BookSpot
1.InnoDB 버퍼풀 사이즈 변경과 Insert 성능 개선

상황 1.3억 데이터 전체를 DB에 넣는 작업은 오래걸리는 작업이다. 그래서 전체 데이터 중 일부인 700만 개의 데이터만 넣는 식으로 성능을 비교해 본다. 테이블 구조 Book : 책 정보(Book_ID, ISBN, Title ...) Library : 도서관 정
2.책 정보 동기화 - DB에 없는 책 정보 저장하기

요구사항 및 데이터 특징 > #### 사용된 기술 Java, SpringBatch, MySQL Book 테이블 컬럼 id(PK - 자동증가 컬럼) isbn13 varchar(13) NOT NULL (유니크 제약조건) 제목 등등 컬럼 ... 요구사항 1521개의 cs
3.대출 수 동기화 - 1.3억개 책 데이터에서 대출 수 집계하기
요구사항 및 데이터 특징 >#### 사용된 기술 Java, SpringBatch, MySQL Book 테이블 id(PK - 자동증가 컬럼) isbn13 varchar(13) NOT NULL (유니크 제약조건) loan_count int NOT NULL DEFAULT
4.MySQL InnoDB 수준 Lock 종류
찾아보고, 이해가 안가는 부분은 직접 실행해보고, 내용을 제가 이해한대로 재해석했기 때문에 틀려진 부분이 있을 수 있습니다. 틀린 부분은 바로 잡아주시면 수정하겠습니다. MySQL 락 사전 지식 글을 시작하기 앞서 락의 수준과 종류를 간단하게 알면 전체 내용을 이해하
5.Insert Ignore 키 충돌과 데드락 발생

내가 하고 있던 작업은 1521개의 csv파일에 있는 도서관 소장 도서 데이터(총 1.3억건)에서 유니크한 ISBN13을 가진 책 데이터들을 Book 테이블에 저장하는 것이였다.결과적으로 유효하고 유니크한 ISBN13을 가진 책 정보는 약 280만개였다.1.3억개의 데
6.도서관 소장 도서 동기화
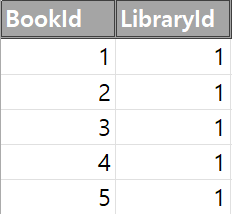
#### 요구사항 1. 1521개의 도서관 소장 도서 csv 파일에서(총 1.3억개의 데이터) `LibraryStock` 테이블에 새로운 `{Book_Id - Library_Id}` 정보를 최신화하기 2. 도서관 소장 도서 파일에 새롭게 추가된 책 정보를 Insert하
7.비정상 종료 Batch 처리 복구하기
EC2의 CPU 사용량이 100%에 도달하면서 실행중인 Job 자체가 비정상적으로 종료됐다. Job을 정상적으로 재시작하려면 약간의 수정이 필요하다. 문제가 발생한 상황 파악하기 로그를 뒤져봤을 때 파일내의 중복된 데이터를 제거하는 Step에서 발생했다. 중복된 데
8.무중단 배포하기
8080에 spring 서버를 띄워 놓은 상태에서 시작한다. Nginx 설치 ec2 IP의 80포트로 요청을 보내서 spring 서버에서 응답이 오는지 확인하고 정상적인 응답이 오면 성공 컨트롤러 작성 yml 파일 작성 8081포트와 8082 포트로 서버를
9.Batch 서버 EC2 버벅임 - 메모리 초과
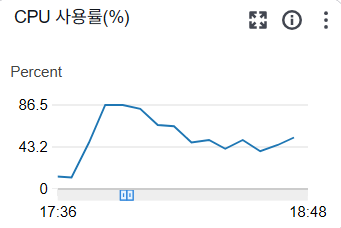
t3.micro EC2를 사용하는 Spring Batch 서버에서 Job을 돌리다가EC2가 엄청나게 느려지며 Putty 접속도 한참 걸렸다.CPU 사용량은 90% 밑으로 사용중이였는데 버벅임이 생기는 걸 보니 메모리 초과 때문인 것 같다.분명 xmx, xms 설정으로
10.OpenSearch Batch 인덱싱 속도 급감 원인 파악
SpringBatch 서버에서 OpenSearch로 Bulk Insert 요청을 보내는 과정에서 처리 속도가 갑자기 느려졌다. 그래서 작업을 재시작도 해보기도 하고, 인덱스를 지우고 다시 시작해도 정상적인 속도로 Bulk Insert 작업이 진행되다가 1~2시간정도
11.Batch 처리 시 JPA repository.findAll(pageable) 사용으로 RDS I/O 크레딧 고갈 문제 해결
문제 Limit와 Offset을 쓰는 페이징 쿼리는 앞에서 부터 읽기 때문에 IO가 굉장히 많다. 다음 로그는 bookRepository.findAll(pageable)의 쿼리문이다. limit와 offset을 쓰고, 마지막에 count 쿼리까지 나간다. 이 쿼리
12.문서와 정확히 일치하는 한글 문자열 검색 실패 문제 해결(match_phrase)
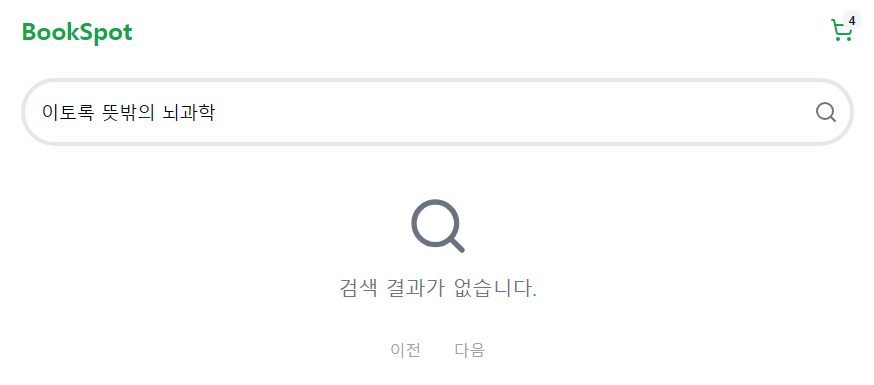
이 글에서 사용하는 인덱스의 analyzer는 다음과 같다.이토록 뜻밖의 뇌과학 이라는 단어을 검색할 때 결과가 존재하지 않는다.하지만 뇌과학을 키워드로 검색했을 때 여러 검색 결과 중 하나로 확인할 수 있다.완전히 동일한 제목을 키워드로 검색하는데 왜 검색이 되지 않
13."이기적"으로 검색해도 "이기적 유전자"가 검색되지 않는 문제 해결 (edge_ngram)
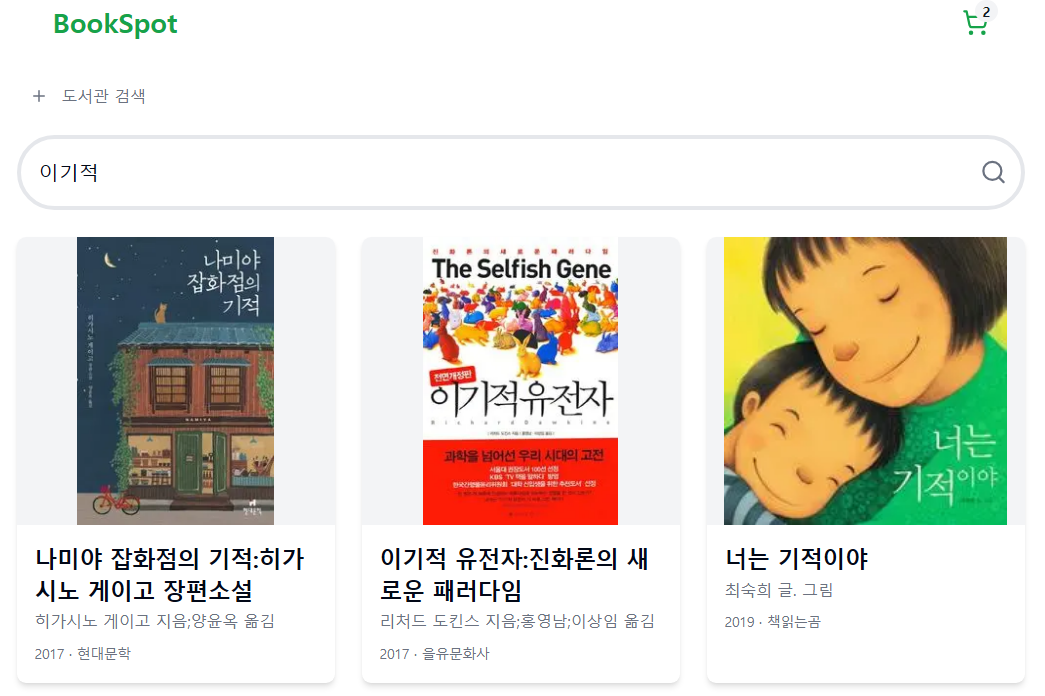
문제 상황 분명 이기적이라는 키워드와 관련된 책을 보고 싶었지만 기적과 관련된 책이 검색됐다. 그리고 이기적 유전자라는 책은 확인할 수 없었다. 분석 색인에 사용된 애널라이저로 이기적을 분석해보자. 이기적을 이 + 기적으로 보고 이는 필터링한 것 같다. 그렇다면
14."이기적" 키워드 검색 결과에서 "기적"과 관련된 내용 뒤로 미루기 (_score)
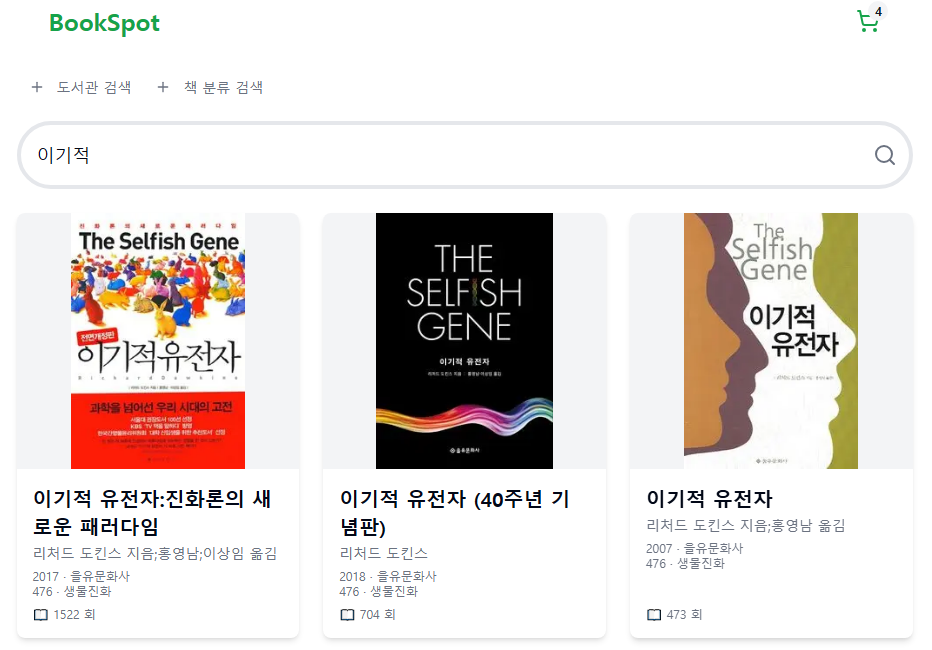
문제 상황 이번 글에서는 이기적이라는 키워드로 OpenSearch 책 인덱스에 검색했을 때 다음과 같은 제목을 가진 문서들을 확인할 수 있었다. 나미야 잡화점의 기적 이기는 습관 너는 기적이야 이기적 유전자 이기적인 유전자 앞에 3개의 문서는 이기적이라는 키워드와
15.vercel 리전 변경하기 - 페이지 로딩 문제
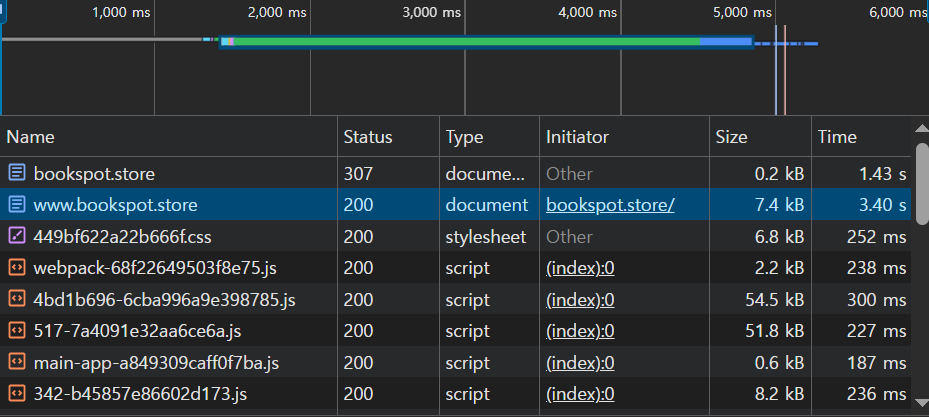
처음 페이지를 불러오는데만 5초 이상 걸렸다. 백엔드 속도 문제인가? 로그를 확인해보니 조회 시간이 1초를 넘어가지도 않았다. 프론트에 문제가 있는 부분이 있나? vercel에 요청 로그를 확인해보니 위치가 워싱턴으로 나왔다. 리전 이동하기 Settings
16.배포 자동화 프로세스 kill이 안되는 문제 해결
stop.sh가 동작되지 않는다.스크립트로 kill -15를 실행했지만 프로세스가 종료되지 않았다.다른 프로젝트에 사용했던 스크립트를 그대로 쓴 것인데 이 SpringBoot 서버를 배포할 때 이상하게 종료가 되지 않았다.이전 프로젝트와 달라진 부분이 OpenSearc