[논문 리뷰]Generative Agents: Interactive Simulacra of Human Behavior

1. 서론
선행 연구
선행 연구들은 AI와 인간의 상호작용을 위한 시도를 해왔다. 또한 자연어를 통해서 interaction할 수 있는 수준까지 LLM이 발전하였다.
이전까지는 rule-based로 agent가 만들어져서 간단한 상호작용을 하는 것에는 문제가 없었다. 하지만 현실 세계는 훨씬 복잡해서 모든 것을 하드 코딩할 수는 없다. 또한, 오픈월드에서 believable한 agent는 아직 만들어지지 않았다.
선행 연구의 한계 해결 방법
rule-based가 아닌 generative agent를 만들고자 한다.
generative agent를 만들면 (1) 대화형 시스템을 위해서 인간 행동을 대리하는 agent를 만들 수 있다. (2) NPC가 believable behavior를 하면 사용자 경험의 질이 올라간다. (3) generative agent가 시뮬레이션 환경을 제공해줄 수 있다.
2. 제안한 방법
Memory, Planning, Reflection
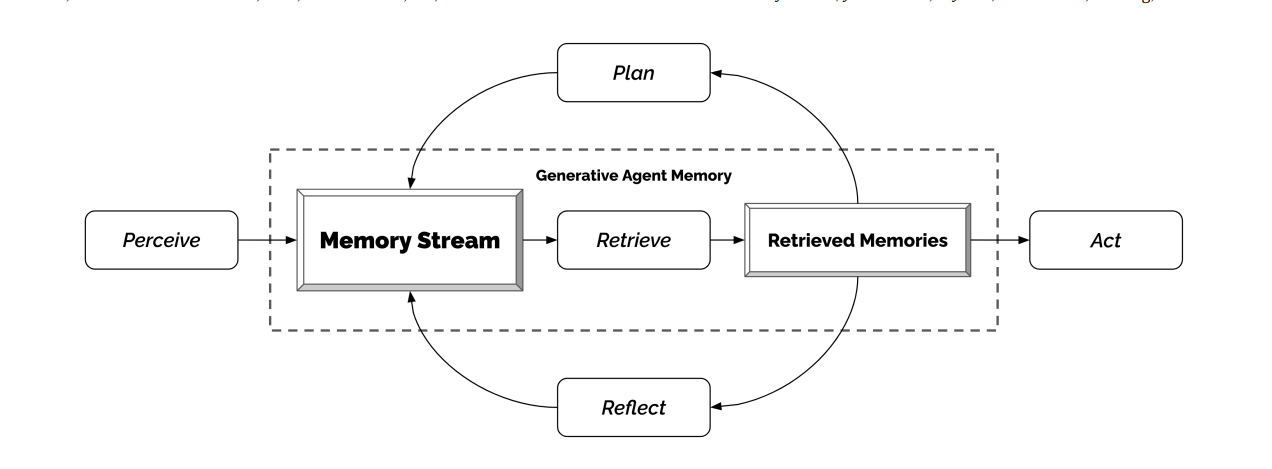
Generative Agent의 메모리 구조
Memory, Planning, Reflection을 통해서 believable한 agent를 만든다.
Memory and Retrieval
메모리에 점수를 부여해서 일정 점수를 넘으면 프롬프트에 해당 기억을 저장해두게 한다. 따라서 memory stram은 포괄적인 기억을 유지할 수 있게 된다. (1) Recency, (2) Importance, (3) Relevance의 점수를 합쳐서 최종 점수를 만들고 정규화해서 상위 순위의 메모리를 프롬프트에 추가한다.
Recency: 최근에 접근했던 정보에 더 높은 점수를 부여한다.
Importance: agent가 더 중요하다고 생각하는 객체에 더 높은 점수를 준다. 객체가 만들어질 때 바로 rating한다.
Relevance: 현재 행동과 관련이 있을 때 더 높은 점수를 준다. 코사인 유사도를 이용해서 memory와 guery의 메모리 임베딩 벡터의 유사도를 구한다.
Reflection
agent가 더 적합한 행동을 할 수 있또록 한다. 앞에서 계산한 점수가 임계값을 넘으면 작동하는 메모리다. 논문의 에이전트들은 하루에 2~3번 발생했다고 한다.
최근 100개의 행동을 가지고 3개의 퀄리티 좋은 질문을 LLM이 만들도록 한다. 이 질문들을 이용해서 검색하고 답변을 수집한다. 수집된 답변들을 이용해서 트리를 만들게 한다. leaf node는 base observation을 나타내고 none-leaf node는 추상적이고 높은 레벨을 나타낸다.
Planning and Reacting
미래의 일을 계획할 수 있게 한다. 적절한 시간에 알맞은 일을 할 수 있어야 한다. 계획한 것이 memory stram에 들어간다.
하루의 계획을 5~8개로 쪼개고 이것을 memory stram에 기록한다. 위의 계획을 시간 단위로 다시 쪼갠 후, 분 단위로 쪼갠다. 이 과정에서 콜 비용이 많이 들고 계산 시간이 느려지는 문제점이 발생하게 된다.
Agent가 환경에서 행동을 하며 관찰한 정보가 memory stram에 들어간다. 이 정보와 계획을 비교해서 계획을 실행할지 말지 스스로 정하게 한다.
샌드박스 환경 구현
샌드박스 환경을 구현해서 Agent가 주어진 환경에서 행동할 수 있도록 한다. Json 형식으로 각 agent의 정보가 저장되어 있는데, 이 정보를 이용해서 적절한 행동을 할 수 있도록 한다.
하나의 환경 내에서 새로운 데이터가 쌓일 수록 더 적절한 행동을 할 수 있게 된다. 데이터가 쌓일 때 트리를 생성하게 되는데, 트리의 edge가 샌드박스 환경 내에서의 관계를 나타낸다. 이 관계를 자연어로 바꿔서 agent에게 전달한다. Agent가 해당 환경 내에 있을 때만 트리가 업데이트된다.
구조에 대하여
이 논문에서는 메모리를 참조하여 더욱 believable한 generative agent를 생성할 수 있는 방법을 제안하였다.
하지만 구조상 agent의 모든 행동이 설명 가능한 것 같지 않다. 또한 api 콜 비용이 너무 크고 시간도 오래 걸리는 방법이다.
3. 실험
평가 1
Agent가 이전 내용을 참조해서 미래를 제대로 계획하고 반응하고 행동할 수 있는지 확인한다.
인터뷰 방식을 사용하여 ablated experiment를 수행한다. 인터뷰 질문에는 5가지가 포함된다. (1) Self-knowledge, (2) Memory, (3) Plans, (4) Reactions, (5) Reflections.
Human baseline을 만들어두고 비교하여 generative agent의 성능을 측정하였다. Kruskal-Wallis test 방법을 이용해서 평가 점수를 냈다.
평가 2
End-to-End 방식으로 평가하였다. 정보 확산의 여부를 측정하였다.
정보 확산은 사회적으로 자명한 현상이기 때문에 중요한 정보가 있으면 agent끼리 소문을 내야 한다고 가정하였다. 인터뷰 방식을 통해서 소문이 났는지 확인하였다. 또한, 확실히 하기 위하여 memory stream을 확인하였다. 처음부터 memory stram을 활용하였으면 콜 비용을 낮출 수 있었을 텐데 왜 이런 구조를 취한 건지 궁금하다.
Agent의 network density를 구하는 식을 만들고 측정해서 network density가 0.167에서 0.74로 증가했다는 것을 확인하였다. 정보 확산이 잘 발생한 것이다.
그 예시로, '발렌타인데이 파티를 하고 싶다.'는 내용을 하나의 agent에만 넣어줬는데 13명의 agent가 파티에 대해서 알게 되었다. 또한, 소문을 듣고 파티에 참석한 agent가 존재한다.
실험에 대하여
인터뷰 방식은 객관적인 지표라고 할 수 없다고 생각한다. 하지만 논문에서 주장하는 believable agent는 사람과의 상호작용을 위한 것이기 때문에 사람이 보기에 적절하다고 생각되면 높은 점수를 받는 것에 모순은 없다고 생각한다.
4. 결과
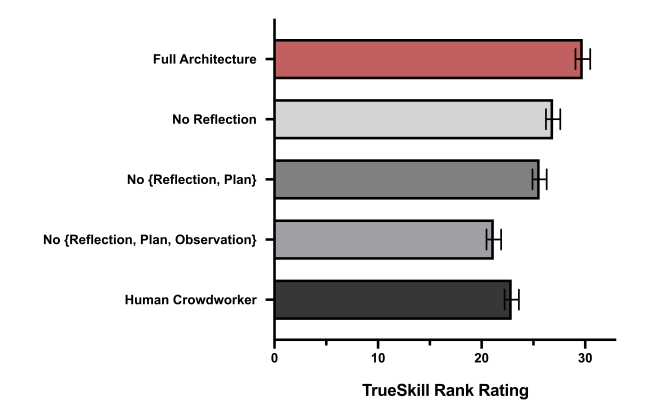
ablation 평가의 결과
이 논문에서 제안한 메모리를 다루는 방법이 논문에서 제안한 평가 지표에서 좋은 점수를 달성하였다. 비교 대상인 model이 없기 때문에 적절하고 객관적인 평가였는지 비교할 수가 없다.
소문 확산 측면에서 보다 believable한 agent가 됐다고 생각한다.
하지만 메모리 관련해서는 아직 부족한 점이 많다고 생각한다. 발렌타인데이 파티에 대한 소문을 들은 12명의 agent 중 5명만 파티에 참석하였다. 참석하지 않은 agent들은 흥미롭다고 반응하면서도 참석하지 않은 것인데, (1) 단순 error인지, (2) 속마음과 겉마음이 분리되어 있는 것인지, (3) 계획을 제대로 만들 수 없는 것이 아닌지에 대한 분석이 부족하다고 생각한다.
또한, 이 논문에서는 메모리를 잘 다루지 못해서 특정 행동을 전형적이지 않은 장소에서 수행한다는 결과를 보고했다.
따라서 메모리를 저장하는 것은 잘 하지만, 메모리를 다루는 것은 잘 못하는 것 같다.
