문제 상황
이번 글에서는 이기적이라는 키워드로 OpenSearch 책 인덱스에 검색했을 때 다음과 같은 제목을 가진 문서들을 확인할 수 있었다.
나미야 잡화점의 기적이기는 습관너는 기적이야이기적 유전자이기적인 유전자
앞에 3개의 문서는 이기적이라는 키워드와 아무 상관없는 단어들이다.
앞선 글에서 단순하게 edge_ngram을 써서 이기적이라는 단어가 검색 결과에 포함되게 만들었다. 여전히 기적과 관련된 문서들이 검색되고 이젠 이기라는 단어가 앞에 있는 문서들도 검색된다.
교보문고는 어떨까?
"이기적"으로 검색했을 때 95페이지까지 검색결과가 나왔고, 기적과 같은 단어가 포함된 결과도 나왔다.
내 검색 결과와 다른 점은 "기적"이라는 키워드가 있는 거의 첫 페이지가 아닌, 마지막 페이지에 존재했다는 것이다.

알라딘은 어떨까?
알라딘도 "이 기적", "기적"이 포함된 문장들이 검색된 것을 확인했다.
알라딘도 역시 사용자 의도와 거리가 먼 검색결과는 마지막 페이지에 존재했다.

목표
정말 엄격하게 이런 검색결과를 필터링할 순 없는 것 같다.
최대한 뒤로 미루고 최대한 덜 검색되게 만드는 것이다.
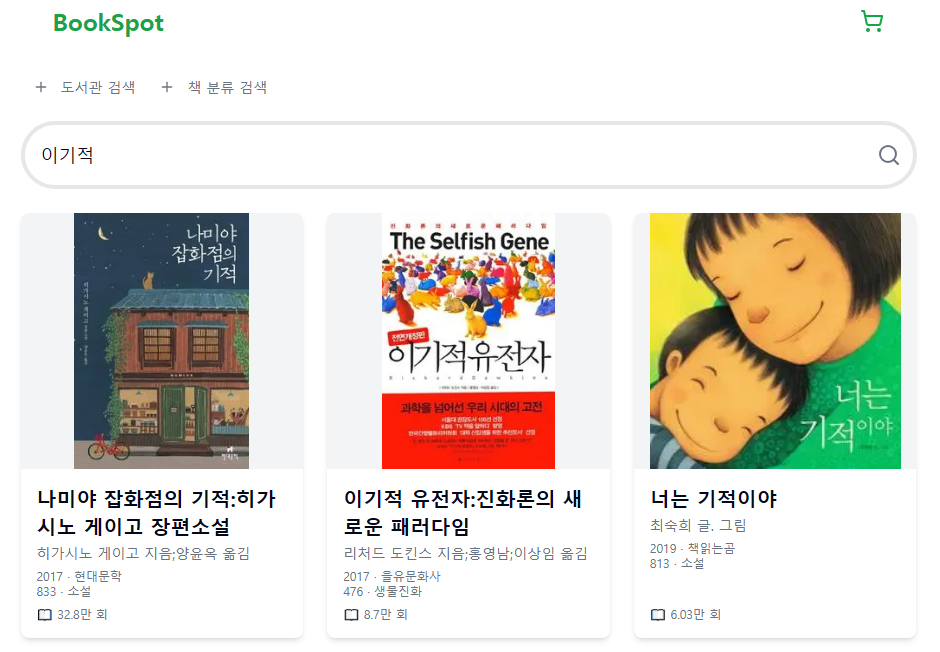
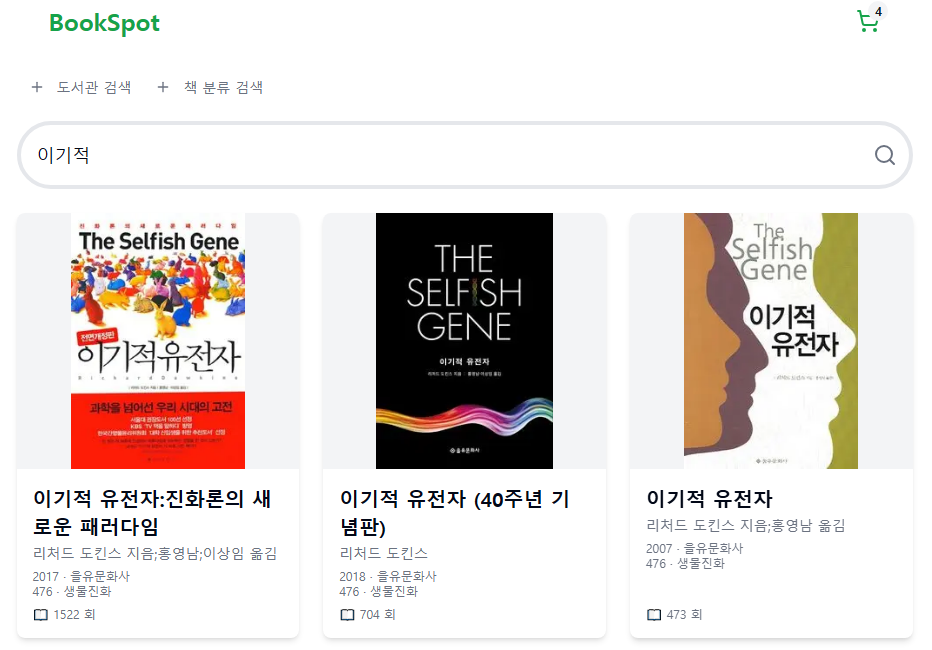
지금은 대출 수로 정렬을 했기 때문에 사진과 같이 기적과 같은 데이터가 먼저 나온다.
이번 글에서는 이런 이기 또는 기적과 같은 데이터를 뒤로 미루고 가능하다면 결과에 포함시키지 않는 것이 목표다.
검색 개선하기
nori 토크나이저가 분석을 하는 것보다, 검색하고자 하는 문자열이 포함돼 있는게 더 중요하지 않을까?
개선은 이 아이디어에서 출발한다.
인덱스 구조
title을 띄워쓰기로 나누고 최대 2글자 이상의 토큰으로 두고 검색하려 했다.
ws_min2_analyer 분석기랑 title.ws 필드가 추가됐다.
(글의 내용과 상관없는 필드는 생략)
검색을 개선하기 위해 서비스 환경과 다른 일부 데이터를 올린 books-query-1 인덱스를 다음과 같이 생성했다.
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0,
"analysis": {
"tokenizer": {
"my_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
},
"edge_ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 5
},
"ws_tokenizer": {
"type": "whitespace"
}
},
"filter": {
"min_length_2": {
"type": "length",
"min": 2
}
},
"analyzer": {
"my_nori_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer",
"filter": ["nori_readingform", "nori_part_of_speech", "lowercase"]
},
"my_ngram_analyzer": {
"type": "custom",
"tokenizer": "edge_ngram_tokenizer",
"filter": ["lowercase"]
},
"ws_min2_analyzer": {
"type": "custom",
"tokenizer": "ws_tokenizer",
"filter": [
"lowercase",
"min_length_2"
]
}
}
}
},
"mappings": {
"dynamic": false,
"properties": {
"book_id": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "my_nori_analyzer",
"fields": {
"keyword": {
"type": "keyword"
},
"ngram": {
"type": "text",
"analyzer": "my_ngram_analyzer"
},
"ws": {
"type": "text",
"analyzer": "ws_min2_analyzer"
}
}
},
"loan_count": {
"type": "integer"
}
}
}
}이제 "이기적 유전자"라는 제목은 title.ws에 이기적, 유전자 토큰으로 저장될 것이다.
검색하기
이전 검색 방식에서는 2591개의 문서가 검색됐다.
단순 검색
이 검색에서는 114개의 문서가 검색됐다.
물론 모든 문서에는 "이기적"이라는 단어가 포함돼 있다.
{
"_source": ["title", "publisher", "author", "loan_count"],
"query" : {
"bool": {
"should": [
{"match_phrase": {"title.ws": "이기적"}}
]
}
},
"sort" : [{"loan_count": "DESC"}]
}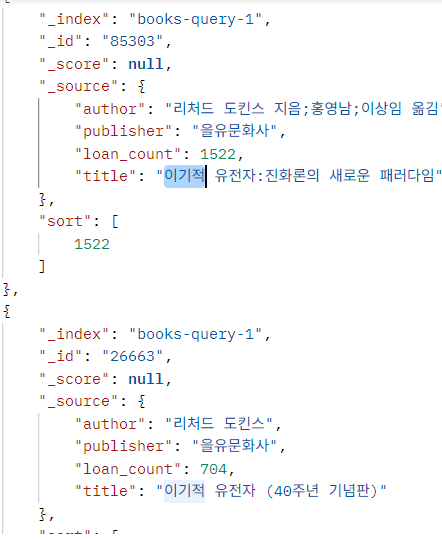
문제는 이기적인 유전자 마저 검색이 되지 않는다는 것이다.
score 검색
"이기적인 유전자"도 검색 결과에 포함시키려면 title.ngram도 검색 결과에 포함시켜야 한다.
이전 방식에서는 단순하게 loan_count로 정렬했지만 이젠 match를 사용해서 스코어를 계산해서 정렬한 후에 loan_count로 정렬한다.
{
"_source": ["title", "publisher", "author", "loan_count"],
"query" : {
"bool": {
"should": [
{
"multi_match": {
"query": "이기적",
"fields": [
"title.ngram^6",
"title.ws^8"
]
}
}
]
}
},
"sort" : [
{"_score":"DESC"},
{"loan_count":"DESC"}
]
}title.ngram은 6의 부스트를 title.ws는 8의 부스트를 뒀다.
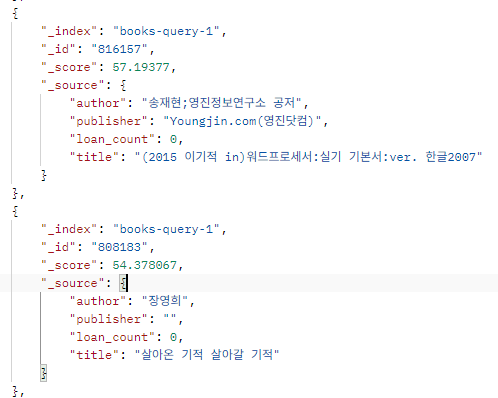
114개에서 300개의 검색 결과로 늘어났지만, 다음과 같이 이기적인이 검색결과에 포함된다.

한글 형태소 분석 포함하기 - min_score
지금까지는 이기적이라는 단순한 단어를 검색하는 경우 처리를 했다.
하지만 실제 사용자들은 단어의 조합으로 검색하는 경우도 많을 것이다.
ex) 이기적 유전자 => 이기 + 유전자 토큰 검색
그래서 노리 토크나이저를 사용하는 title 필드를 넣어야 한다.
{
"_source": ["title", "publisher", "author", "loan_count"],
"min_score": 50,
"query" : {
"bool": {
"should": [
{
"multi_match": {
"query": "이기적",
"fields": [
"title^5",
"title.ngram^6",
"title.ws^8",
"title.keyword^10"
]
}
}
]
}
},
"sort" : [
{"_score":"DESC"},
{"loan_count":"DESC"},
{"book_id": "DESC"}
]
}min_score를 걸지않으면 2886개의 검색 결과가 나온다.
score가 50일 때부터 이기는, 기적 등이 포함된 검색 결과들이 나오는것을 확인했고, min_score를 추가해서 검색 결과를 205개로 줄였다.
결과적으로 노리 토크나이저로 분석돼서 매칭이 되는 단어가 있어도 제목 자체가 길고 구체적이면 검색 결과로 나오지 않게 만들어졌다.
띄워쓰기 키워드인 title.ws가 일치하면 모를까,
노리 토크나이저의 결과로 나온 토큰 + 제목이 길고 구체적인 상황이라면 구체적인 검색어를 입력하는게 맞지 않을까라는 생각이다.
sort 순서 바꾸기
min_score를 통해 기적, 이기는 등의 문서들을 전체 결과에서 최대한 많이 제외했다.
그래도 여전히 약간 만족스럽지 못한 부분이 있다.
한강을 검색했다고 해보자.
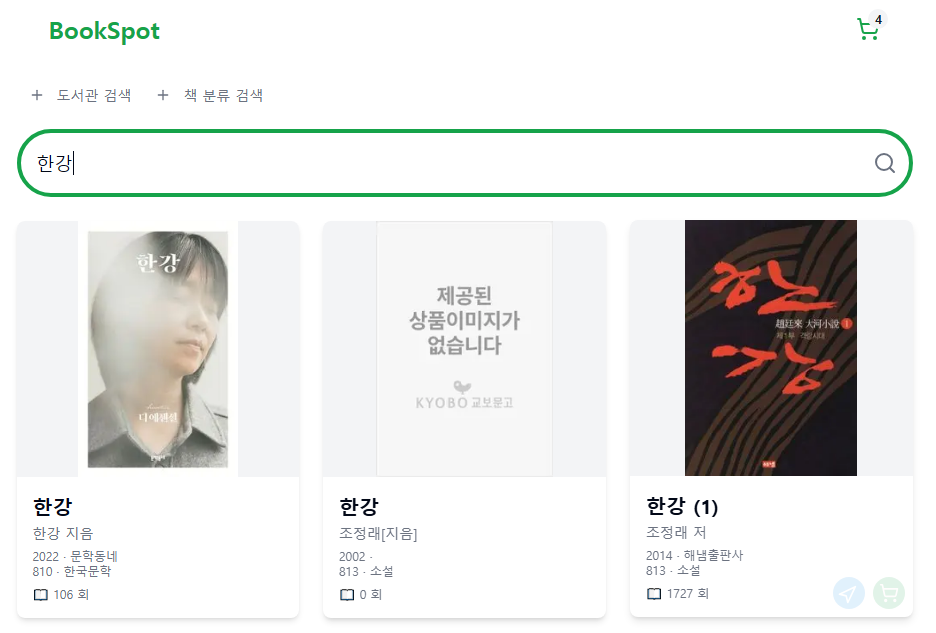
내가 만약 사용자라면 인기가 많은 채식주의자나 소년이 온다 등의 책을 원할 것이다.
도서관에서 인기의 기준은 대출 수이다.
{
...
"sort" : [
{"loan_count":"DESC"},
{"_score":"DESC"},
{"book_id": "DESC"}
]
}sort 순서만 바꿔줬다.
관련 없는 문서는 min_score로 제외를 했으니 이제 관련있는 문서들을 대출 수 순으로 보여줄 것이다.
이제 좀 만족스럽다.
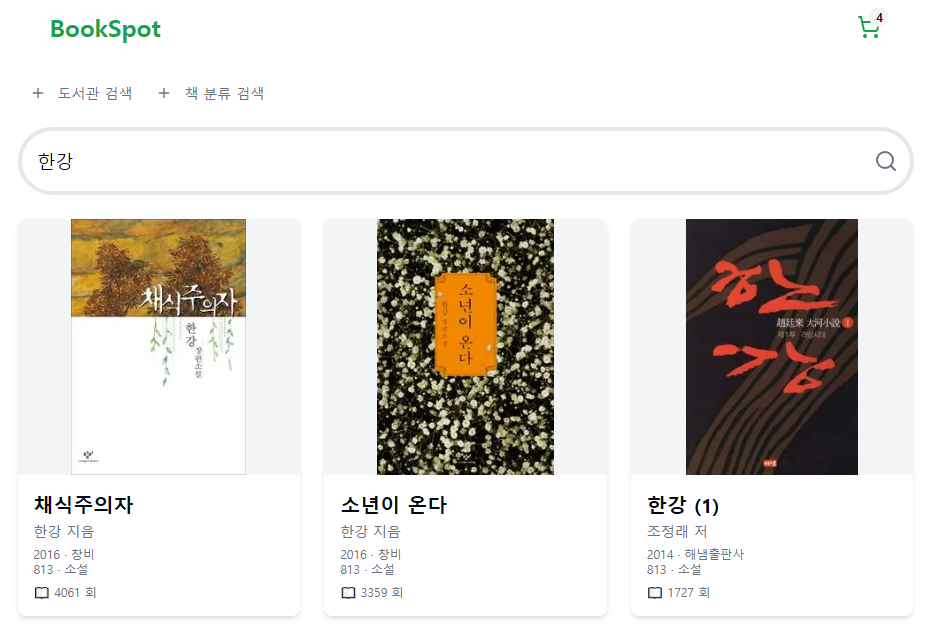
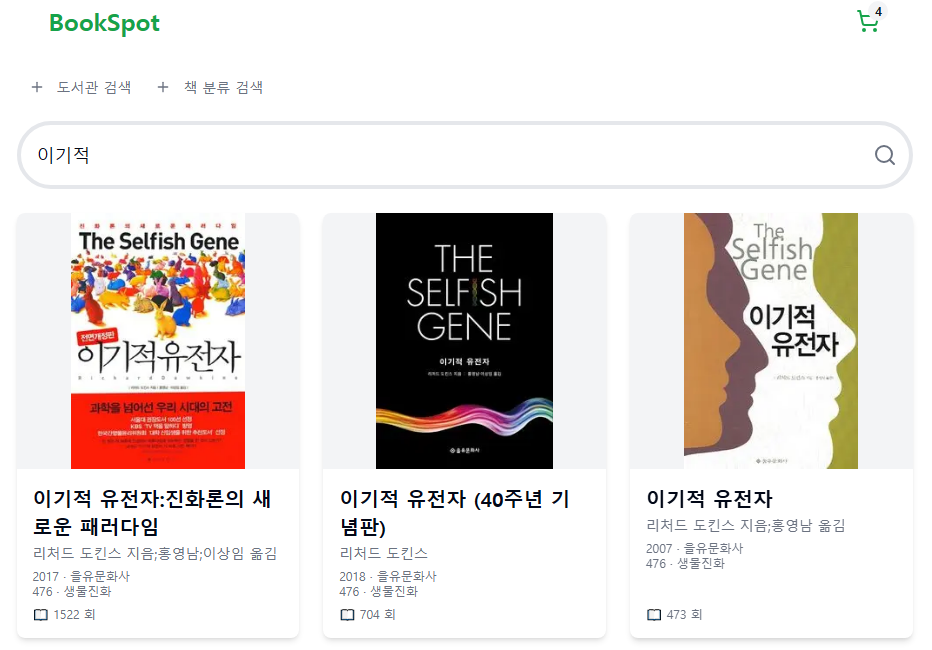
이기적을 검색했을 때도 다음과 같이 나오는 것을 확인할 수 있다.
이전 글과 달라진 점은 대출 수가 많던 나미야 잡화점의 기적, 너는 기적이야가 검색 결과에서 제외됐다는 것이다.
추가) 검색 키워드가 길어진다면?
지금까지의 쿼리는 키워드가 길어지면 문제가 된다.
객체지향의 사실과 오해라는 책을 검색해보면 다음과 같은 결과가 나온다.
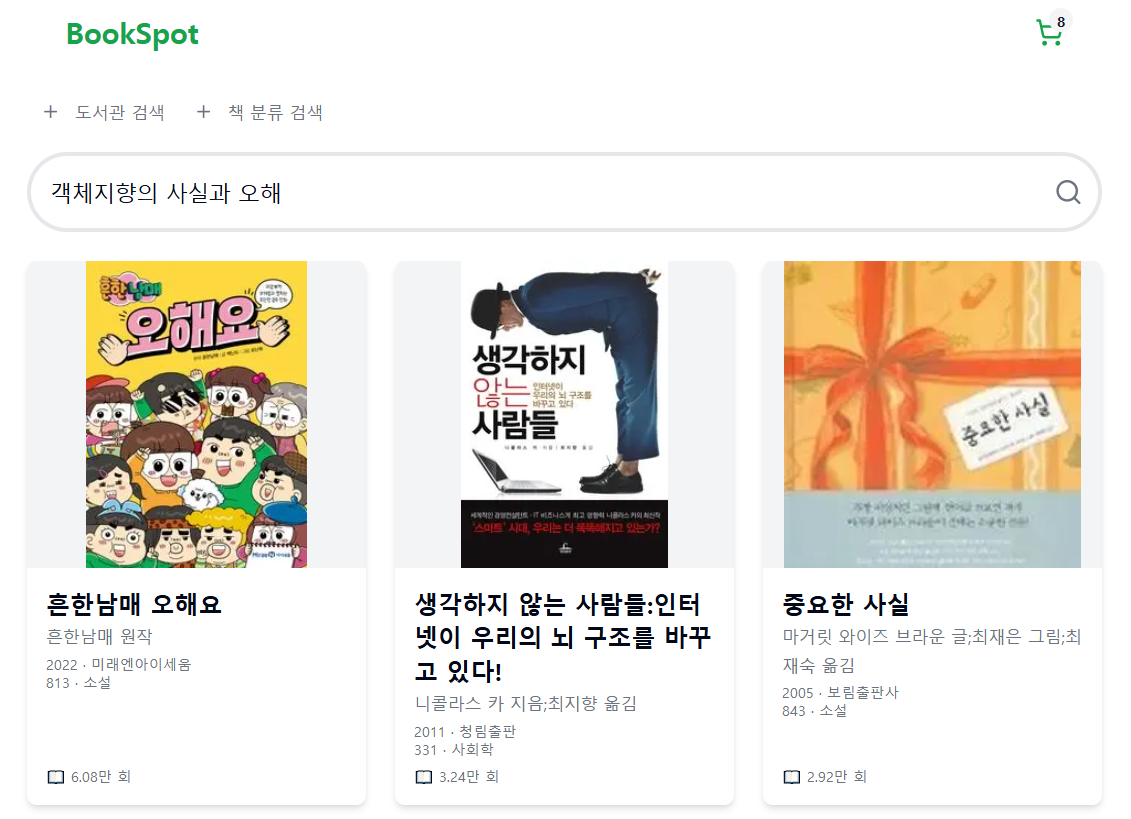
키워드에서 분석된 토큰들이 하나라도 존재하면 전체 검색 결과에 포함되기 때문이다.
분석된 토큰들을 모두 가지고 있는 문서만 전체 검색 결과에 포함되도록 바꿔야 한다.
이건 간단하다 multi_match 부분에 "operator" : "and"만 추가해주면 된다.
{
"_source": ["title", "publisher", "author", "loan_count"],
"min_score": 50,
"query" : {
"bool": {
"should": [
{
"multi_match": {
"query": "이기적",
"fields": [
"title^5",
"title.ngram^6",
"title.ws^8",
"title.keyword^10"
],
"operator": "and"
}
}
]
}
},
"sort" : [
{"_score":"DESC"},
{"loan_count":"DESC"},
{"book_id": "DESC"}
]
}이렇게 바꾸면 검색 결과는 다음과 같이 바뀐다.
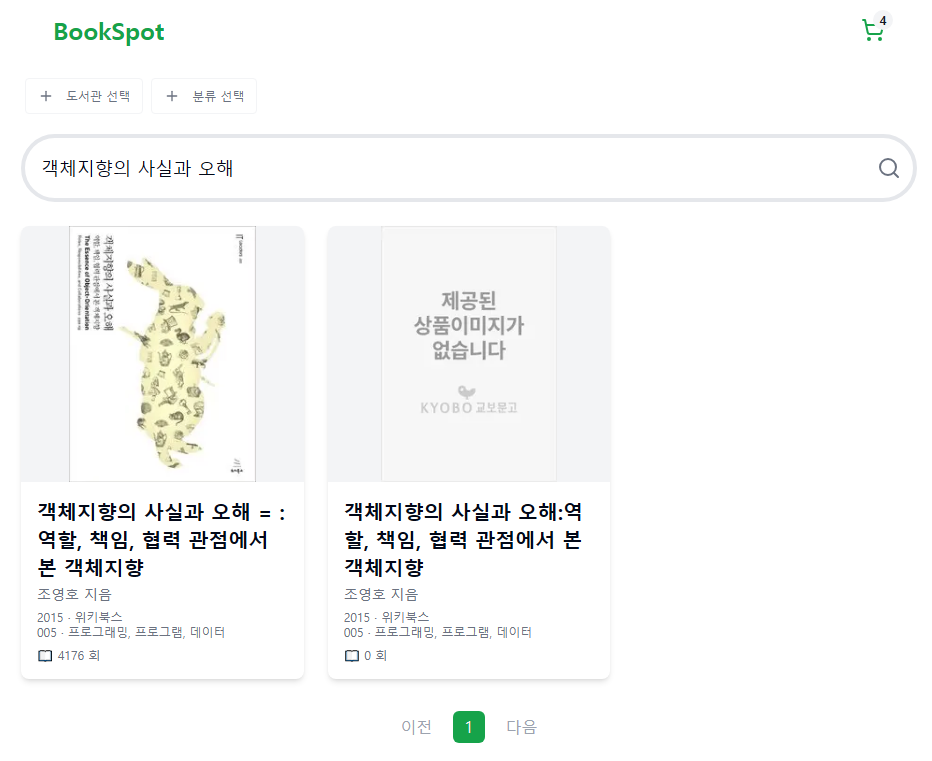
검색이 안되는 제목
1) 당신은 이기적인 게 아니라 독립적인 겁니다
당신은 이기적인 게 아니라 독립적인 겁니다라는 제목의 책이 있다.
이 책은 이기적이라는 단어로는 검색되지 않는다.
title.ws 걸리지 않고, title.ngram도 edge_ngram이기 때문에 걸리지 않는다.
title도 노리 토크나이저가 이기적을 기적이라는 토큰으로 분리하기 때문에 걸리지 않는다.
2) 블루프린트:이기적 인간은 어떻게 좋은 사회를 만드는가
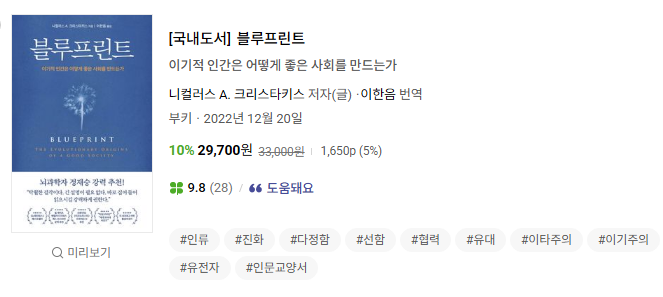
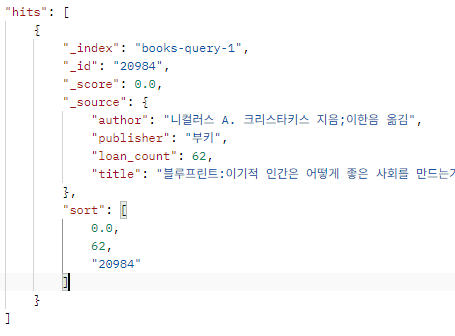
이기적으로 검색했을 때 스코어는 0.0
이기적인으로 검색했을 때 스코어는 29.6
ws_tokenizer를 다음과 같이 패턴으로 바꿔줬다.
이러면 특수문자도 분리해낸다.
"ws_tokenizer": {
"type": "whitespace"
"type": "pattern",
"pattern": "[\\p{Punct}\\s_]+"
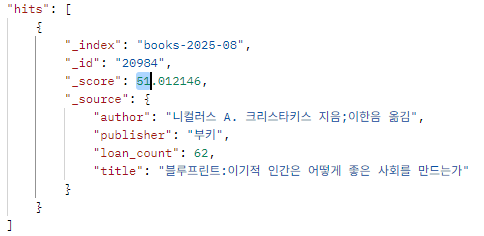
}토크나이저를 변경하고 다시 쿼리를 해봤더니, 이기적이 포함돼서 score가 50이상이 된 것을 확인할 수 있다.
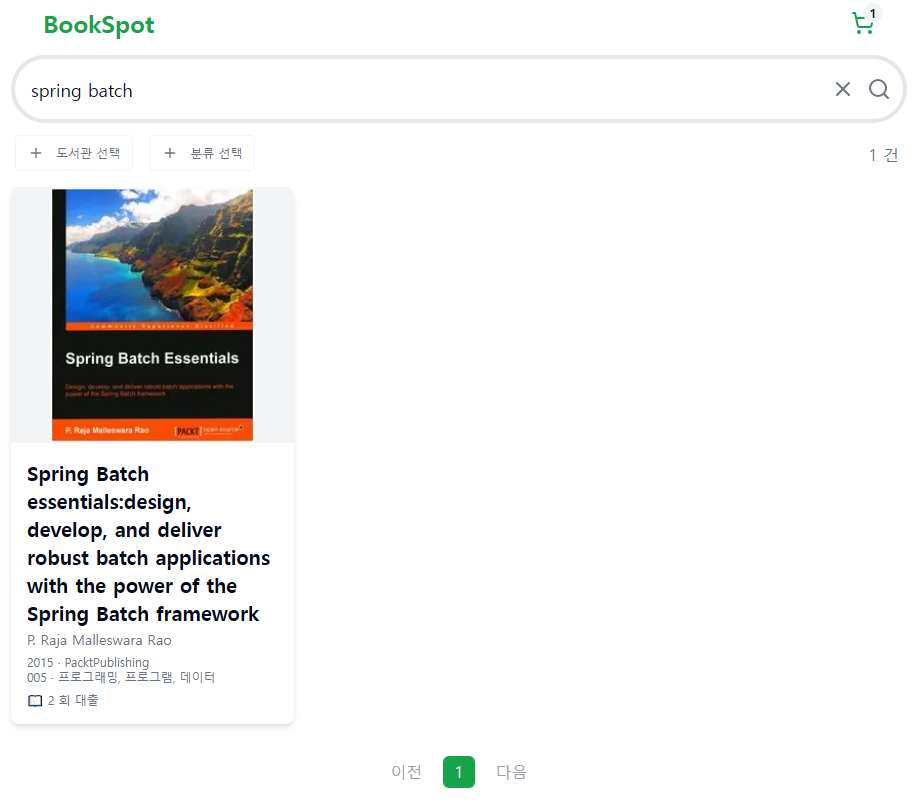
3) 'Spring Batch' 검색 시...
Spring Batch를 검색하면 Spring과 관련된 책들이 나온다.
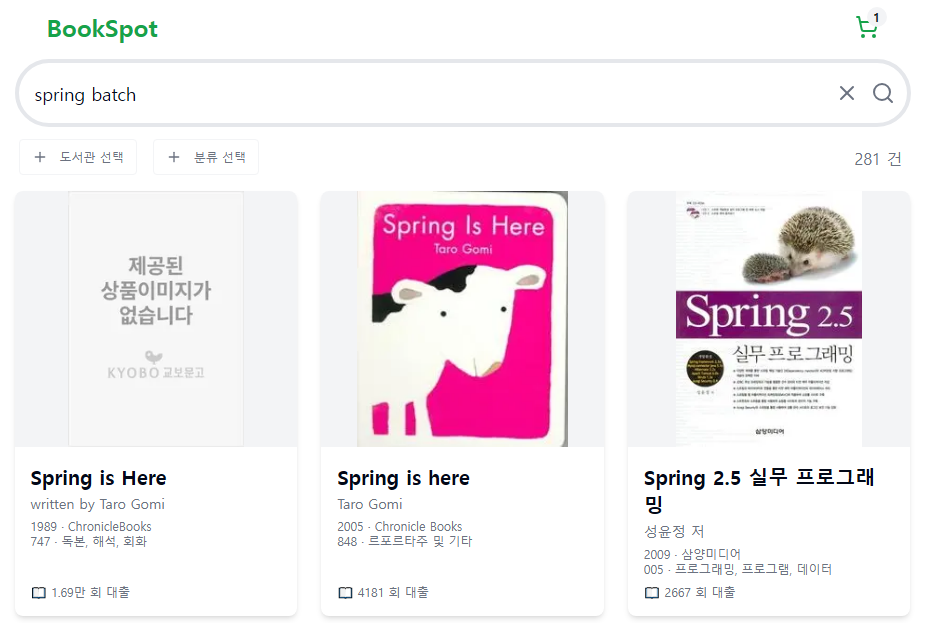
title.ngram으로 인해 앞글자가 일치하기 때문에 전체 검색결과에 Spring이 포함된 것이다.
좀 더 폭넓게 검색을 하게 만들 것인지,
정확하게 검색되게 만들 것인지 선택해야 했다.
앞서 검색 키워드가 길어졌을 때 정확한 검색을 위해 title.ngram을 제거하도록 결정했다.
이기적을 검색했을 때 이기적인이 검색되지 않는 것은 갸우뚱 하는 정도겠지만,
spring batch 상관없는 결과가 많이 검색되는 것은 심각한 불편함이라 생각했다.
(+ "operator" : "and"를 했기 때문에 이기적인으로 이기적이 검색되지 않는다.)