0. 들어가며
이전 포스팅에서는 카테고리 데이터에 로컬 캐시를 적용해 상품 조회 성능을 개선했었다.
당시에는 변경은 드물지만 조회는 잦은 데이터를 대상으로,
TTL과 명시적 무효화를 함께 쓰는 전략을 선택했다.
이번에는 조금 다른 케이스였다.
관리자 대시보드에는 일별/주별/월별 포스팅 발행 통계가 노출된다.
이 데이터는 단순히 잘 안 바뀌는 수준이 아니라, 과거 구간은 아예 바뀌지 않는 불변 데이터다.
집계가 완료된 이상 지난달 통계가 달라질 일은 없다.
이 불변성에 주목하면 캐시 전략 자체를 다르게 가져갈 수 있겠다는 생각이 들었고,
TTL 없이 condition만으로 캐시를 설계해보기로 했다.
1. 문제 상황
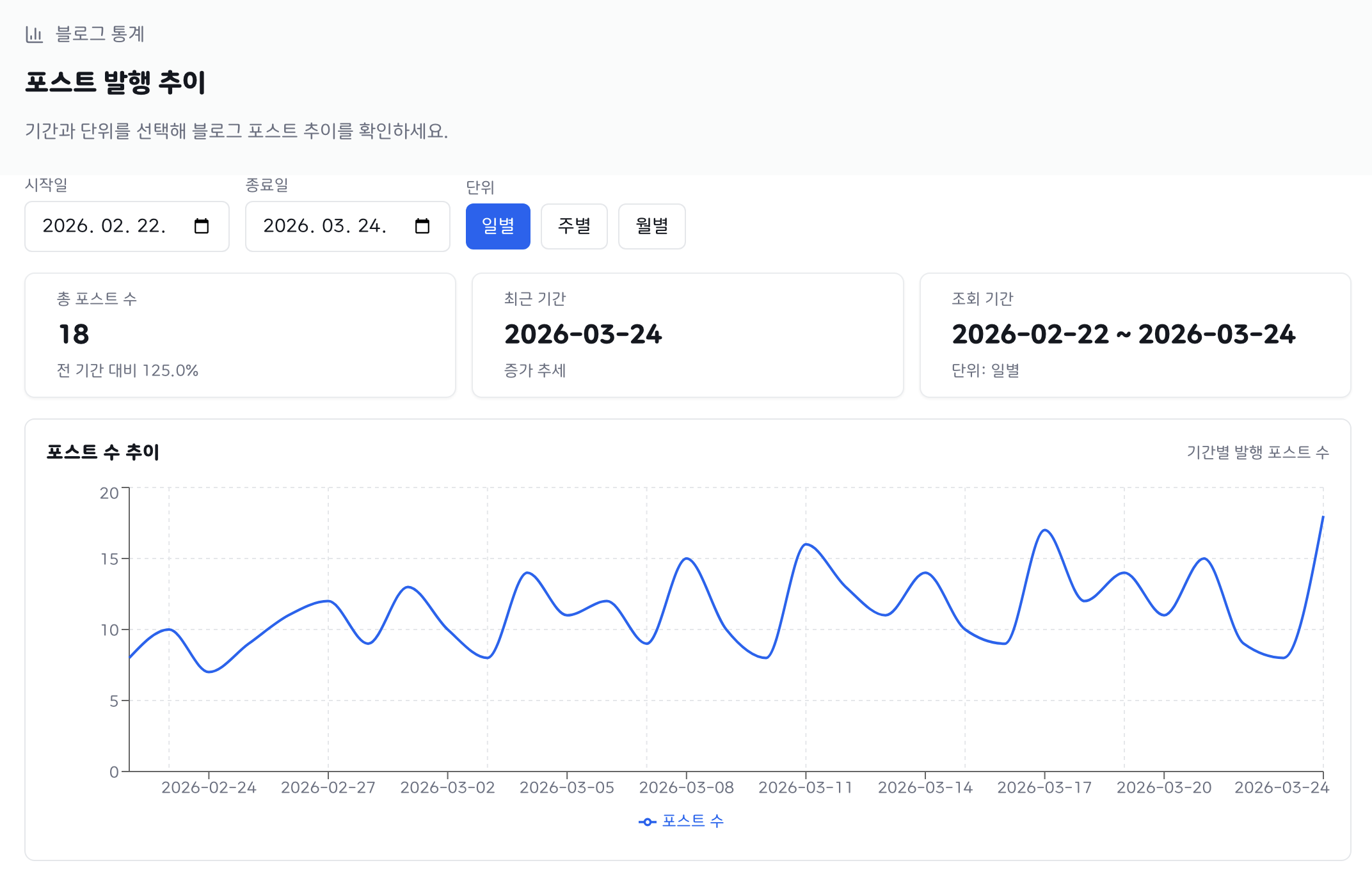
관리자 대시보드에서 주별 포스팅 통계를 조회할 때마다
통계 메서드를 호출하여 매번 DB에 접근하는 구조였다.
문제는 조회 대상이 과거 구간인 경우에도 동일하게 DB를 조회한다는 점이다.
지난주, 지난달처럼 이미 집계가 완료된 과거 통계는 이후에 값이 바뀔 일이 없다.
동일한 파라미터로 반복 조회해도 항상 같은 결과를 반환하는 구간임에도 매 요청마다 불필요한 DB I/O가 발생하고 있었다.
관리자가 대시보드를 반복적으로 확인하는 상황에서는
이러한 불필요한 조회가 누적되어 서비스 부하로 이어질 수 있다.
이 문제를 해결하기 위해 과거 통계처럼 불변성이 보장되는 데이터에 한해 로컬 캐시를 적용하는 방향을 고려하게 되었다.
2. 해결 과정
간단 개념 정리 : https://velog.io/@se0o_129/cache-strategy
2.1 캐시 선택
통계 데이터에는 로컬 캐시를 선택했다.
로컬 캐시를 선택할 때 가장 먼저 고려한 것은 데이터의 특성이었다.
과거 통계는 집계가 완료된 시점부터 값이 고정된다.
즉, 캐시에 저장된 데이터와 DB의 데이터가 달라질 여지가 구조적으로 없다.
글로벌 캐시(Redis 등)는 여러 인스턴스 간 정합성을 맞춰야 할 때 진가를 발휘하지만,
데이터 자체가 불변인 경우에는 정합성 문제가 애초에 발생하지 않는다.
네트워크 비용을 감수하면서까지 외부 캐시 서버를 거칠 이유가 없다고 생각했다.
로컬 캐시는 애플리케이션 내부 메모리에서 바로 응답하기 때문에
이 케이스에 가장 잘 맞는 선택이었다.
2.2 캐시 만료 전략 선택
이번 캐시 설계에서 가장 고민했던 부분은 만료 전략이었다.
일반적으로 캐시 만료는 TTL을 통해 일정 시간이 지나면 자동으로 제거하는 방식을 사용한다. 하지만 이번 경우에는 TTL을 설정하지 않았다.
그 이유는 과거 통계 데이터의 불변성에 있다.
이미 집계가 완료된 과거 구간의 통계는 이후에 값이 바뀌지 않는다.
만료 시점을 두는 것 자체가 의미 없고, 오히려 만료 후 동일한 데이터를 다시 DB에서 불러오는 낭비가 생긴다.
대신 @Cacheable의 condition 옵션을 활용하여
이번 달 이전 데이터만 캐시에 적재되도록 제한하기로 했다.
현재 달의 통계는 아직 집계 중인 실시간 데이터이므로 캐시 대상에서 제외했다.
Caffeine 캐시는 TTL 대신 maximumSize만 설정하여 메모리 상한선만 관리했다.
2.3 캐시 읽기 전략 선택
캐시 읽기 전략으로는 Cache-Aside를 선택했다.
캐시에 데이터가 있으면 그대로 반환하고,
없으면 DB를 조회한 뒤 결과를 캐시에 저장하는 방식으로,
@Cacheable 어노테이션이 이 흐름을 자동으로 처리해준다.
관리자의 대시보드 조회가 반복될수록 캐시 히트율이 높아지고,
과거 데이터는 불변이므로 캐시와 DB 간의 정합성 문제도 발생하지 않는다.
2.4 코드 개선
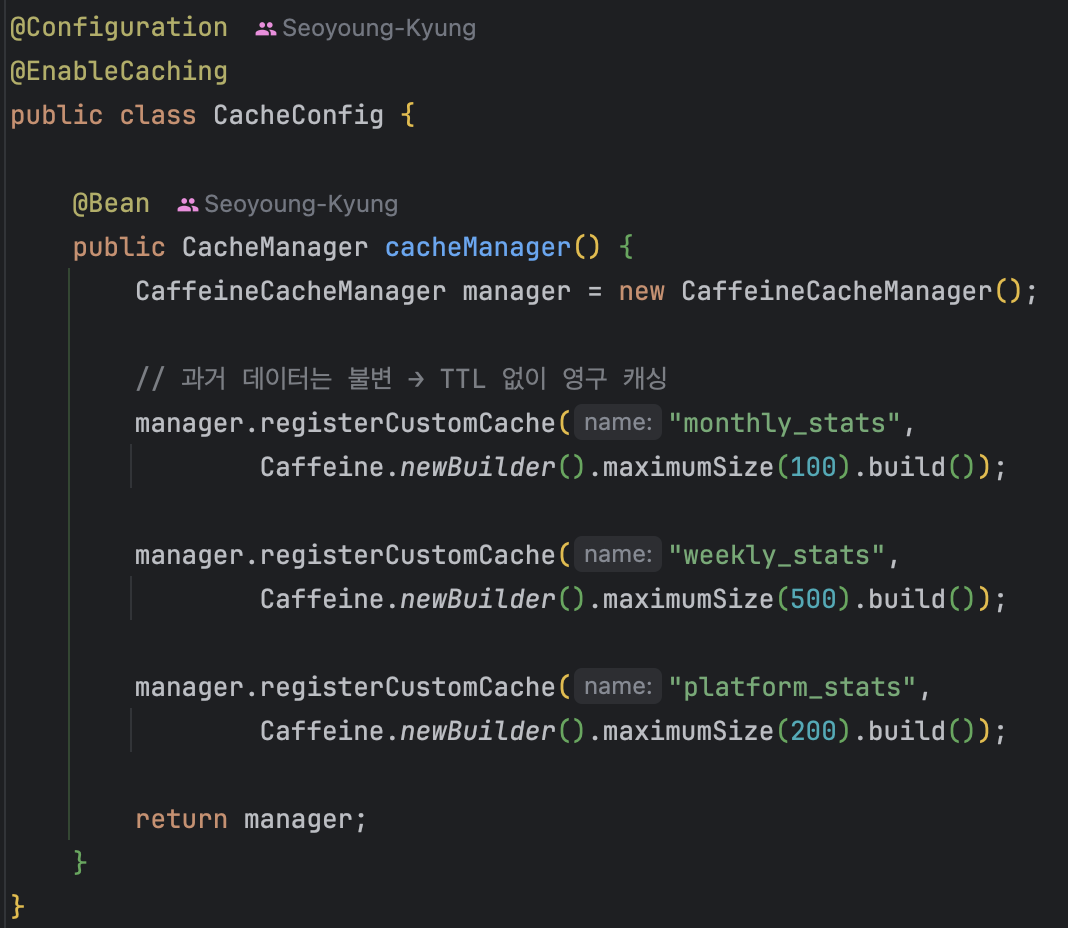
1. CacheManager 설정
TTL 없이 maximumSize만 설정한 Caffeine 기반의 CacheManager를 구성했다.
캐시에 적재되는 데이터는 불변 통계이므로 만료 시점이 불필요하고,
메모리 상한선만 두어 무한 증가를 방지했다.
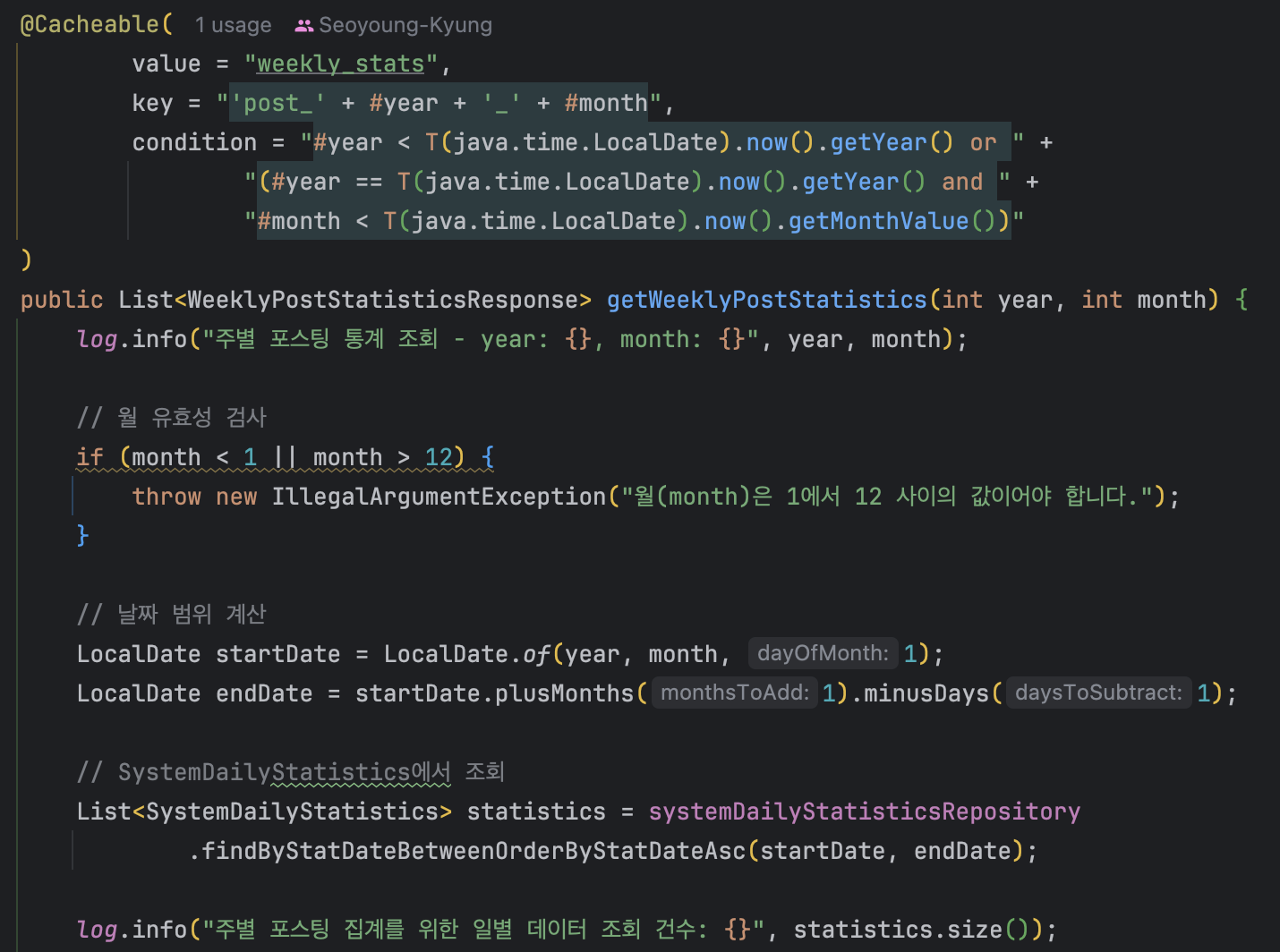
2. @Cacheable + condition 적용
@Cacheable의 condition 옵션을 활용하여 이번 달 이전 데이터만 캐시에 적재되도록 했다.
condition 옵션은 조건이 true일 때만 캐싱을 적용하고, false면 캐시를 사용하지 않는다.
현재 달의 통계는 실시간성이 필요하므로 캐시 대상에서 제외했다.
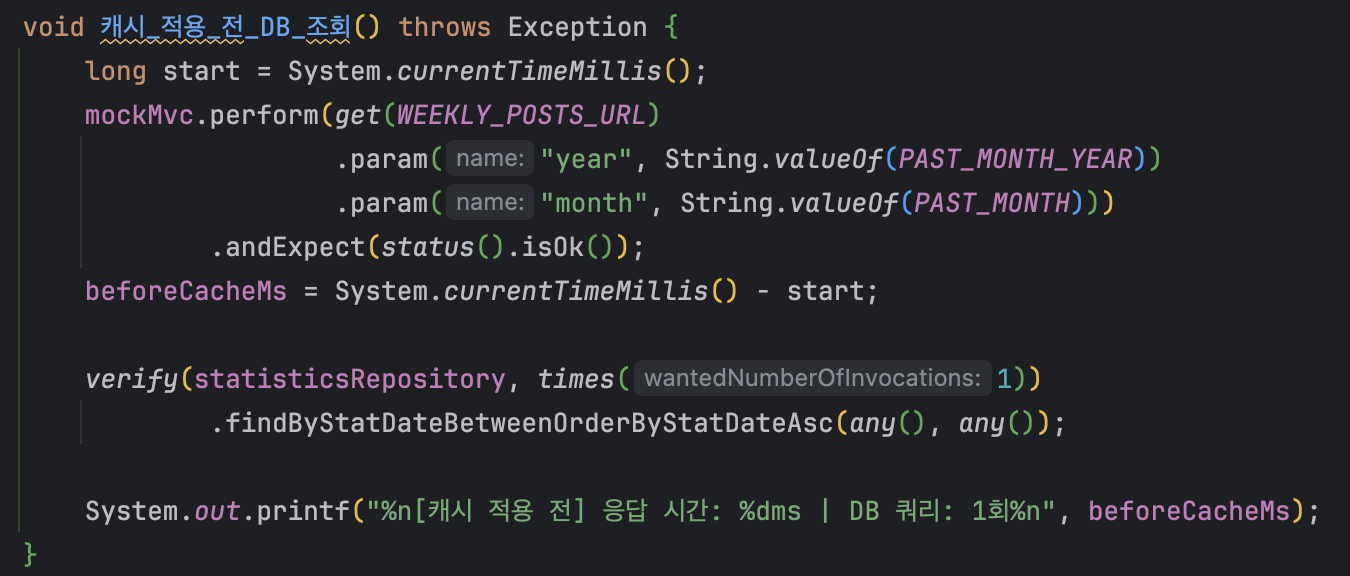
2.5 테스트 코드
캐시 적용 전후를 두 단계로 검증했다. 첫 번째 호출에서 DB 조회가 발생하는 것을 확인하고, 동일한 파라미터로 두 번째 호출 시 캐시 히트로 DB 조회가 생략됨을 @SpyBean으로 repository 호출 횟수를 검증해 확인했다.
3. 결과
캐시 적용 전에는 동일 파라미터 조회 시 263ms(DB 1회) 가 소요되었지만,
캐시 적용 후에는 6ms(DB 0회) 로 줄어드는 것을 확인할 수 있었다.
결과적으로 약 44배의 응답 속도 개선 효과를 확인할 수 있었다.
불변성이 보장된 데이터는 캐시 히트 시 DB 접근 자체가 사라지기 때문에
성능 개선 효과가 뚜렷하게 나타난다.

4. 배운점
두 번의 캐시 적용을 통해 공통적으로 느낀 것은
캐시 전략은 데이터의 특성을 우선적으로 고려해야한다는 점이었다.
이전 카테고리 캐시에서는 잘 안 바뀌는 데이터라
TTL로 안전망을 깔자는 접근이었다면,
이번에는 아예 안 바뀌는 데이터라 만료 자체가 필요 없었다.
데이터를 먼저 이해하고 나면 전략은 자연스럽게 따라온다는 걸 알 수 있었다.
또한 이번 달 데이터처럼 실시간성이 필요한 경우는 캐시 대상에서 명시적으로 제외해야 정합성이 깨지지 않는다는 점도 다시 한번 확인할 수 있었다.
