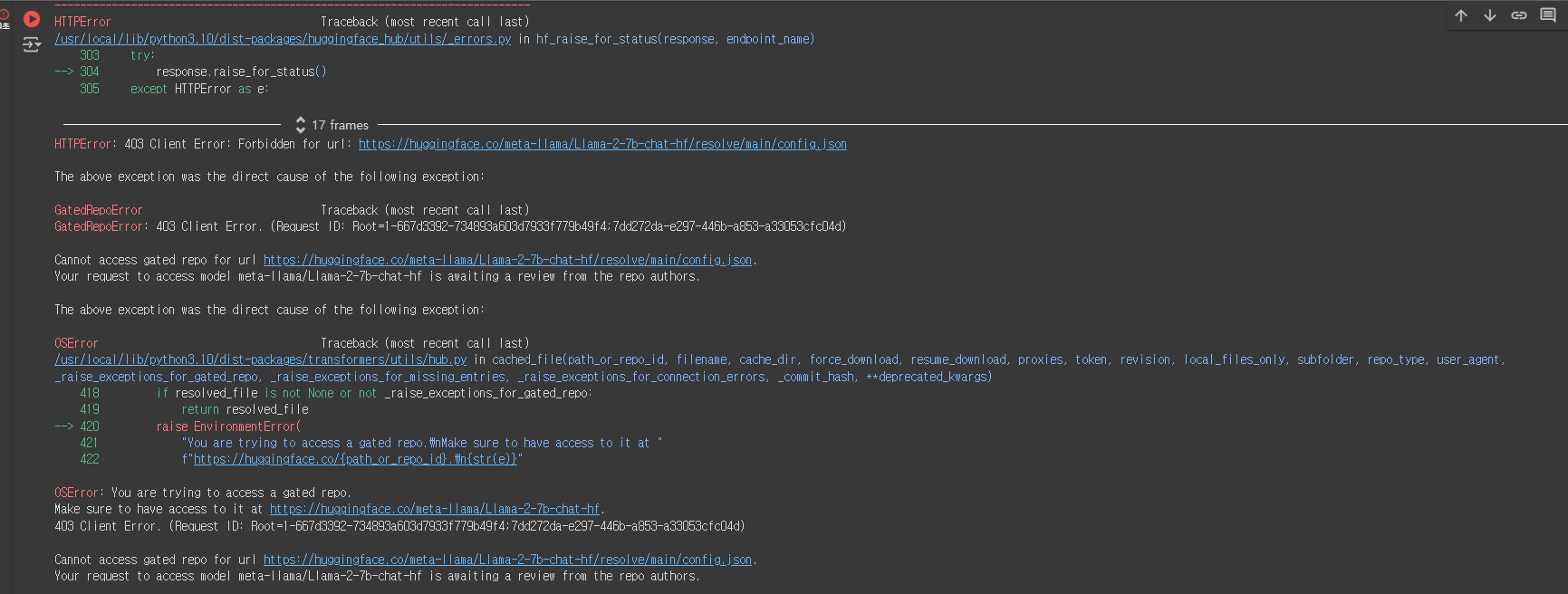
Submit을 한다고 해서 바로 접근 허락이 떨어지는 것은 아닌거 같습니다.
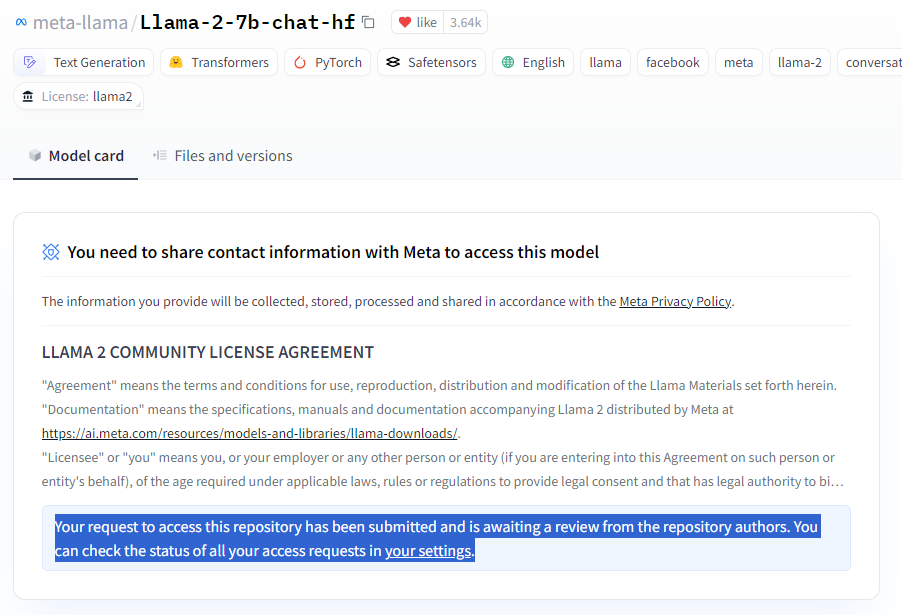
드래그 해놓은 내용을 번역하자면 "이 리포지토리에 액세스하려는 요청이 제출되었으며 리포지토리 작성자의 검토를 기다리고 있습니다. 설정에서 모든 액세스 요청의 상태를 확인할 수 있습니다."
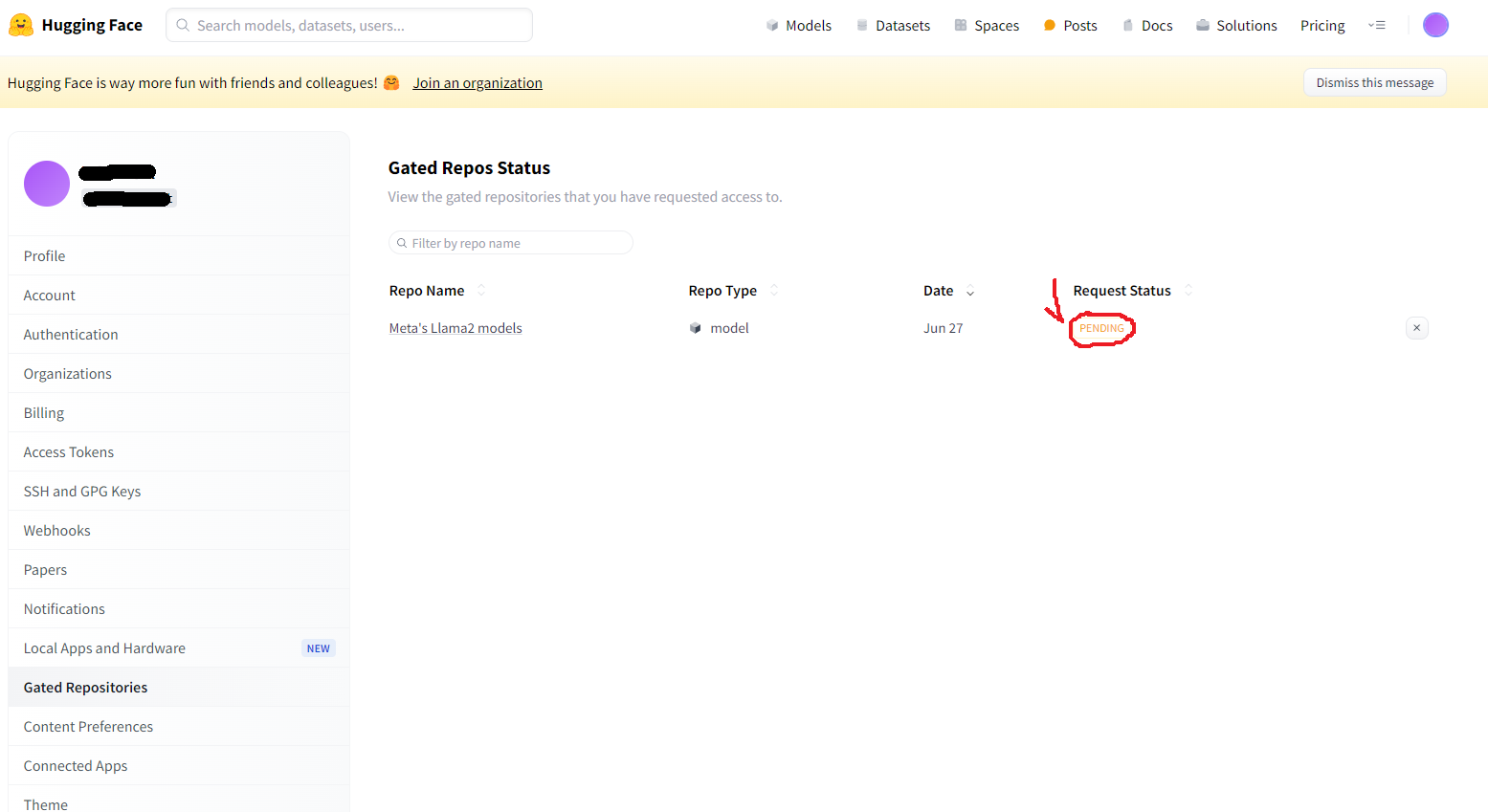
다시 설정에서 Gated Respositories를 클릭해서 현재 상황을 확인할 수 있습니다.
현재 Request Status가 PENDING 이라는 상태에서 알 수 있듯이 아직은 "보류중"인 상태입니다.
나중에 다시 확인해보니 (한 3시간 뒤에 확인한거 같습니다.)
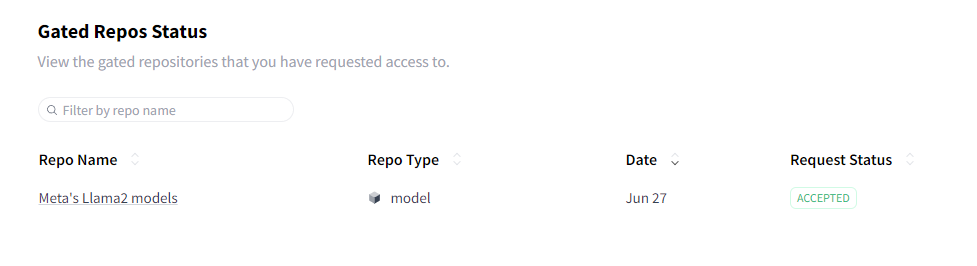
위 사진과 같이 ACCEPTED로 변경되어 있는 것을 확인할 수 있습니다!
수 많은 삽질의 시간들...
여기는 에러를 잡느라 고생한 현장입니다.
굳이 여기를 보시진 않아도 됩니다! 여러분의 시간은 소중하니까요!
이제 다시 코드를 실행해보면 정상적을 동작할 줄 알았으나 또 다시 새로운 에러가 발생했습니다!
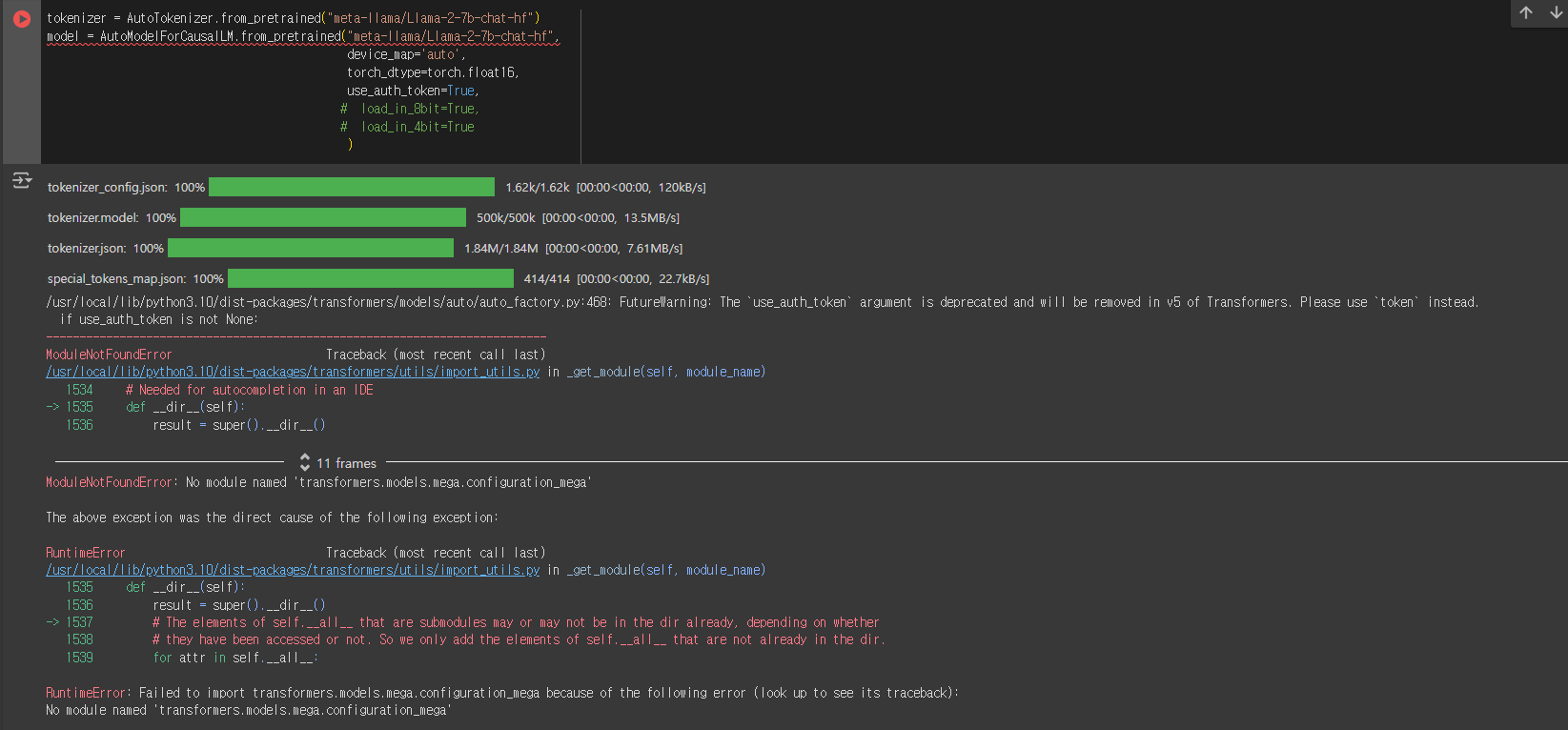
대충 에러 메시지를 보면 이제는 use_auth_token 인자가 더 이상 사용되지 않으며 대신 token을 사용해야 된다고 합니다. 그렇다면 시키는대로 다시 코드를 수정해보도록 하겠습니다.
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf",
device_map='auto',
torch_dtype=torch.float16,
token=True,
# load_in_8bit=True,
# load_in_4bit=True
) 수정을 하고 다시 실행 했음에도 불구하고 또 다시 에러 메세지가 출력 되네요..! 이번에는
RuntimeError: 다음 오류로 인해 transformers.models.mega.configuration_mega를 가져오지 못했습니다(추적을 확인하려면 위를 참조하십시오):
'transformers.models.mega.configuration_mega'라는 이름의 모듈이 없습니다
이러한 에러로 인해서 실행이 되지 않았습니다.
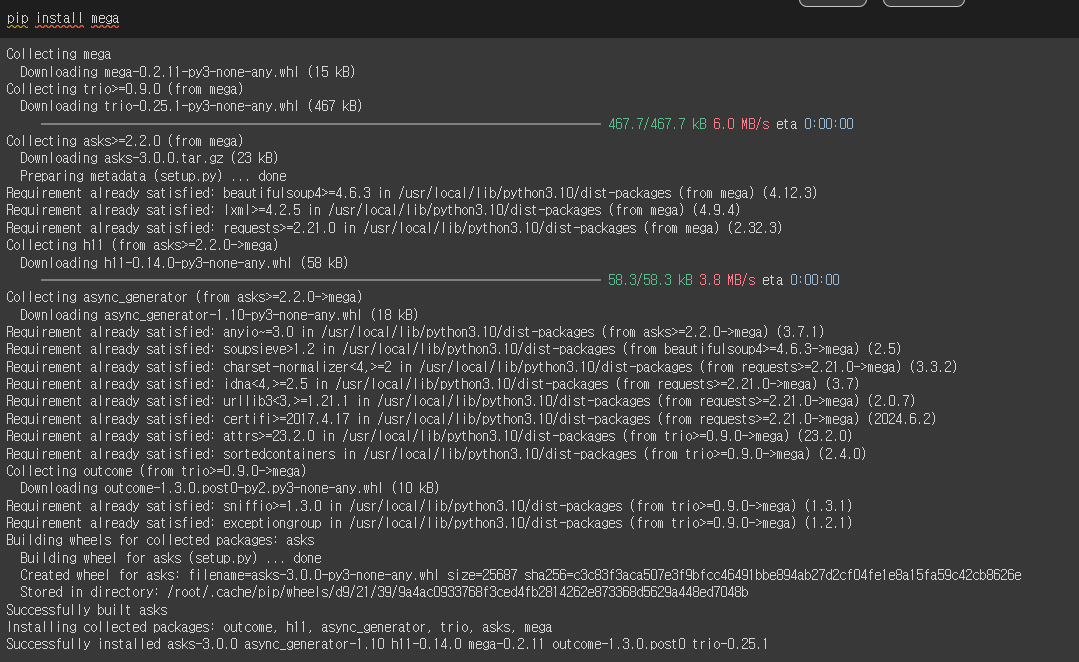
그렇다면 pip install mega를 통해서 설치를 진행한 다음 다시 실행했으나 여전히 동작하지 않았습니다.
아마 다른 곳에서의 문제가 있는거 같은데 이 부분에 대해서 알아보겠습니다.
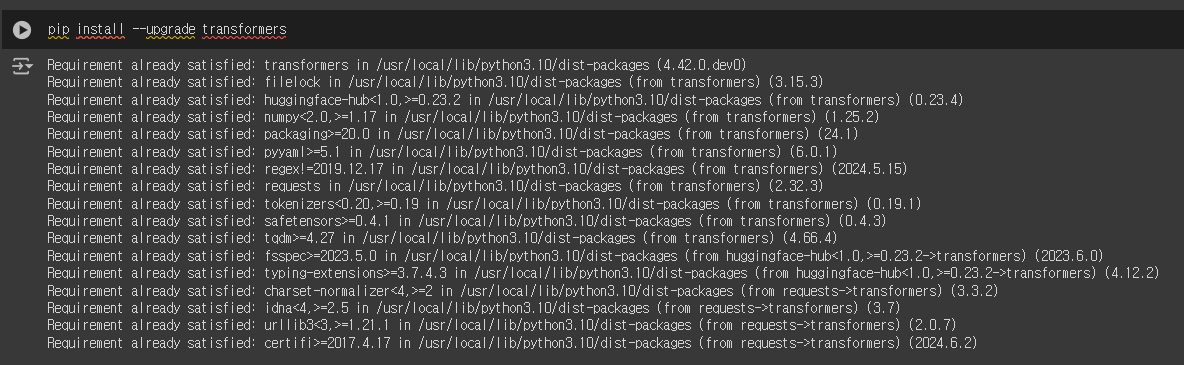
이번에는 trnasformers를 업그레이드 한 후 동작했으나 이 역시 제대로 실행이 되지 않았습니다.
혹시나 캐시 데이터의 문제일까봐 캐시 데이터를 삭제한 뒤 다시 동작을 해봤으나 이 역시 제대로 된 동작을 하지 않았습니다 ㅠㅠ
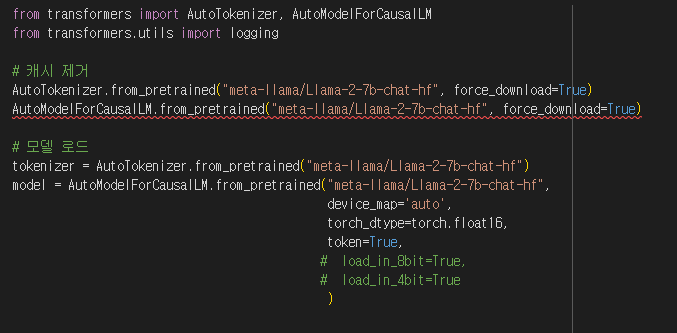
흠... 이 방법에도 다 실패하자 결국에는 그냥 원래 있던 트랜스포머를 제거하고 GitHub에 있는 트랜스포머를 불러오기로 했습니다.
!pip uninstall transformers
!pip install git+https://github.com/huggingface/transformers.git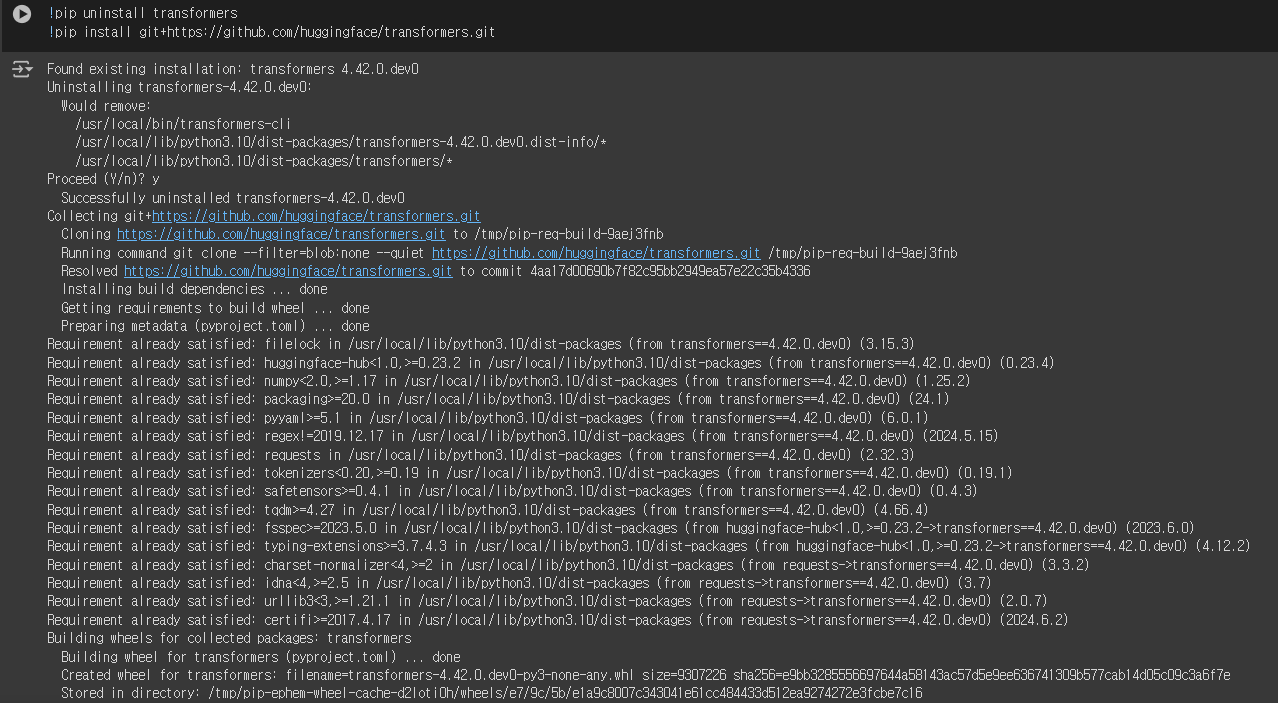
다시 런타임을 실행시켜 줍니다.
여기서부터 보세요!
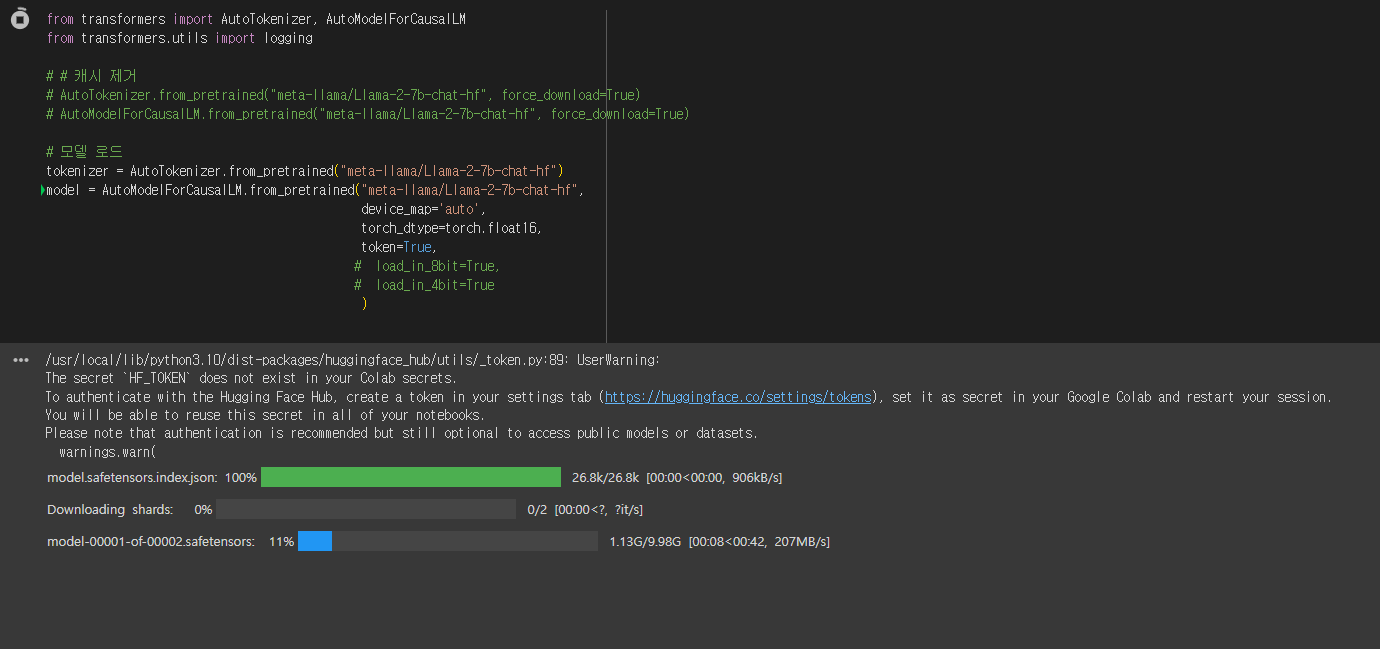
드디어 제대로 된 동작을 하기 시작합니다!
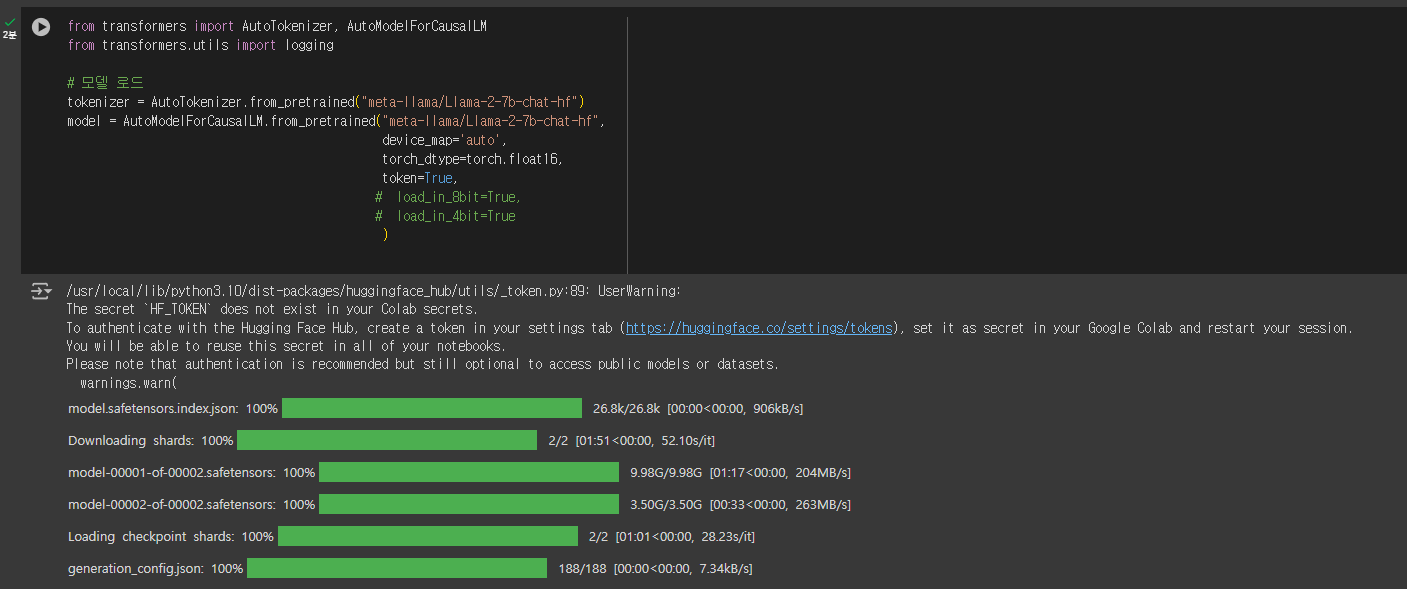
짜잔! 수많은 삽질을 통해서 결국 성공한 모습입니다!
# Use a pipeline for later
from transformers import pipeline
pipe = pipeline("text-generation",
model=model,
tokenizer= tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto",
max_new_tokens = 512,
do_sample=True,
top_k=30,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)그 다음으로 입력해줍니다!
import json
import textwrap
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
DEFAULT_SYSTEM_PROMPT = """\
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information."""
def get_prompt(instruction, new_system_prompt=DEFAULT_SYSTEM_PROMPT ):
SYSTEM_PROMPT = B_SYS + new_system_prompt + E_SYS
prompt_template = B_INST + SYSTEM_PROMPT + instruction + E_INST
return prompt_template
def cut_off_text(text, prompt):
cutoff_phrase = prompt
index = text.find(cutoff_phrase)
if index != -1:
return text[:index]
else:
return text
def remove_substring(string, substring):
return string.replace(substring, "")
def generate(text):
prompt = get_prompt(text)
with torch.autocast('cuda', dtype=torch.bfloat16):
inputs = tokenizer(prompt, return_tensors="pt").to('cuda')
outputs = model.generate(**inputs,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.eos_token_id,
)
final_outputs = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
final_outputs = cut_off_text(final_outputs, '</s>')
final_outputs = remove_substring(final_outputs, prompt)
return final_outputs#, outputs
def parse_text(text):
wrapped_text = textwrap.fill(text, width=100)
print(wrapped_text +'\n\n')
# return assistant_text그 다음으로 함수들을 입력해줍니다.
이제 사용할 준비를 마쳤습니다!

사진과 같이 제대로 동작하는 모습을 볼 수 있습니다!
