부트캠프 이머시브 5일차 TIL입니다.
오늘은 Linked List와 Hash Table에 대한 개념을 공부하고 직접 구현을 해보면서 배운 내용들을 정리 해보았습니다.
1. Linked List에 대한 정리
1) Linked List의 기본 개념 정리
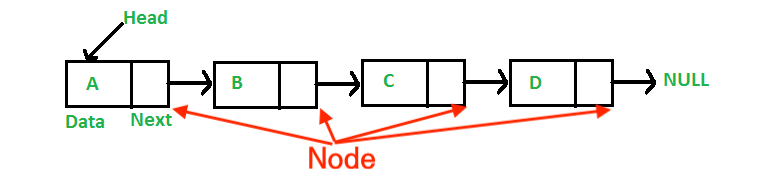
- Linked List란 그 크기가 동적인 자료구조로서 자료구조를 구성하는 각 요소를 Node라고 함
- Linked List란 Node의 연결로 이루어진 Data Structure임
- 각 Node는 그 다음에 위치한 Node의 데이터를 가지고 있음(Singly Linked List 기준)
- 시간 복잡도
- 가져올 때 : O(n)
- 추가할 때 : O(n)
- 삭제할 때 : O(n)
- Linked List의 각 노드에 대한 Index값이 없기 때문에 Iteration을 통하여 찾고자 하는 Node를 한 개 씩 확인해야 하기 때문에 가져오는 시간 복잡도는 O(n)임.
- 그 외 Linked List의 특정 노드에 다른 노드를 추가하거나 삭제할 경우, Current Node의 Next Node를 바꾸는 것은 O(1)이지만, 그 전에 해당 값을 조회해야 하므로 O(n)임.
- Linked List 관련 GeeksforGeeks 링크
** JS로는 Class로 구현 가능(JS만 공부했다면 처음에는 새로운 세계관을 경험했다는 인상을 얻을 수 있음)
2)Doubly Linked List의 개념 정리
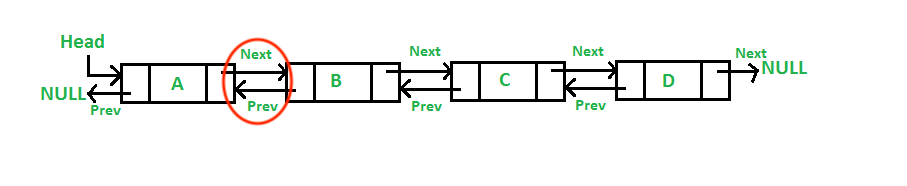
- Doubly Linked List(DLL)의 경우 그 이전 Node와, 다음 Node의 위치 값을 알고 있음
- DLL의 Head Node의 이전 값은 Null, Tail의 Next 값 또한 Null임.
Singly Linked List보다 좋은 점
- DLL은 노드의 양 방향으로 순회(trasverse)할 수 있음
- 삭제할 Node의 Pointer만 주어진다면, 좀 더 효율적으로 특정 노드를 삭제할 수 있음
- 이전 노드에 대한 접근이 가능하기 때문에 특정 노드와 이전 노드의 사이에 새로운 노드를 쉽게 추가할 수 있음
Singly Linked List보다 안 좋은 점
- DLL의 모든 Node는 Previous Pointer에 대한 정보도 담아야 하기 때문에 'Extra Space'가 필요함
- 수정 작업을 할 때마다 다른 Node에도 추가적인 작업이 필요(Insertion을 할 때 Previous Pointer와 Next Pointer 둘 다 수정이 필요함)
- Doubly Linked List에 대한 GeeksforGeeks 설명
2. Hash Table에 대한 정리
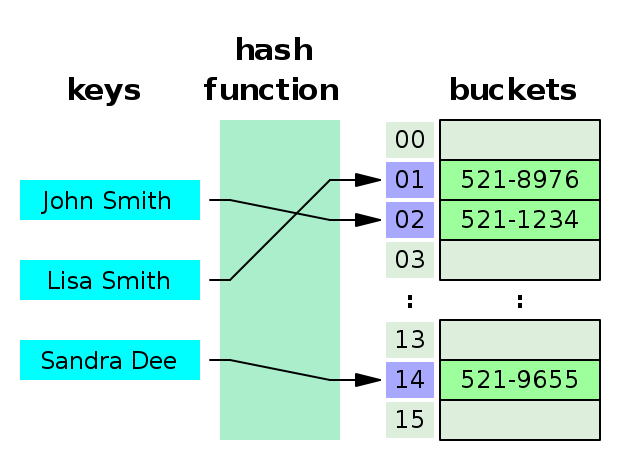
1) Hash Table의 기본 개념 정리
- Hash Table(Hash Map)은 Key와 Value를 한 쌍으로 저장하는 Data Structure임
- JS에서는 object(객체) 개념이라고 할 수 있으나, 실제로는 js Object Implementation을 위해 "Under the hood"에서는 여러 Operation이 실행된다고 함
- HashTable의 경우 Key(String)인 "John Smith"를 입력받으면 해당 Key 값을 일정한 숫자로 변환하는 Hash Function이 존재하며, Hash Function이 특정 Index(02)를 반환하면, 해당 Key 값의 Value(521-1234)는 Storage의 특정 Index의 Bucket에 저장 됨
2) Hash Table의 시간 복잡도
- 각 Operation별 시간복잡도
- 값을 가져올 때 : O(1)
- 값을 추가할 때 : O(1)
- 값을 삭제할 때 : O(1)
- 설명(aka. 제가 이해한 내용)
- Hash Table을 직접 구현해보면, hash function이 문자열인 Key를 특정 숫자로 반환하고(Index), 그 숫자는 바로 Array에 있는 Index를 바로 조회할 수 있기 때문에 값을 가져올 때는 시간 복잡도가 O(1)임.
- 또한 값을 추가하거나 삭제할 때도, Bucket 내부에 있는 값들만 조회에서 수정하면 되는 것이기 때문에 O(1)이라 할 수 있음
- Bucket에 Tuple이 쌓여 있을 경우, 1번에 조회/수정이 안 될 수 있지만, 그렇다고 하더라도 HashTable의 모든 값들을 조회하는 게 아니기 때문에 이 경우는 O(1)에 Constant가 곱해지는 것이라고 보면 됨
3) Hash Collision이 발생하면?
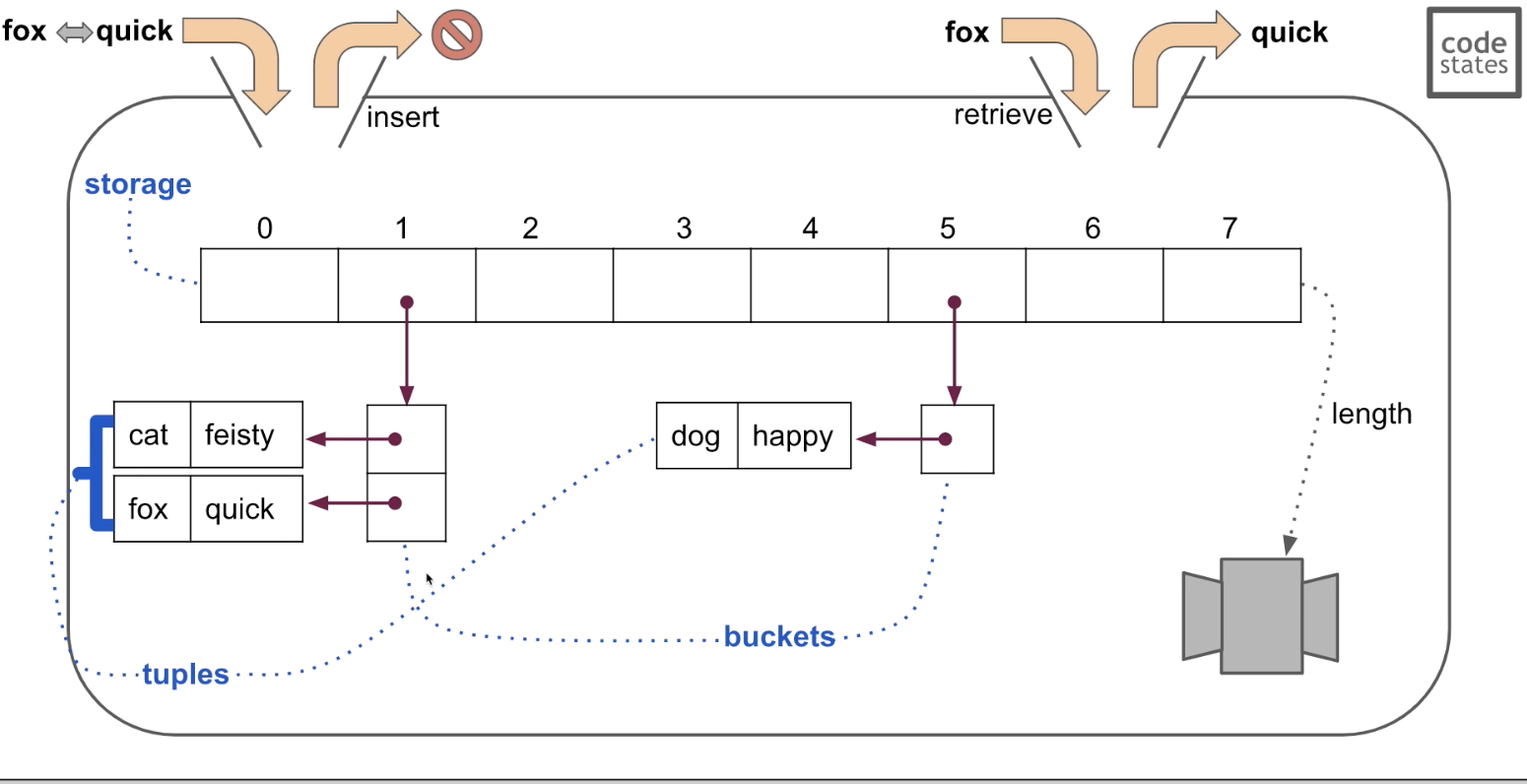
//위 그림을 배열로 구현
Storage[
empty,
Bucket[tuple1["cat", "feisty"],tuple2["fox", "quick"]],
empty...etc,
Bucket[tuple1["dog", "happy"]]
]-
위 그림에서 설명한 예시를 배열로 구현하면서 각각에 해당하는 배열 옆에 Storage, Bucket, Tuple을 기재
-
만약에 "Fox"라는 key와 "Cat"이라는 key에 대하여 Hash Function이 같은 숫자를 반환할 경우, 이 경우를 보고 Collision이 발생했다고 함
-
Hash Collision이 발생하면 Storage의 특정 Index에 있는 Bucket에 새로운 Tuple을 추가
4) HashTable Resize에 대하여
- HashTable의 각 Index가 쌓여갈 수록, Bucket의 사이즈는 무한정으로 늘어날 수 있는데, 이 경우 Hash Collision이 너무 많이 발생하고, Bucket의 사이즈가 늘어나면 HashTable 내부에서의 Operation 효율성 또한 감소할 수 있기 때문에, 어느 정도 Tuple이 쌓이면 HashTable을 Resize 해줘야 함
- Tuple의 갯수가 Storage Array Length의 75%보다 더 크다면, Storage Array의 사이즈를 Double할 것
- Tuple의 갯수가 Storage Array Length의 25%보다 낮다면, Storage Array의 사이즈를 Half할 것
부트캠프 동기 중에 제가 존경하는 분이 자주 쓰는 표현을 빌리자면, JS 초보자가 Linked List와 Hash Table을 구현하고자 할 때 느끼는 감정은 "아아아ㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏ"(패닉 상태)일 수 있습니다.
개인적으로는 끝까지 직접 구현을 해본 후 아래의 링크들을 클릭하는 것을 추천하지만, Linked List와 HashTable을 JS로 구현하는데, 전혀 감이 안 잡히신 분들은 다음 링크들을 추천합니다..

함께 성장하는 개발자가 되겠습니다!
아ㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏ 패닉상태입니다