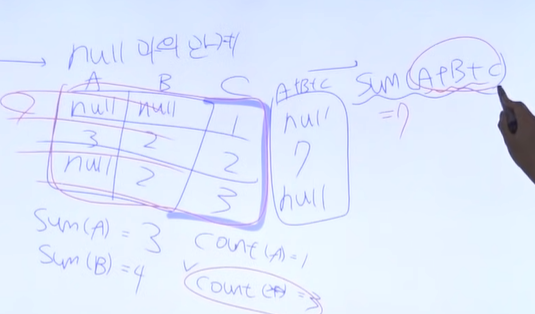
윈도우 함수
=====>>> 무조건 문제풀기
rows -> "차이점"
ranncte -> 같은 값
rank: 중복 건너 뛰기 (1, 1, 3, 4)
dense_rank : 건너뛰기x (1, 1, 2, 3)
partition by
order by
💥💥💥💥💥계층형 질의
- Prior 자식데이터 = 부모데이터
프자부
== 부모데이터 = prior 자식 데이터 - 부모에서 자식으로 가는 경우 순방향
부자순

절차형 PL/SQL
Exception => 생략o
Procedure, trigger, userdefine
=> 차이점 표 주의해서 보기
데이터 모델링
업무 -> 데이터 모델화
- 데이터 구조화 "업무
- 데이터 "자체", "관계"
- 객체 지향
엔터티
1.업무상 관리하고자 하는 대상
2. 엔터티의 특징
- 관게 하나 이상
- 업무에서 사용되야함, 프로세스에 이용
등등
- 엔터티 분류
- 유형 엔터티
- 개념 엔터티
- 사건 엔터티
속성
- 고유한 성질
인스턴스의 집합 - 분류 (정의 확인하기)
- 기
- 설
- 파
도메인

데이터 유형
크기
관계
식별자
IE 표기법
각진 박스, PK 맨 위에, 줄하나 긋고
필수 관계 |, 선택관계 O|
Barker 표기법
둥근 박스
#
ㅇ
ㅇ
ㅇ
실선, 점선 사용.
1:M, M:M ) 까마귀 발
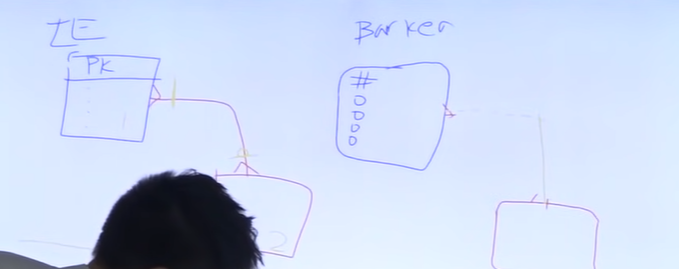
점선: 비식별자
실선: 식별자
식별자
식별자 비식별자 관계 ERD
유일성
최소성
불변성: 만들면 변하지X
존재성: NOT NULL
식별자, 비식별자 관계
식별:강한 관계
비식별: 약한 관계
단점 :
- 식별자
- SQL 구문 복잡
- PK 속성수 증가
- 비식별자
= 조인 느려진다.
ERD
ERD 서술 규칙
- 시선 좌상-> 우하
- 관계명 반드시 표기X
- uml -> 객체 지향에서만 쓰인다
성능 데이터 모델링
- 아키텍쳐
데이터 구조, 테이블, 파티션 구성 등
주방 구조 바꾸기. 성능 good
2.sql 명령문
조인 수행 원리★
optimizer
실행계획 ★
요리 빨리나오게 하기
💥💥💥💥💥💥정규화
1차 원자성 : 속성값 2개인거 삭제
2차 부분함수 종속 제거 ★
3차 이행함수 종속 제거 ★
BCMF
★이상현상
삭제 이상
삽입 이상
3.성능
SELECT▼
INSERT,UPDATE ▲
반정규화
★ 데이터 무결성 해침!
범위
범위 처리
통계처리
응용 시스템 변경
클러스터링/인덱스
뷰

개인적 공부 기록. 그때그때 메모합니다.