문제 발생

이런 악의적인 요청이 반복적으로 오면서 CPU 사용량이 올라가면서 EC2 서버가 멈췄다.
우리는 CPU 사용량이 올라가는 것을 알지 못했고, EC2 서버가 멈추고도 바로 파악하지 못했다.
사용자로부터 서버가 안된다는 말을 듣고 나서야 해당 문제를 파악할 수 있었다.
CPU 사용률이 평균적으로 2~40% 사이를 유지하다가 급격하게 100%까지 올라갔고,
사진과 같은 오류 로그를 확인할 수 있었기 때문에 원인은 알 수 없는 봇들이 요청을 보내는 것이라고 판단했다.
최소한 이렇게 서버가 내려갔을 때 빠르게 상태를 파악하고 서버를 복구를 하기위해서 그라파나의 모니터링 정보를 활용해서 알림 기능을 구성하려 한다.
일단 여기서는 도커를 사용해서 로컬에서 알림을 테스트해본다.
세부사항
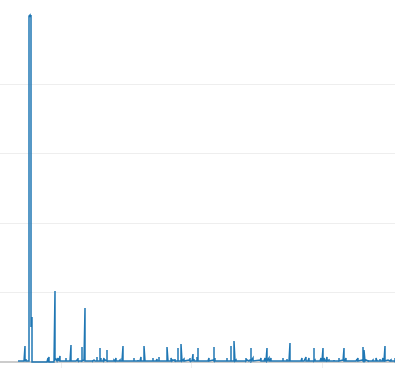
처음 확 튀어나간 부분이 CPU 사용률이 100%가 되면서 서버가 중단됐을 때이다.
기본적으로 우리 서비스의 사용자가 그렇게 많지 않기 때문에 40% 이상을 넘어가지 않는다.
널널하게 CPU 사용률이 60%가 넘어가면 디스코드로 알림을 보내도록 만들어보겠다.
디스코드 알림 기능
Contact Point 생성
우리 프로젝트는 디스코드로 진행되고 있으니, 디스코드를 통해 알림을 하도록 만들어보겠다.
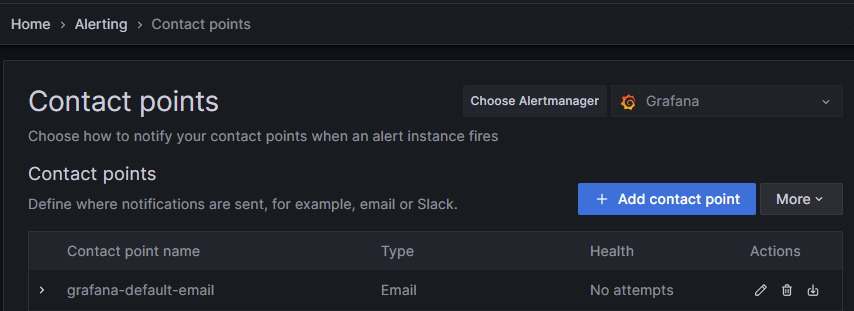
Home > Altering > Contact points에서 Add contact point로 이동하자.
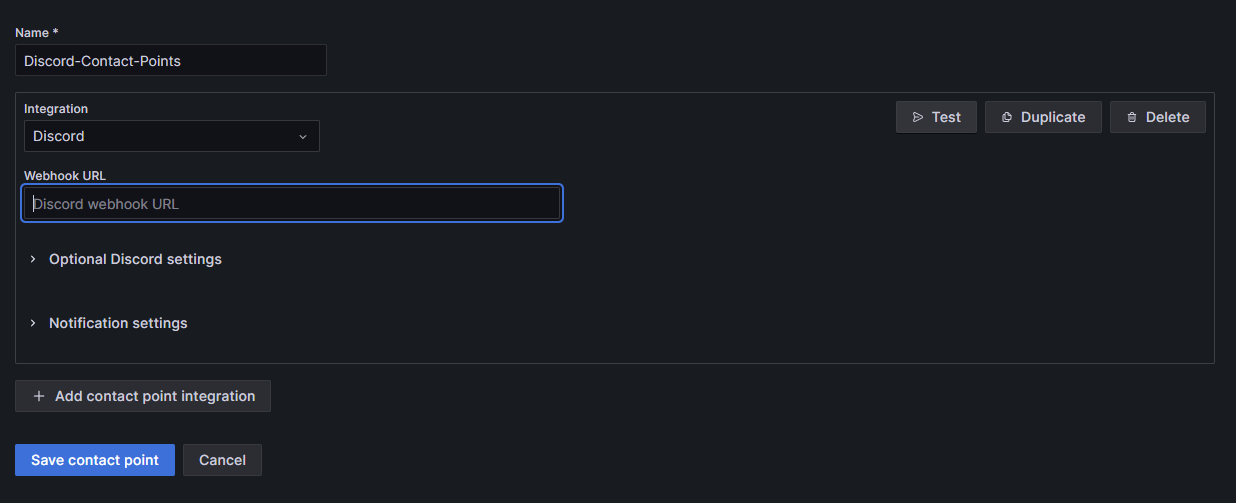
Discord로 설정하고, 디스코드에서 웹훅을 생성해서 넣어주자.
웹훅을 생성하는 법을 모르면 다음 글을 확인하자 - 젠킨스 배포 결과를 디스코드로 출력하기 - 디스코드 설정
이제 테스트 버튼을 누르면 다음과 같은 템플릿을 디스코드에서 확인할 수 있다.
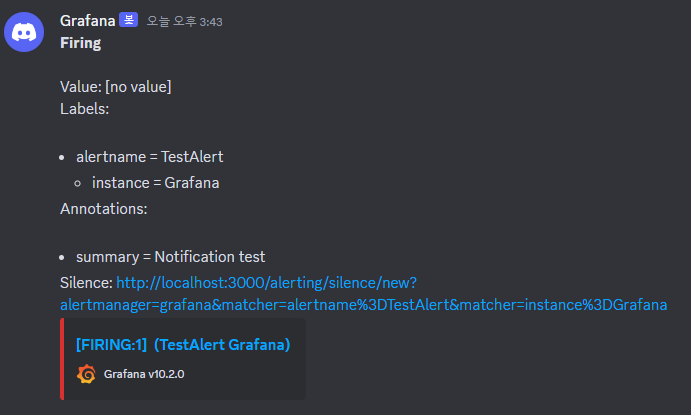
CPU 사용률 Rule 생성
Rule을 생성하기 위해서는 4가지가 필요하다.
Contact Point, 알림 설정, Folder, Group
Contact Point는 앞서 설정했기 때문에 연결만해주면 된다.
알림 설정
CPU 사용률이 20%가 넘어가면 알림이 발생하도록 설정했다.
(로컬에서 알림을 설정했기 때문에 빠르게 알림을 확인하고 싶었다.)
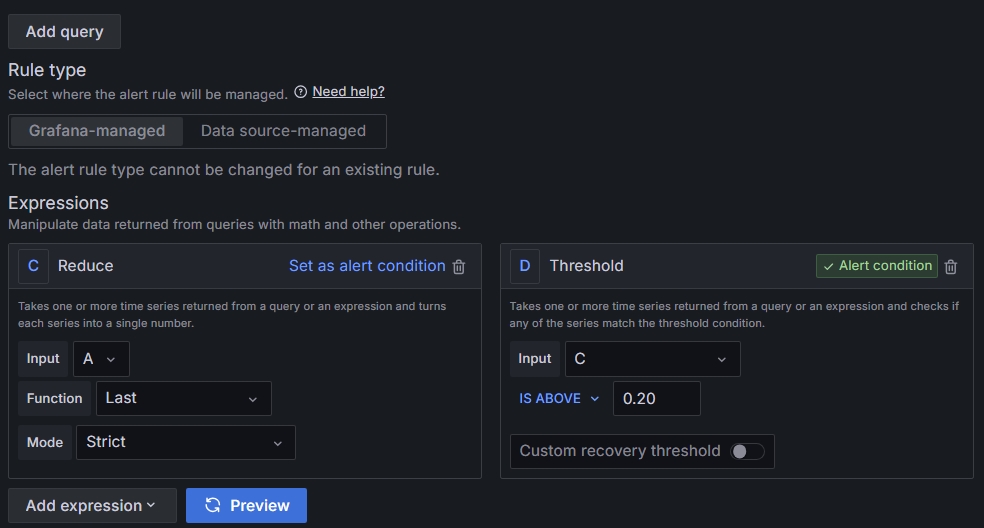
Threshold에 IS ABOVE 0.20이 핵심이다.
주기 설정
Evalutaion interval 시간마다 체크하고 Pending period 시간이 지난 뒤 여전히 조건이 위반되면 알림이 발행된다.
그리고 다시 정상화됐을 때도 정상화됐다는 알림이 발행된다.
여기서 폴더와 그룹을 만들어서 설정해야 한다.
Pending period는 10s로 설정했다.
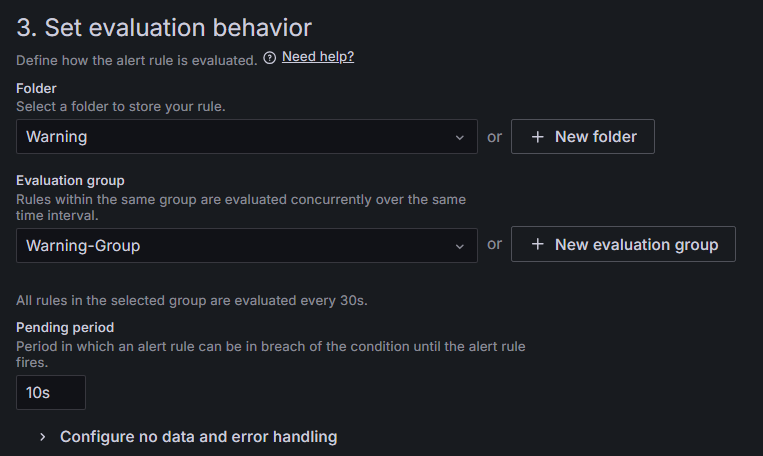
- Folder
별다른 설정은 필요없다. 이름만 알아서 지정해보자
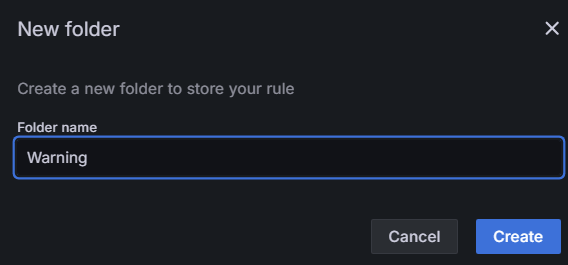
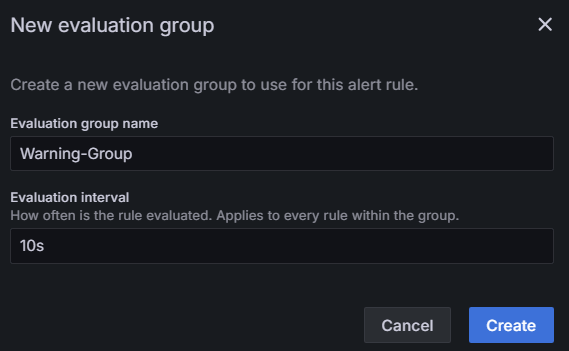
- Group
어떤 시간을 주기로 체크할지를 설정하면 된다.
알림 완료

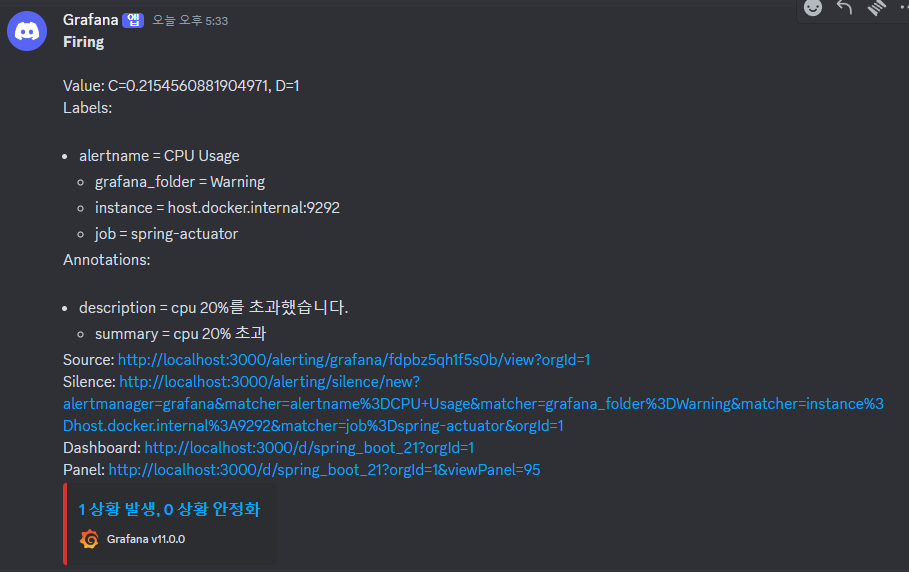
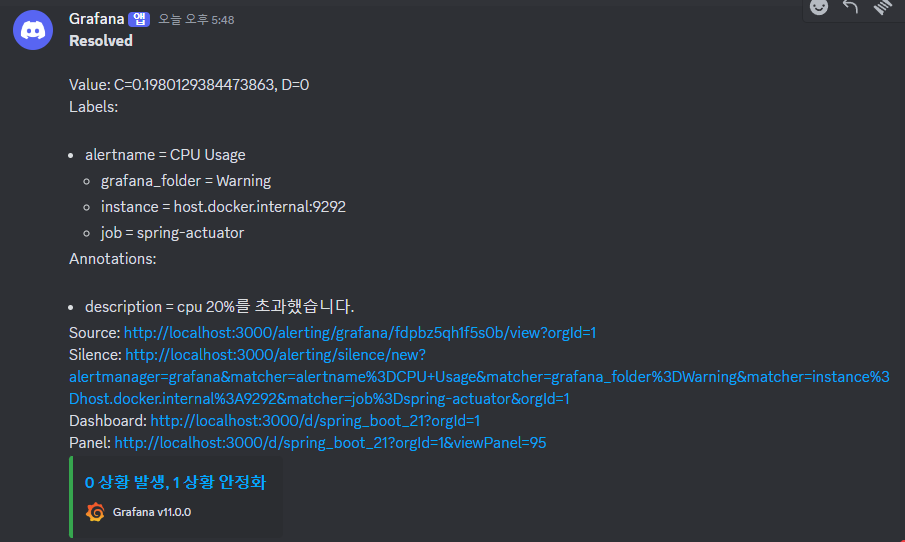
우리는 디스코드로 소통을 많이해서 디스코드로 진행했지만
이외에도 슬랙, 이메일 전송 등등 다양한 알림 기능을 지원하고 있다.
서버 상태 Rule
꼭 CPU 사용률을 사용할 필요는 없다.
지금 알림기능의 목적은 서버가 정상동작하는지를 파악하는 것이 목적이기 때문에
서버가 현재 동작하고 있는지만 정확히 파악하면 된다.
up을 통해서 파악해보면 된다.
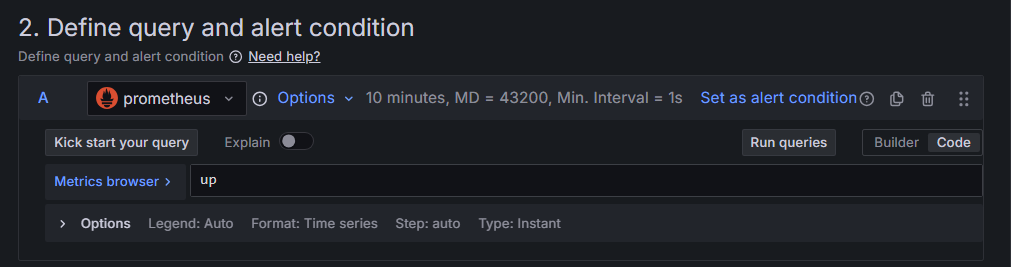
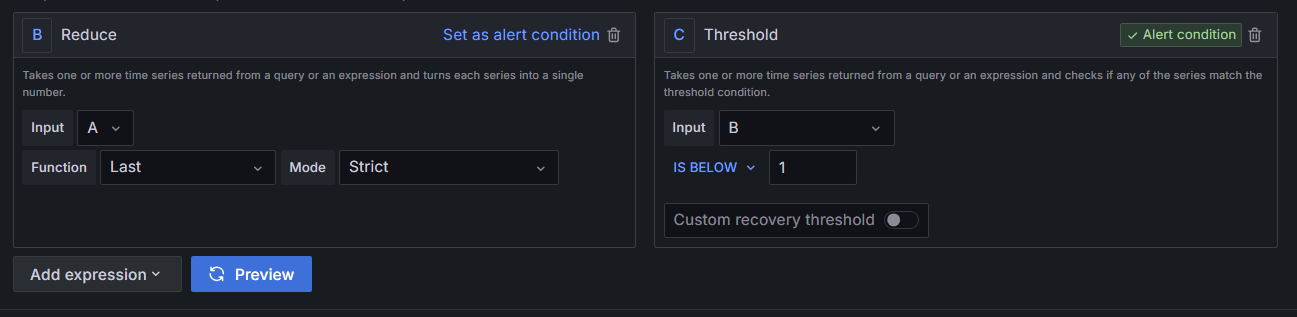
서버가 동작할 때는 1이고 동작하지 않을 때는 0이니 잘 활용해서 알림을 설정하자.
서버를 배포할 때 내려가는 시간이 10~30초 정도이기 때문에
Evalutaion interval 시간마다 체크하고 Pending period 시간을 적절하게 설정하면
배포할 때도 이 알림이 발생하는 것을 막을 수 있을 것이다.