[논문 리뷰]Mamba: Linear-Time Sequence Modeling with Selective State Spaces

Language modeling위주로 리뷰합니다.
1. 서론
선행 연구
attention을 이용하게 되면서 모델의 빠른 훈련이 가능해졌고 성능이 좋다. self-attention은 복잡한 데이터를 모델링할 수 있지만 (1) 토큰 제한을 벗어나거나 (2) 토큰 수가 많으면 원하는 결과를 얻지 못한다. 또한 (3) cost가 매우 높고 (4) 데이터가 많아지면 하나 하나 search해야 하기 때문에 시간이 linear하게 증가한다는 문제점이 존재한다.
선행 연구의 한계 해결 방법
이 논문에서는 non-transformer를 기반으로 훈련 속도를 증가시키면서 transformer만큼의 성능을 확보하고자 한다.
Language modeling에서 최초로 선형 시간이 소요되며 transformer와 비슷한 성능을 가진 모델을 만드는 것에 성공하였다. 유사한 크기의 transformer와 비교해서 5배 좋은 처리량을 보였다. 또한 Mamba-3B의 성능은 두 배 크기의 transformer와 비슷했다.
2. 제안한 방법
모델 구조
https://youtu.be/JjxBNBzDbNk?si=pz1S_wfoDHI6Q2D9 참고한 영상
Mamba의 구조를 이해하기 위하여 필요한 사전 정보들
-
SSM: 입력 시점부터 t 시점까지 입력 값을 확보하였을 때 t 시점의 출력을 예측할 수 있게 해주는 시간에 따라 변화하는 함수다. 연속적인 시간 도메인에서 사용된다. 입력 u(t)가 X(t)를 거쳐서 y(t)를 만든다. Convolutionize할 수 있기 떄문에 빠른 훈련이 가능하다. Convolutionize는 처음부터 t-1까지 미리 연산을 해두고 사용하는 것이다.
-
LSSL: MLP 레이어 없이 SSM을 쌓는 구조다. Transformer처럼 stacking을 통하여 성능을 높이고자 하였다. SSM의 파라미터 중에서 A matrix를 어떻게 다룰 것인지에 집중한다. A matrix는 memory를 어떻게 업데이트할지 정하는 것을 담당한다. non-transformer 구조에서 중요한 부분이다.
-
S4: A matrix를 대각화해서 계산 cost를 줄인 모델이다.
-
H3: Transformer에서 language modeling을 겨냥해서 만든 모델이다. 단순히 stacking하는 것이 아니라 하나의 block 단위의 복잡한 연산이 추가된다. 특정 연산을 추가해서 주어진 task를 더 잘하게 만든다.
Mamba의 구조
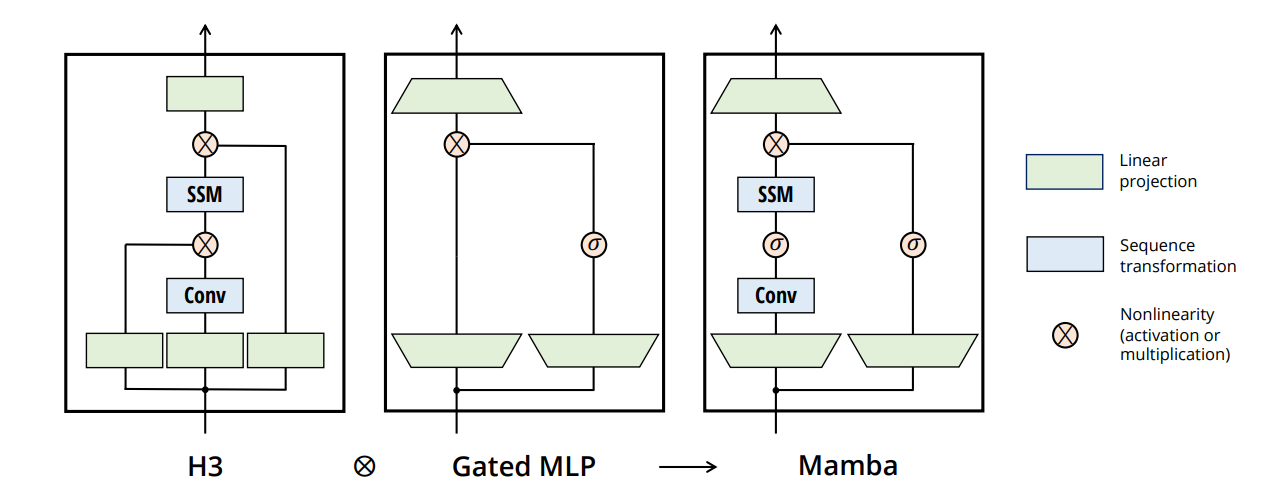
- d_model 차원의 토큰이 입력되면 linear projection을 통해서 d_model이 d_inner로 확장이 되며 토큰은 d_inner 차원의 벡터가 된다. d_inner 요소들 각각에 대해서 d_state 차원 크기의 hidden_state 벡터가 만들어진다.
- Gated projection 연산에서 어떤 element를 걸러낼지 결정한다. Input projection이 결과로 출력되기 전에 gated projection을 거친다. 이 과정이 LLaMA와 유사하다.
- H3처럼 SSM에 input을 넣기 전에 convolution을 태운다.
- H3과 Gated MLP를 interleave해서 mamba를 만든다. 단순히 SSM을 stacking하는 것이 아니라 SSM과 연산이 포함된 block을 stacking하는 것이다.
- SSM, S4 모델들은 토큰에 따라서 다른 연산이 이루어지지 않는다는 단점이 존재한다. 즉, input마다 연산이 달라져서 convolution을 그냥 적용할 수가 없다. 따라서 hardware-aware parallel scan이라는 방법을 사용해서 이 문제를 해결한다. selectivity를 도입해서 해결하였다.
3. 실험
대조군
Mamba의 대조군은 multi-head attention과 SSM에서 파생된 모델들이다. Attention 모델들의 성능은 Mamba보다 좋지만, 시간 복잡도가 훨씬 높다. 따라서 비슷한 성능을 보이기만 해도 개선된 것이라고 주장하였다.
평가
이 논문에서는 두 가지 task를 제안하고 평가하였다.
1. Selective Copying: memorization ability를 확인하기에 좋은 평가 방법이다.
2. Induction Heads: in-context learning ability를 확인하기에 좋은 평가 방법이다.
4. 결과
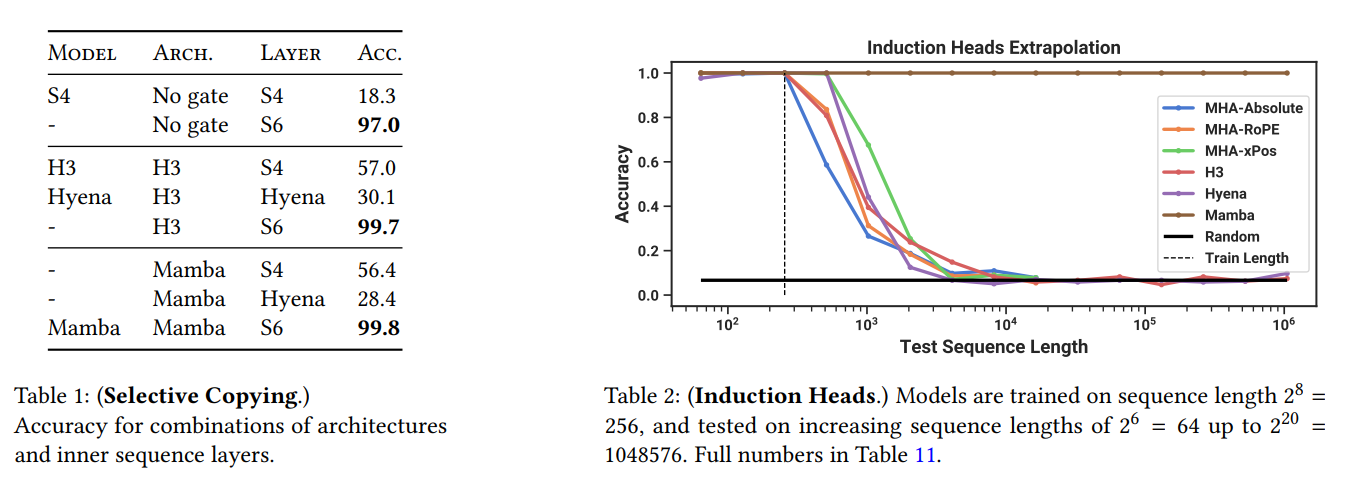
Mamba는 attention-free 모델들 중에서 가장 transformer와 유사한 성능을 보였다. 또한 O(n^2)보다 좋은 시간 복잡도를 달성하는 것에 성공하며 선형 시간 안에 연산을 끝냈다.
