[논문 리뷰]MORPHEUS∗:Modeling Role from Personalized Dialogue History by Exploring and Utilizing Latent Space

서론
선행 연구의 특징/한계
- DHAP: 대규모 데이터셋에서 관련 대화를 retrieval하여 활용하는 방식을 연구함.
- 대화 기록을 활용해서 역할을 모델링하는 것에는 효과적이지만 코퍼스 크기의 한계, 검색 기반 방식의 비효율성 문제가 존재함. - PersonaWAE: latent space에서 사용자 측의 특징을 모델링하는 방식을 연구함.
- 응답자의 성격을 고려하지 않는다. - PersonaPKT: 명시적 페르소나 데이터를 활용해서 모델을 두 단계에서 걸쳐서 fine-tuning하는 방법을 제안함.
- 각 target role에 대한 추가적인 학습이 요구된다. - CLV: 명시적 페르소나 설명에는 특정 관점이 숨겨져 있다고 주장하는 연구임.
- latent variable space에서 페르소나 정보를 clustering하여 대화 기록만으로 정보를 획득하는 방식을 적용함.
선행 연구의 한계 해결 방법
- 페르소나 코드북 생성: 기존 페르소나 정보를 latent space에서 압축적으로 표현하는 방법을 통하여 역할을 효과적으로 학습하고자 한다.
- 대화 기록을 활용한 역할 추론: 대화 기록에서 페르소나 정보를 추출하여 코드북을 업데이트하고, 역할을 자동으로 일반화한다. -> 이를 통하여 새로운 역할에도 적용할 수 있는 모델을 구축한다.
- 3단계 학습 방법 적용: 모델이 역할을 인식하도록 학습한다. 페르소나 코드북을 구축하여 역할을 latent space 공간에서 표현하도록 한다. 코드북을 기반으로 대화 이력에서 역할을 예측하여 대화를 생성한다.
- 위의 과정을 통하여 MORPHEUS는 명시적인 페르소나 데이터 없이도 개인화된 응답을 생성할 수 있으며, 새로운 역할에 대한 일반화 능력을 갖춘다.
제안한 방법
- 역할의 집합인 U가 주어졌을 때, P는 해당 역할(ui)에 대한 텍스트 기반 페르소나 데이터를 의미한다.
- ui와 uj 사이에 multi-turn 대화 이력 C가 존재한다. 현재 turn에서는 ui가 응답한다.
- 목표는 C는 기반으로 ui의 특성에 부합하는 개인화된 응답 R을 생성하는 것이다.
- 외부의 명시적 페르소나인 Pui 없이도 C에 내재된 페르소나 정보를 활용할 수 있어야 한다.
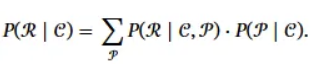
- 응답을 생성하는 확률은 모든 페르소나 가능성을 고려한 가중 평균이다. 모델은 대화 히스토리로부터 페르소나를 추정하고, 그 페르소나를 바탕으로 응답을 생성한다.
세 가지 학습 단계
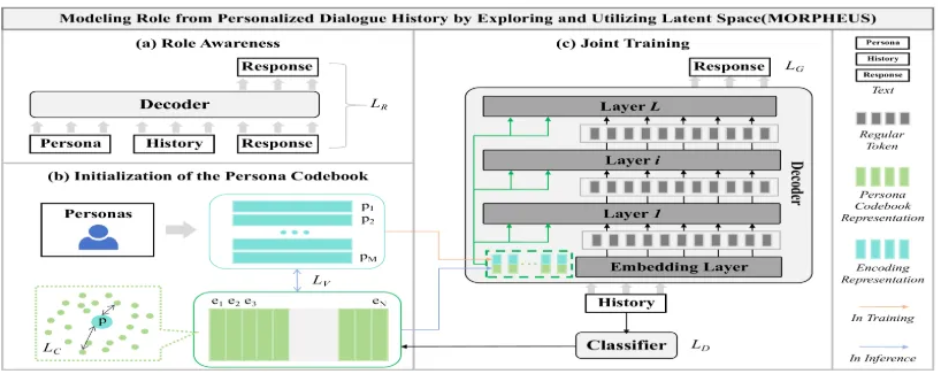
1. 모델이 역할을 인식하도록 학습하는 단계
- 대규모 코퍼스에서 훈련된 unconditional decoder는 페르소나, 역할 정보 등을 인식하지 못한다.
- 모델이 페르소나 정보와 대화 간의 관계를 인식하도록 fine-tuning한다.
- 역할 정보를 hidden state 형태로 넣고 학습하면 모델의 페르소나 인식 능력을 향상시킬 수 있다는 것을 확인하였다.
- 역할에 대한 페르소나 문장을 인코딩하여 pi로 표현하고, 키와 값을 모델의 앞부분에 삽입한 뒤 fine-tuning을 수행하였다.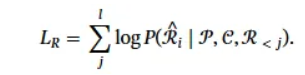
- ^Ri는 정답인 응답, R<j는 응답의 앞부분이다. auto-regressive 방식이다.
- 페르소나 정보와 대화 히스토리가 주어졌을 때, 정답 응답을 잘 예측하게 만든다.
- 페르소나 코드북 초기화
- 모델이 대화 이력과 코드북만으로도 역할을 학습할 수 있게 하게 위함이다.
- 특정 페르소나 인코딩 표현을 일반화하여 초기화할 경우, 무작위로 초기화하는 것보다 훨씬 성능이 좋다는 것을 발견하였다.
- N은 latent space의 크기, d는 hidden의 크기를 의미한다.
- PC가 다양한 페르소나 정보를 latent space 내에서 압축적으로 표현하는 것이 목표다.
- 페르소나를 문장 단위로 나누고, 각각을 인코더에 넣어서 벡터로 변환한다.
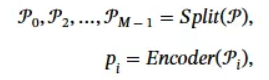
- 페르소나 문장을 M개의 문장 단위로 나누고, 각각을 벡터로 인코딩하여 pi를 도출한다.
- 세 가지의 초기화 방식을 제안한다.
- sequential initialization: 현재 배치에서 추출한 pi들을 순차적으로 PC에 삽입한다.
- average initialization: 배치 내 pi를 평균 내서 PC에 삽입한다.
- EM 초기화: pi들이 여러 정규분포 중 하나에서 샘플링되었다고 가정하고, 각 정규분포의 평균 uk를 ek로 사용한다.
- joint training
- 대화 이력을 입력으로 받고, 암묵적으로 나타난 페르소나 정보로부터 페르소나 코드북 표현을 샘플링한다. 이를 기반으로 개인화된 응답을 생성한다.
- training은 두 가지 동시 단계로 구성된다.
- code index prediction: 대화 이력 C로부터 숨겨진 상태 c를 추출하고, MLP 분류기에 넣어서 PC내 가장 가까운 인덱스 k를 예측한다. PC 학습은 pi와 가장 가까운 ek를 선택하고, VQ-VAE 방식으로 손실을 최소화한다. pi와 ek가 서로 가까워지도록 만들어서 코드북 벡터들이 더 정확하게 성격을 표현하도록 한다. 페르소나 인코딩 전체를 연결한 후, 이를 기반으로 응답을 생성한다.
선행 연구의 한계 해결 방법
- 선행 연구들은 페르소나 정보가 외부에서 주어져야만 자연스러운 개인화 응답을 생성할 수 있었다. 따라서 외부 페르소나에 대한 의존도가 높았고, 역할이나 성향에 대한 이해가 부족하였다. 본 논문에서는 대화 히스토리만으로도 화자의 페르소나를 학습하고 응답을 생성할 수 있게 하였다.
- Role Awareness를 도입: 페르소나 감지 능력이 강화되었다.
- Persona Codebook 도입: 추론시 페르소나 문장이 필요 없어졌다.
- EM 기반 코드북 초기화: 성향을 더 정확하게 표현할 수 있게 되었다.
- 대조학습 + 코드 인덱스 예측 학습: 외부 정보 없이도 개인화된 응답을 생성할 수 있게 되었다.
실험
- 실험군: MORPHEUS
- 대조군: 비개인화 모델(Seq2Seq, GPT-2), 명시적 검색 기반 개인화 모델(DHAP, MAP), 암묵적 모델링 기반 개인화 모델(PersonaPKT, CLV)
평가 지표
- 영어: ConvAI2
- 중국어: Baidu PersonaChat(훈련할 때만 페르소나 문장을 사용하고, 평가에서는 사용하지 않았다.)
- 자동화된 평가
- coherence(일관성, 응집력): BLEU-1, BLEU-2, ROUGH-L, Coh-Con.Score- diversity(다양성): Dist-1, Dist-2, Self-BLEU
- Consistency(페르소나 일관성): Con.Score, Coh-Con.Score, P-Co (Persona Cosine)
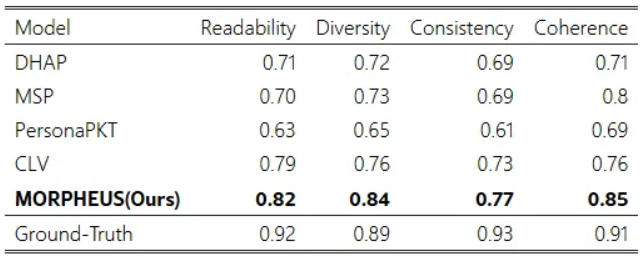
- 인간 평가
- 100개 샘플에 대하여 3명의 평가자가 읽기 쉬움, 다양성, 일관성, 응집력 항목에 따라 0~1의 점수를 부여하였다. fleiss Kappa = 0.65.
결과
- 자동화된 평가 결과
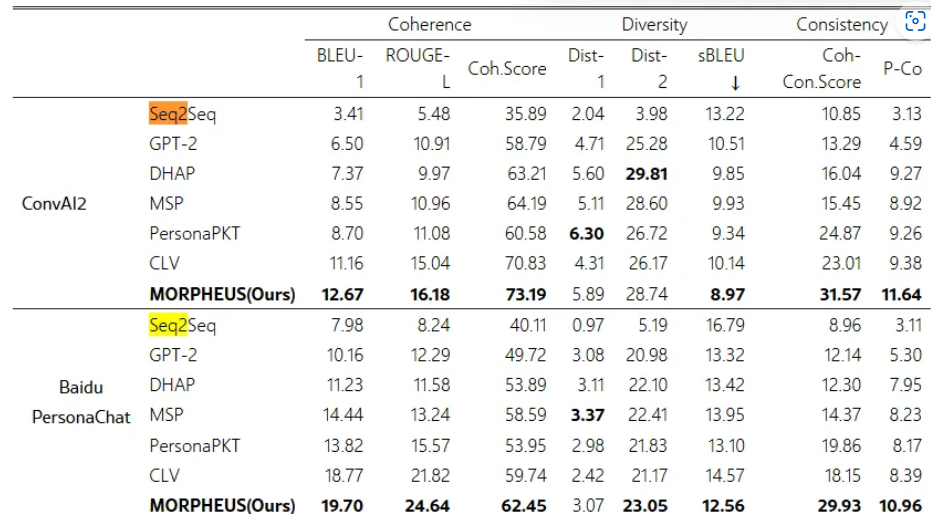
- 인간 평가 결과
개선 방법
- 미리 학습된 고정된 역할을 활용하는 것이 아닌, 동적으로 갱신할 수 있는 모델이면 더 좋을 것 같다.
- 다국어로 확장할 수 있으면 좋겠다. 해당 논문에서는 영어와 중국어로만 수행하였다.
- 페르소나 코드북이 블랙박스이기 때문에 설명 가능하게 만드는 연구를 수행할 수 있을 것 같다.

AI 전공. Story Generation, Agent 분야 논문을 주로 리뷰합니다. RAG도 조금 합니다.