SQL
1.sql 설치 후 확인
ASDF
2.SQL 데이터 조회

SQL문은 가독성을 위해 한 줄보단 여러 줄에 걸쳐서 입력한다.문장은 세미콜론 ;을 붙여 종결한다.위 문장은 두 절, 한 문장이다.\+ 더하기\- 빼기\* 곱하기/ 나누기0이 아님빈공간도 아님미확정, 알 수 없는 값어떤 값인지 알 수 없는 어떤 값이 존재? 혹은 in
3.오라클

관계형 데이터베이스 관리 시스템 (RDMBS).오라클은 미국 오라클 사의 데이터베이스 관리 시스템의 소프트웨어 이름이자, 동시에 RDBMS를 지칭하는 말관계형 데이터베이스는 정보 저장하기 위한 구조로 테이블을 이용한다. 테이블은 행ROW과 열COLUMN로 이루어져있다
4.DDL, DML, DCL
데이터 정의어객체의 생성, 변경, 삭제 명령어로, 주로 테이블에 관련된 언어.CREATE ALTER DROP TRUNCATE데이터 조작어주로 질의어. 저장된 데이터를 조작하는데에 쓴다.행과 열, 레코드를 조회하거나 수정/삭제 함.SELECTINSERTUPDATEDELE
5.SELECT
파일 -> 새로 만들기새로 생성 창에서 SQL 파일 선택 -> 확인디렉ㅈ토리 경로를 C:\_work로 선택파일 이름 설정 후 sql 생성쿼리문을 입력한 후 실행 버튼 클릭❗ 참고로 sql은 대문자/소문자를 구분하지 않는다!SELECT \[DISTINCT] FROM {\
6.Join

관계형 데이터베이스는 두 개 이상의 테이블에 정보가 나뉘어져있다.중복 저장을 지양하기 위해서다.그러다보니 기존의 방식은 여러 테이블을 넘나들어야한다.모든 사원의 부서 번호를 알아낸다특정 사람의 부서번호를 알아낸다특정 사람의 부서번호를 알아낸다from절에 재료 집합이 두
7.새로운 sql 파일
❗ 참고로 sql은 대문자/소문자를 구분하지 않는다!파일 -> 새로 만들기새로 생성 창에서 SQL 파일 선택 -> 확인디렉ㅈ토리 경로를 C:\_work로 선택파일 이름 설정 후 sql 생성쿼리문을 입력한 후 실행 버튼 클릭드래그 앤 드롭, 불러오기 후 실행버튼 누르기접
8.ORDER BY
order by desc : 내림차순order by asc : 오름차순숫자: 작은 값부터 정렬 | 큰값부터 정렬문자: 사전 순서로 정렬 | 사전 반대 순서로 정렬날짜: 빠른 날짜 순서로 정렬 | 늦은 날짜 순서로 정렬NULL: 가장 마지막에 | 가장 먼저
9.WHERE
테이블을 구성하는 행의 집합에 대해 테이블의 부분 집합을 결과로 반환하는 연산자UNION (합집합)DIFFERENCE (차집합)INTERSECT (교집합)ALL은 중복된 레코드가 허용된다.UNION ALL (합집합)DIFFERENCE ALL (차집합)INTERSECT
10.ch3
ch3
11.데이터 무결성을 위한 제약 조건
테이블에 부적절한 자료가 입력되는 것을 방지하기 위하여테이블을 생성할 때, 각 컬럼에 대해서 정의하는 여러가지 규칙무결성: 데이터 베이스 내에 데이터의 정확성을 유지하는 것제약조건: 바람직하지 않은 데이터가 저장되는 것을 방지NOT NULL : NULL을 허용하지XUN
12.데이터 모델링의 이해
(=모형화, 가설적)현실세계를 일정한 형식에 맞추어 표현.다양한 현상을 일정한 양식인 표기법에 의해 표현복잡한 현실세계를 제한된 표기법이나 언어로 표현누구나 이해하기 쉽게 하기 위해 대상에 대한 애매모호함을 제거, 정확하게 현상 기술.데이터베이스가 여러 장소에 같은 정
13.SQLD 최종 정리 강의 1편
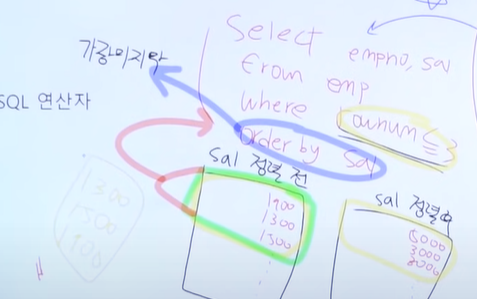
FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BYDML - SELECT, INSERT, DELETE, UPDATEDDL - ALTER, CREATE, MODIFY, DROPTCL - ROLLBACK, COMMITDCL - G
14.SQLD 최종 정리강의 2편 - 윈도우 함수 ~ 인덱스(Index)
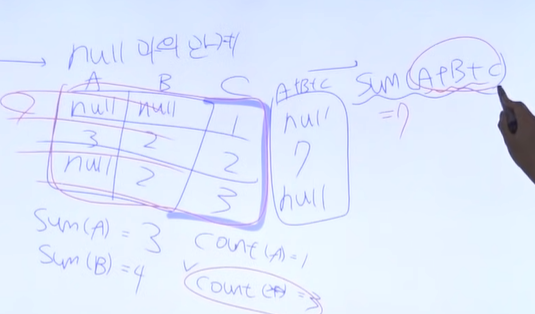
=====>>> 무조건 문제풀기rows -> "차이점"ranncte -> 같은 값rank: 중복 건너 뛰기 (1, 1, 3, 4)dense_rank : 건너뛰기x (1, 1, 2, 3)partition byorder byPrior 자식데이터 = 부모데이터 프자부부모에서
15.ORACLE 주요 함수

한 행으로 결과를 출력하기 위한 테이블DUMMY 테이블에 가깝다!숫자 데이터를 처리하기 위한 함수ABS : 절대값COS : COSINEEXP : e(2.71828183...) 의 n승 FLOOR : 소수점 아래 잘라냄 (버림)LOG : Log 값POWER : POWE
16.1
ROLLUP GROUP BY 은 의 확장된 형태로 사용하기가 쉬우며 병렬로 수행이 가능하기 때문에 매우 효과적일 뿐 아니라 시간 및 지역처럼 계층적 분류를 포함하고 있는 데이터의 집계에 적합하도록 되어 있다.CUBE ROLLUP 는 결합 가능한 모든 값에 대하여 다차원
17.1
ROLLUP GROUP BY 은 의 확장된 형태로 사용하기가 쉬우며 병렬로 수행이 가능하기 때문에 매우 효과적일 뿐 아니라 시간 및 지역처럼 계층적 분류를 포함하고 있는 데이터의 집계에 적합하도록 되어 있다.CUBE ROLLUP 는 결합 가능한 모든 값에 대하여 다차원