[논문 리뷰]Generating Long-form Story Using Dynamic Hierarchical Outlining with Memory-Enhancement

25' NAACL main
서론
선행 연구
- 장편 이야기 생성을 위한 다양한 시도가 있었다.
- plan-and-write 프레임워크 기반의 연구: 인간의 글쓰기 과정을 모방하여 이야기의 개요 단계와 작성 단계를 분리하였다. 고정된 개요는 유연성이 부족하다. -> 작성 중 발생할 수 있는 불확실성에 대응하기가 어렵다. 따라서 중복되거나 모순된 내용이 발생하고 이야기의 일관성과 자연스러움이 떨어지게 된다.- 인간 참여 기반 상호작용적 생성 연구: 개요를 고정시키지 않고, 인간의 상호작용이나 문맥에 따라서 동적으로 이야기를 진행시키는 연구가 있었다. 개요의 유연성은 향상되지만, 전체적인 개요 제어가 어렵고 이야기 구조가 불완전해질 수 있다.
- knowledge graph와 LLM을 결합하여 더 일관된 문맥과 정확한 정보를 제공하도록 시도하는 연구: KG를 단순히 LLM에 입력해서 결합하거나, 별도의 모듈을 통해서 합치는 연구가 진행되었다. 이야기가 길어질 수록 과거 내용을 잊거나 왜곡하는 장기 기억의 한계가 두드러진다. LLM은 긴 문맥을 기억하거나 활용하는 능력이 부족하기 때문에 story generation에 영향을 미치게 된다.
제안한 방법
구조
-
Dynamic Hierarchical Outlining with Memory-Enhancement (DOME)라는 모델을 제안하였다. DOME은 DHO 모듈과 MEM 모듈로 구성되어 있다.
-
Dynamic Hierarchical Outline (DHO) 도입
- 이야기 생성 전, 사용자의 입력을 바탕으로 rough outline을 생성하여 전체적인 이야기 구조를 만든다.- 그 후, 상세한 아웃라인을 생성하고 각 아웃라인에 따라서 순차적으로 이야기를 생성한다.
- 상세한 아웃라인은 이전에 생성된 이야기에 맞춰서 점진적으로 확장된다.
- 이를 통하여 생성되는 이야기의 유연성을 높이고, 예측할 수 없는 이야기에 대응할 수 있게 된다.
-
Memory Enhancement Module (MEM) 도입
- 이야기 생성 중, 콘텐츠와 사용자의 입력을 저장한다.- 생성된 스토리를 시간에 따른 지식 그래프 형태로 저장하고, 이 그래프를 사용해서 이전 이야기와 관련된 중요한 정보를 검색하여 콘텐츠 생성에 활용한다.
-
새로운 평가지표 도입
- Temporal Conflict Analyzer라는 충돌 탐지 행렬ㅇ르 제안해서 문맥 일관성을 자동으로 평가할 수 있게 하였다.- 사람의 선호도와 일치하는 평가 결과를 보여주었다.
- 충돌 quadruple과 전체 quardruple의 비율을 계산하여 측정한다.
- 생성된 이야기의 TKG 내의 quadruple을 규칙에 따라 순차적으로 그룹화해서 잠재적인 충돌 정보를 계산하였다.
선행 연구의 한계 해결 방법
- 예측할 수 없는 작성 과정에 대한 문제 해결
- 기존의 plan-and-write 프레임워크는 예상하지 못한 상황에 적응하는 것에 어려움이 있었다. DOME은 rough 아웃라인과 상세한 아웃라인을 결합해서 플롯의 일관성과 완전성을 보장하였다. - 맥락 일관성의 부족 문제 해결
- 이야기의 길이가 길어짐에 따라서 맥락의 불일치나 정보의 누락이 발생하는 문제가 있었다. DOME은 MEM 모듈을 통해서 이야기의 중간에 발생할 수 있는 맥락의 일관성 문제를 해결한다.
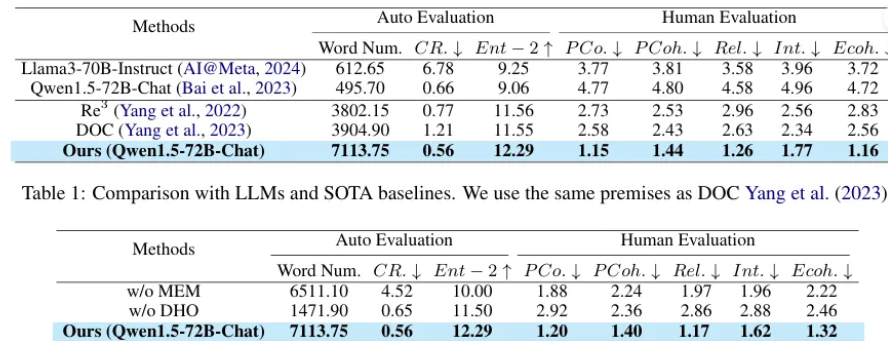
실험
- 대조군: base LLM (Llama3-70B-Instruct, Qwen1.5-72B-Chat), 기존의 LLM story generation 방법들 (Re, DOC)
- 실험군: DOME (Qwen1.5-72B-Chat)
평가 지표
- 자동 평가 지표
- n-gram entropy: 이야기에 포함된 단어의 다양성을 평가한다.- conflict rate: 이야기의 문맥 일관성을 평가한다. 논문에서 제안한 방법이다.
- 인간 평가
- plot completeness: 생성된 이야기가 이야기 이론에서 언급되는 모든 단계를 잘 다루고 있는지 평가한다.- plot coherence: 이야기 전개가 얼마나 유창한지 평가한다.
- relevance: 생성된 이야기와 입력 전제 간의 일관성을 평가한다.
- interesting: 독자가 읽을 때 얼마나 흥미로운지 평가한다.
- expression coherence: 이야기의 문맥 일관성을 평가한다.
결과
- 자동 평가와 인간 평가 모두 좋은 성능을 달성했기 때문에 선행 연구의 문제점이 해결되었다고 생각한다. 하지만 대체로 논문에서 제안한 방법을 사용하였기 때문에 완벽히 신뢰하기는 어렵다고 생각한다.
- 또한, 생성된 문장 수가 313개였기 때문에 long-form이라고 할 수 있다고 생각한다.
- 해당 논문에서 제안하는 DHO와 MEM은 기존에 있던 방법들이다. 평가 방법과 관련해서 contribution을 인정 받은 것 같다.

AI 전공. Story Generation, Agent 분야 논문을 주로 리뷰합니다. RAG도 조금 합니다.