
데이터가 많을 경우, order by와 인덱스 중 어떤 방식을 채택해야 할까?
우선 bno가 pk로 설정된 tbl_board라는 테이블을 만든 후, 재귀 복사를 통해서 데이터 개수를 늘리자(반복해서 여러 번 실행)
insert into tbl_board (bno, title, content, writer)
(select seq_board.nextval, title, content, writer from tbl_board);반복해서 약 300만건 정도의 데이터를 삽입했다.
-order by를 이용해 SQL을 실행 했을 경우
select * from tbl_board order by bno desc;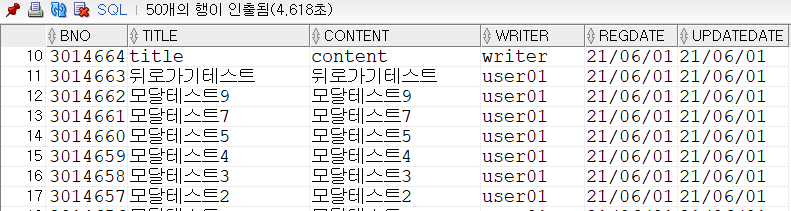
반복된 select문 실행으로 인하여 시간이 줄었지만 그래도 4초대가 나온다.(첫 실행시 8초정도 걸렸음)

실행 계획을 살펴보면 TBL_BOARD를 'FULL'로 스캔했고, 'SORT'가 일어난 것을 볼 수 있다. 이때 가장 많은 시간을 소모하는 작업은 정렬하는 작업이다.
-인덱스를 이용하여 SQL을 실행 했을 경우
select /*+ INDEX_DESC(tbl_board pk_board) */
* from tbl_board where bno > 0;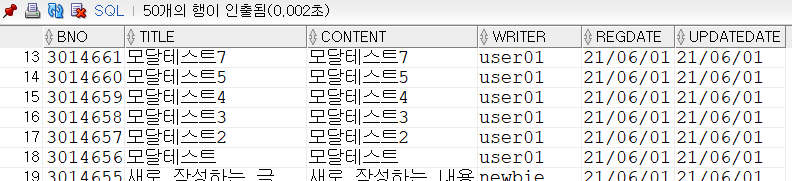
실행 시간이 엄청나게 차이가 나는걸 볼 수 있다.
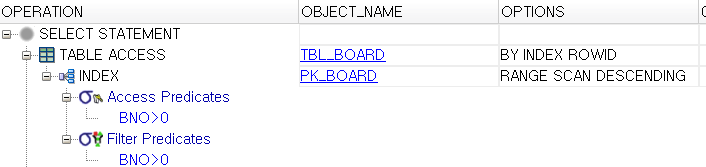
실행 계획에서 알수 있는건 1) SORT작업을 하지 않았다는 점, 2) TBL_BOARD를 바로 접근하는 것이 아니라 PK_BOARD를 이용해서 접근한 점, 3) RANGE SCAN DESCENDING, BY INDEX ROWID로 접근했다는 점이다.
데이터가 많을 경우, 이렇게 가장 일반적인 해결책인 인덱스를 이용하여 정렬을 생략하는 방법이 좋다
인덱스라는 존재가 이미 정렬된 구조이므로 이를 이용해서 별도의 정렬을 하지 않아도 되는 것이다.

https://pyeongdevlog.vercel.app