기존 코드
현재 진행하는 서비스에서 엑셀 파일을 통해 고객정보를
서비스에 대량으로 등록할 수 있는 기능을 제공해야 하기 떄문에
다음과 같은 코드를 만들었다.
public List<ClientExcelDto> parseClientFile(MultipartFile excel) {
List<ClientExcelDto> dataList = new ArrayList<>();
try (InputStream excelStream = excel.getInputStream()) {
MultipartFile을 파싱할 수 있도록 파일 변환...
for (int rowIdx = 데이터 시작지점; rowIdx <= 데이터 끝지점; rowIdx++) {
Row row = worksheet.getRow(rowIdx);
행을 파싱해서 RowData라는 클래스로 변환...
해당 ClientExcelDto 유효성 검사 및 ClientExcelDto로 변환...
dataList.add(clientData);
}
} catch (IOException e) {
throw new InvalidFileException(e);
}
return dataList;
}기능 분리
해당 코드는 3가지 기능으로 분리할 수 있다.
- 루프를 돌면서 파일을 파싱하는 기능(
RowData) - 파싱한 데이터(
RowData)를 고객 데이터(ClientExcelDto)로 변환하는 기능 - 고객 데이터
ClientExcelDto의 유효성을 검사하는 기능
(너무 길진 않은지, 이상한 값이 들어있는 건 아닌지 등등)
모든 코드가 하나의 메소드 안에 있을 뿐만아니라 뒤섞여있다.
만약 엑셀파일이 아닌 txt 파일을 변환해야한다는 추가적인 사용자들의 요구가 있다면 어떻게 해야 할까?
현재 구조에서는 위 3가지 기능이 복잡하게 얽혀있기 때문에
쉽게 위와 같은 요구사항을 충족하는 기능을 추가하기 힘들다.
개선된 구조
3가지 기능을 분리해서 개선된 구조를 다음과 같이 생각해봤다.
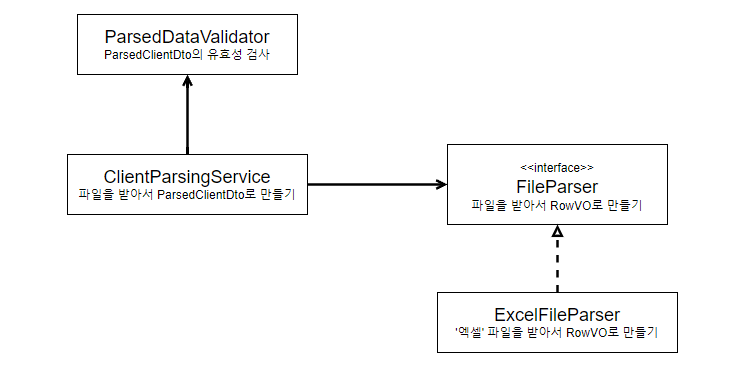
위와 같은 구조일 때 만약 서비스에서 다른 파일을 지원해야 한다면 FileParser의 구현체를 추가하면 될 것이다.
변경된 변수명
ClientExcelDto->ParsedClientDto
RowData->RowVO
FileParser
제일 먼저 파일을 파싱하는 기능을 만들어보자.
기대하는 동작
나는 이 FileParser의 구현체가 StringTokenizer처럼 동작했으면 좋겠다고 생각했다.
StringTokenizer st = new StringTokenizer("a b c d e f g");
// 다음 데이터가 있다면 동작
while (st.hasMoreTokens()) {
System.out.println(st.nextToken()); // 데이터 가져오기
}파일을 가져가서 nextToken()과 같은 메소드로 다음 줄의 파싱한 데이터를 가져오게 만들고 싶었다.
또한 파일을 다루기 때문에 해당 작업을 종료하면 파일을 닫아줘야 한다.
이에 따라 FileParser가 AutoCloseable를 상속받도록 만들었다.
인터페이스
그래서 다음과 같이 인터페이스를 만들었다.
public interface FileParser extends AutoCloseable {
/**
* 구현체가 파일을 지원하는지 확인
* init을 하기전에 호출해서 확인할 것
*/
boolean supports(MultipartFile file);
/**
* 파일 데이터를 내부적으로 연결하고, 데이터를 파싱할 위치를 파악함
* @param file 데이터를 가져올 파일
*/
void init(MultipartFile file);
/**
* @return 다음 Row에 파싱할 데이터가 있는지
*/
boolean hasMoreData();
/**
* 한 줄(행)의 데이터를 읽어서 반환
* 데이터가 없다면 null 반환
*/
RowVO nextRowData();
/**
* 잘못된 줄을 정확하게 사용자에게 말해주기 위해 제공
* @return 데이터가 시작하는 줄(행)의 index 반환
*/
int getStartRowIndex();
}구현체
.../file/parser/ExcelFileParser.java 깃허브 링크
엑셀을 파싱하는 구현체를 직접 쓰기에는 글이 너무 길어질 것 같아서 github 링크로 대체한다.
해당 부분은 글을 끝까지 읽어 본 후에 봐도 충분하다.
ParsedDataValidator
이 부분은 단순하다.
들어온 ParsedClientDto를 받아서 해당 DTO의 필드들의 유효성을 검사해주면 된다.
만약 전화번호라면 0~9 사이의 숫자들의 문자열이 들어왔는지, 문자열이 너무 길진 않은지 등등 유효성을 검사하면 끝이다.
서비스에서 더 긴 문자열을 지원해야 한다면 이 부분만 수정해주면 된다.
@Component
public class ParsedDataValidator {
private final int DETAIL_LENGTH_LIMIT = 40;
private final int ADDRESS_LENGTH_MIN_LIMIT = 10;
private final int ADDRESS_LENGTH_MAX_LIMIT = 40;
private final String PHONE_NUMBER_PATTERN = "^[0-9]{7,12}$";
private final int NAME_LENGTH_LIMIT = 20;
public boolean isInvalidData(ParsedClientDto rowData) {
return invalidateName(rowData.getName())
|| invalidatePhoneNumber(rowData.getPhoneNumber())
|| invalidateAddress(rowData.getAddress())
|| invalidateAddressDetail(rowData.getAddressDetail());
}
private boolean invalidateAddressDetail(String addressDetailString) {
return addressDetailString != null && addressDetailString.length() > DETAIL_LENGTH_LIMIT;
}
private boolean invalidateAddress(String addressString) {
return addressString != null
&& (addressString.length() > ADDRESS_LENGTH_MAX_LIMIT
|| addressString.length() < ADDRESS_LENGTH_MIN_LIMIT);
}
private boolean invalidatePhoneNumber(String phoneNumber) {
return phoneNumber != null && !Pattern.matches(PHONE_NUMBER_PATTERN, phoneNumber);
}
private boolean invalidateName(String name) {
return name == null || name.length() > NAME_LENGTH_LIMIT;
}
}DataParsingService
이제 앞서 만든 객체들을 연결해서 파일을 받아서 파싱하는 서비스를 만들어본다.
일단 만들기 전에 상태값을 가지는 싱글톤 객체에 대한 고민을 해결해보자.
고민
StringTokenizer를 생각해보자. 문자열을 생성자에 주고 해당 문자열(상태값)를 통해 값을 가져온다.
현재 FileParser도 특정 파일(상태값)을 가지고 해당 파일(상태값)을 통해 데이터를 파싱해온다.
만약 FileParser를 @Component로 등록하고 @Autowired를 통해 가져온다면 싱글톤 객체가 될 것이다.
특정 상태를 가지는 싱글톤 객체를 멀티 쓰레드로 접근하면 문제가 무조건 발생할 것이다.
마치 new StringTokenizer();를 하는 것처럼 요청이 올 때마다 객체를 생성해줘야 한다.
해결방안 1. New 연산자 사용
public List<ParsedClientDto> parseClientFile(MultipartFile file) {
FileParser parser = new ExcelFileParser();
...
}로컬 변수로 초기화해주는 방법이다.
이 방식은 매우 단순한 해결방법이다.
하지만 직접 초기화를 해주기 때문에 단위 테스트가 어려워진다.
또한 FileParser의 구현체가 추가됨에 따라 기존 코드를 수정해야한다.(OCP 위반)
해결방안 2. 프로토타입 빈 사용
다른 방식은 프로토타입 빈을 사용하는 것이다.
프로토타입 빈을 사용하면 사용자의 요청이 있을 때마다 빈을 생성해준다.
@Scope("prototype")
@Component
public class ExcelFileParser implements FileParser {
...
}이런식으로 FileParser의 구현체인 ExcelFileParser에 @Scope("prototype")를 적용하면 해당 FileParser의 Bean을 찾을 때마다 객체를 만들어준다.
프로토타입 빈은 싱글톤 객체에 @Autowired를 사용해서 주입할 경우 문제가 발생하니 주의하자.
이제 DataParsingService에서는 FileParser의 리스트를 검색한 후 쭉 뽑아내면서 지원하는 Parser를 골라 쓰면 되는 것이다.
Bean을 검색할 때는 ObjectProvider를 쓰면 된다.
ApplicationContext를 직접 사용할 수 도 있지만 이 객체는 하는 일이 너무 많기 때문에 무겁다.
ObjectProvider는 의존 객체(Bean)를 검색하는 용도로 사용하기 때문에 가볍게 사용할 수 있다.
private final ObjectProvider<List<FileParser>> fileParserProvider;
public List<ParsedClientDto> parseClientFile(MultipartFile file) {
FileParser parser = getParser(file);
...
}
private FileParser getParser(MultipartFile file) {
for (FileParser fileParser : fileParserProvider.getObject()) {
if(fileParser.supports(file))
return fileParser;
}
throw new FileNotAllowedException();
}최종 코드
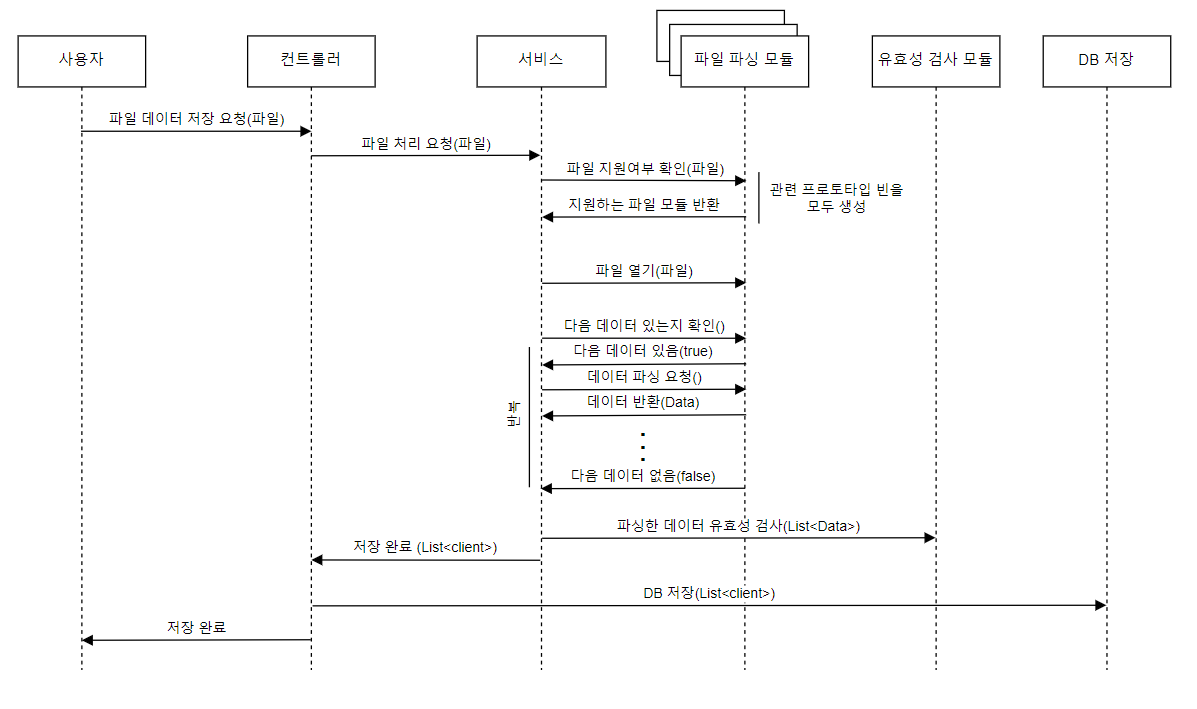
@Service
@RequiredArgsConstructor
public class DataParsingService {
private final ParsedDataValidator parsedDataValidator;
private final ObjectProvider<List<FileParser>> fileParserProvider;
public List<ParsedClientDto> parseClientFile(MultipartFile file) {
List<ParsedClientDto> dataList = new ArrayList<>();
FileParser parser = getParser(file);
try (parser) {
parser.init(file);
int startRowIndex = parser.getStartRowIndex();
int count = 0;
while (parser.hasMoreData()) {
RowVO rowVO = parser.nextRowData();
int rowIdx = startRowIndex + count;
ParsedClientDto clientData = convertDataToDto(rowIdx, rowVO);
dataList.add(clientData);
count++;
}
} catch (Exception e) {
throw new InvalidFileException(e);
}
return dataList;
}
/**
* 알맞는 FileParser를 가져옴
* @param file "sample.xlsx"
* @return 엑셀을 파싱할 수 있는 ExcelParser
*/
private FileParser getParser(MultipartFile file) {
for (FileParser fileParser : fileParserProvider.getObject()) {
if(fileParser.supports(file))
return fileParser;
}
throw new FileNotAllowedException();
}
/**
* 유효하지 않은 데이터
*/
private boolean isValidData(ParsedClientDto clientData) {
return !parsedDataValidator.isInvalidData(clientData);
}
/**
* RowVO -> ParsedClientDto 변환
*/
private ParsedClientDto convertDataToDto(int rowIdx, RowVO rowVO) {
// 중요한 부분은 아니지만 코드가 길기 때문에 생략...
}
}
개선 완료
좀 더 긴 고객 정보를 허용해도 된다면 ParsedDataValidator에서 로직을 변경하면 될 것이다.
데이터를 파싱하고 어떤 추가적인 정보들이 들어가야 한다면 DataParsingService에서 로직을 변경하면 될 것이다.
Excel 파일을 파싱하는 라이브러리를 변경하거나, 오류가 발생한다면 ExcelFileParser를 수정하면 될 것이다.
그리고 서비스에서 Excel 파일 뿐만 아니라 .txt형식의 텍스트 파일도 지원을 해야 한다면 FileParser에서 텍스트 파일을 파싱할 수 있는 구현체를 추가하면 될 것이다.
좀 더 개선해야할 사항
지금은 엑셀 파일을 파싱해올 때 데이터의 위치를 지정해서 파싱해오고 있다.
초기화(init)를 하는 시점에 데이터의 위치를 동적으로 검색 기능을 추가한다면 더 좋을 것 같다.