0. 프로젝트 개요
이 프로젝트는 상품 홍보 블로그 포스팅 자동화 플랫폼이다.
사용자가 상품 홍보를 위해 반복적으로 글을 작성하여 발행하는 과정을 자동화할 수 있다.
예약 시간을 지정하여 워크플로우를 생성하면, 예약한 시간에 맞춰 다음 과정이 자동 실행된다.
- 트렌드 키워드 선정
- 상품 선택
- AI 콘텐츠 생성
- 블로그 업로드
주요 개념
- Workflow(워크플로우): 글 발행 설정 단위 (블로그, 주제, 발행 주기 정의)
- Work(워크): 실제 발행 작업 단위, Workflow가 생성함
관리자는 관리자 페이지에서 Work 실행 상태 조회와 복합 조건 검색이 가능하다.
이번 글에서는 복합 조건 기반 검색 쿼리에 대한 병목(성능 저하)과 이를 해결하는 과정, 결과까지 다뤄보려고 한다.
1. 문제 상황 및 분석
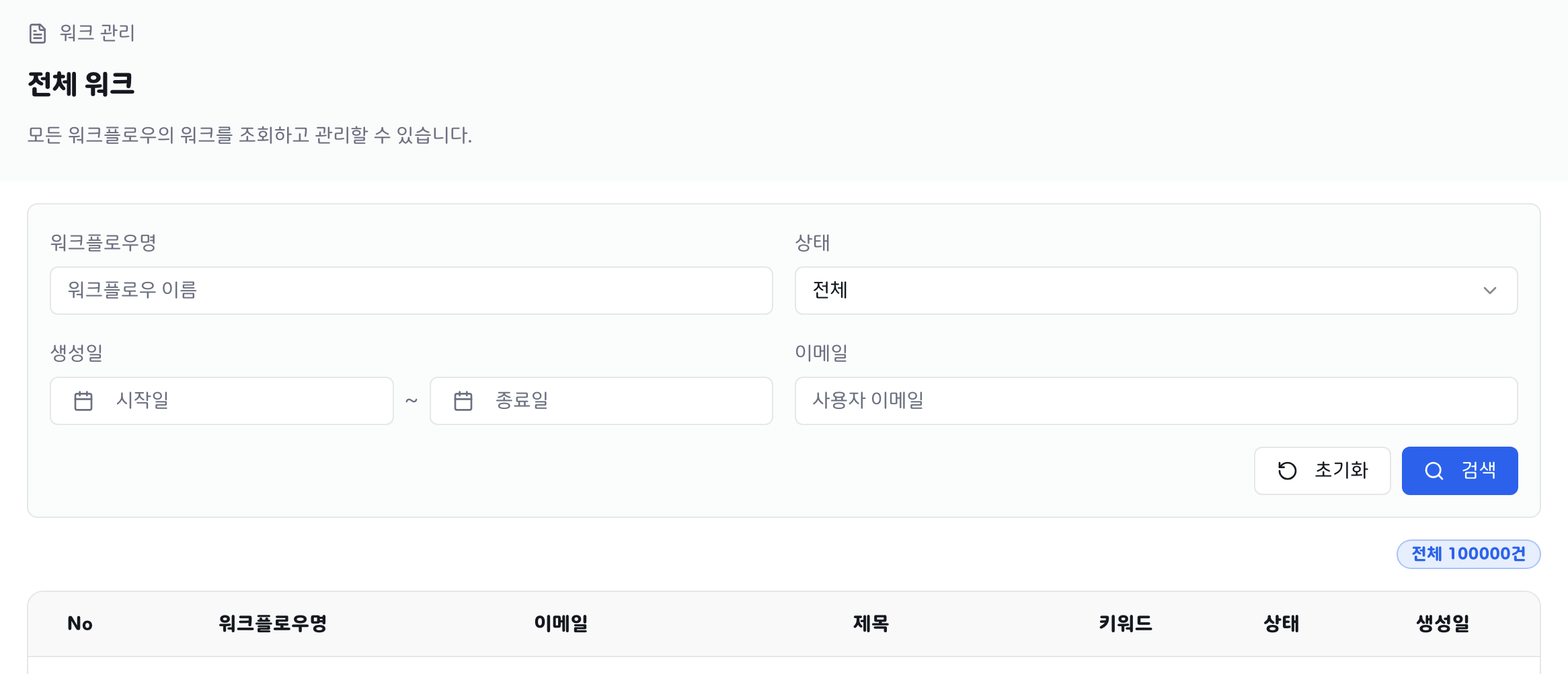
관리자 워크 검색 API에선 워크플로우 이름, 워크 상태, 생성일, 사용자 이메일로 선택적으로 검색할 수 있다.
API 호출 시 다음과 같은 쿼리가 실행된다.
select
w1_0.work_id,
w1_0.workflow_id,
w2_0.name,
w2_0.user_id,
u1_0.email,
ac.title,
w1_0.posting_url,
w1_0.status,
w1_0.created_at
from
work w1_0
join
workflow w2_0
on w2_0.workflow_id=w1_0.workflow_id
join
user u1_0
on u1_0.user_id=w2_0.user_id
left join
ai_content ac1_0
on w1_0.work_id=ac1_0.work_id
where
(
? is null
or w2_0.name like concat('%', ?, '%') escape ''
)
and (
? is null
or w1_0.status=?
)
and (
? is null
or w1_0.created_at>=?
)
and (
? is null
or w1_0.created_at<=?
)
and (
? is null
or u1_0.email like concat('%', ?, '%') escape ''
)
order by
w1_0.created_at desc
limit
?쿼리 구조상 병목 가능성
API 호출 시 위와 같은 쿼리가 나오는데 데이터 규모가 적을 때는 큰 문제가 발생하지 않았다.
하지만 이 쿼리는 여러 조건이 선택적으로 적용되고,
LIKE 검색과 최신순 정렬, 다수의 JOIN이 함께 사용된다.
이러한 구조는 조건 조합이 다양해
하나의 인덱스로 조회 범위를 초기에 좁히기 어렵다.
LIMIT이 있으면 정렬 비용도 자연스럽게 줄어들 것이라 막연히 생각했지만,
ORDER BY 대상 컬럼이 인덱스로 처리되지 않는다면
정렬이 먼저 수행될 수도 있지 않을까 하는 생각이 들었다.
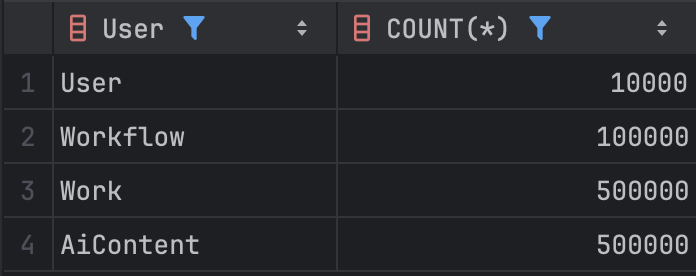
그래서 실제로 어떤 차이가 발생하는지 확인해보기 위해, 실제 서비스 운영 환경을 가정하여 더미데이터를 생성했다.
인덱스 적용 전·후의 성능 차이를 보다 명확하게 확인할 수 있도록 work 테이블은 약 50만 건으로 설정했고,
연관된 테이블들 역시 유사한 비율로 데이터 수를 맞춰 구성했다.
1.1 검색 패턴별 케이스 설정
모든 조건을 조합한 검색은 실제 사용 빈도가 높지 않다고 생각한다.
그래서 관리자 화면에서 실제로 자주 활용될 가능성이 높은 검색 패턴을 기준으로
대표적인 케이스를 세 가지로 나누어 분석해보기로 했다.
세 가지 케이스 모두 기본적으로 최신순 정렬을 기준으로 수행된다.
Case 1. 특정 상태 + 최신순
관리자 페이지의 검색은 일반 사용자 검색과 달리
최근 발생한 작업을 빠르게 파악하고 상태를 추적하는 목적이 크다.
그래서 status 필터와 최신순 정렬을 조합한
특정 상태 + 최신순 조회가 가장 기본적이고 빈번한 케이스라고 판단했다.
Case 2. 특정 상태 + 날짜 범위 + 최신순
이번 케이스는 특정 상태에 대해 기간 조건이 추가된 조회이다.
운영 과정에서는
- 특정 기간 동안 발생한 장애 이력 확인
- 월별/주별 작업 처리 현황 점검
과 같이 기간 단위로 데이터를 확인해야 하는 상황이 자주 발생한다고 생각한다.
그래서 특정 상태 + 날짜 범위 + 최신순 케이스를 통해
기간 조건이 추가되었을 때 실행 계획과 성능이 어떻게 달라지는지 확인하고자 했다.
Case 3. 사용자 이메일 + 최신순
마지막으로는 특정 사용자를 기준으로 한 조회이다.
관리자 페이지에서는
- 사용자 문의 대응
- 특정 사용자 작업 이력 추적
- 이상 동작 여부 확인
과 같은 목적으로
사용자 단위의 조회가 필요해지는 경우가 많다.
이때 사용자 기준으로 검색할 때 가장 직관적인 검색 조건이 사용자 이메일이며,
최근 작업부터 확인하는 흐름이 일반적이기 때문에
사용자 이메일 + 최신순 케이스를 별도로 분리하였다.
위 세 가지 케이스를 토대로 API 호출 속도를 확인해보자.

Case 1. 특정 상태 + 최신순 은 2473ms
Case 2. 특정 상태 + 기간 + 최신순 은 811ms
Case 3. 이메일 + 최신순 은 1227ms
모든 케이스에서 수백 밀리초에서 수 초 단위의 응답 시간이 발생하고 있다.
특히 Case 1의 경우 가장 기본적인 검색 패턴임에도 2.5초에 가까운 응답 시간이 소요되어 우선적인 최적화가 필요하다.
1.2 실행 계획 분석
이제 EXPLAIN 실행 계획 분석을 통해 해당 쿼리의 수치로 확인해보자.
EXPLAIN 명령어는 옵티마이저의 예상 실행 계획을 의미하고,
EXPLAIN ANALYZE 명령어는 실제 실행 결과 기반으로 성능 분석한 것을 보여준다.
Case 1. 특정 상태 + 최신순
WHERE w.status='COMPLETED'
ORDER BY w.created_at DESC
LIMIT 100[ 예상 실행 계획 ]

쿼리 조인 순서와 마찬가지로 실행계획 상에서도
work(w) -> workflow(wf) -> user(u) -> ai_content(ac) 순으로 조인할 것으로 예상된다.
현재 병목인 work 테이블의 주요 문제점을 살펴보자.
-
type = ALL : 전체 테이블 스캔(Full Table Scan)
-
key = NULL : 사용할 인덱스가 없음
-
Extra = Using filesort : ORDER BY 절을 위한 추가 정렬 작업 필요
status, created_at 컬럼에 인덱스가 없어
work 테이블에서 전체 스캔과 정렬이 발생할 것으로 예상된다.
반면 work 이후에 조인되는 workflow, user, ai_content 테이블은
모두 PK·UK 기반의 eq_ref 조인으로, 성능상 병목이 되지 않는다.
-
type = eq_ref
-
key = PRIMARY / UNIQUE
-
rows = 1
결국 이 쿼리의 핵심 문제는 조인 자체가 아니라,
조인에 들어가기 전에 work 테이블에서 데이터를 충분히 줄이지 못한다는 점이다.
[ 실제 실행 결과 기반 성능 분석 ]
-> Limit: 100 row(s) (cost=292472 rows=100) (actual time=471..477 rows=100 loops=1)
-> Nested loop left join (cost=292472 rows=496391) (actual time=471..477 rows=100 loops=1)
-> Nested loop inner join (cost=180815 rows=496391) (actual time=470..472 rows=100 loops=1)
-> Nested loop inner join (cost=115664 rows=496391) (actual time=470..471 rows=100 loops=1)
-> Sort: w.created_at DESC (cost=50513 rows=496391) (actual time=470..470 rows=100 loops=1)
-> Filter: (w.`status` = 'COMPLETED') (cost=50513 rows=496391) (actual time=0.99..241 rows=325000 loops=1)
-> Table scan on w (cost=50513 rows=496391) (actual time=0.912..180 rows=500000 loops=1)
-> Filter: (wf.user_id is not null) (cost=0.25 rows=1) (actual time=0.0164..0.0165 rows=1 loops=100)
-> Single-row index lookup on wf using PRIMARY (workflow_id=w.workflow_id) (cost=0.25 rows=1) (actual time=0.0162..0.0163 rows=1 loops=100)
-> Single-row index lookup on u using PRIMARY (user_id=wf.user_id) (cost=0.25 rows=1) (actual time=0.0123..0.0123 rows=1 loops=100)
-> Single-row index lookup on ac using UKk2kvwlai7l0sa9n5dp448f9oo (work_id=w.work_id) (cost=1 rows=1) (actual time=0.0457..0.0457 rows=1 loops=100)(1) work 테이블에서 실제로 발생한 일
Table scan on w
(cost=50513 rows=496391)
(actual time=0.912..180 rows=500000 loops=1)
Filter: (w.`status` = 'COMPLETED')
(cost=50513 rows=496391) (actual time=0.99..241 rows=325000 loops=1)
Sort: w.created_at DESC (cost=50513 rows=496391)
(actual time=470..470 rows=100 loops=1)예상대로 work 테이블의 약 50만 건 데이터를 전체 스캔하였고,
필터링 이후에도 약 32.5만 건의 대량 데이터에 대해
created_at DESC 기준 정렬(filesort)이 수행되었다.
이 과정에서 실행 시간의 대부분이 소모되었다.
(2) 조인 비용은 실제로도 작았다
Single-row index lookup on wf using PRIMARY (workflow_id=w.workflow_id)
(cost=0.25 rows=1)
(actual time=0.0162..0.0163 rows=1 loops=100)
Single-row index lookup on u using PRIMARY (user_id=wf.user_id)
(cost=0.25 rows=1)
(actual time=0.0123..0.0123 rows=1 loops=100)
Single-row index lookup on ac using UKk2kvwlai7l0sa9n5dp448f9oo (work_id=w.work_id)
(cost=1 rows=1)
(actual time=0.0457..0.0457 rows=1 loops=100)workflow / user / ai_content 모두 PK·UK 기반 단건 조회하여
조인 단계에서 유의미한 비용 증가 없었다.
(3) LIMIT은 생각보다 늦게 적용됐다.
Limit: 100 row(s)
(cost=292472 rows=100)
(actual time=471..477 rows=100 loops=1)LIMIT 100이 존재함에도 불구하고,
전체 스캔과 정렬이 모두 끝난 이후에야 LIMIT이 적용되면서
실행 시간의 대부분이 LIMIT 이전 단계에서 소모되었다.
결과적으로 이 쿼리의 성능 병목은 조인이 아니라,
LIMIT이 적용되기 전에 얼마나 많은 데이터를 처리하느냐에 달려 있음을 확인할 수 있다.
Case 2. 특정 상태 + 날짜 범위 + 최신순
이번 케이스는 특정 상태 + 날짜 범위 + 최신순이다.
특정 기간의 특정 상태를 검색하는 쿼리인 것이다.
WHERE w.status='COMPLETE'
AND w.created_at BETWEEN '2025-01-01' AND '2025-01-31'
ORDER BY w.created_at DESC
LIMIT 100 [ 예상 실행 계획 ]

상태 + 최신순 조건에 기간 조건을 추가했지만,
실행 계획 상에서는 접근 방식(type), 조인 순서, 사용 인덱스에 변화가 없었다.
이는 기간 조건이 인덱스 스캔으로 이어지지 못하고
Full Table Scan 이후 WHERE 절에서 처리되었기 때문이다.
하지만 조건의 선택도가 높아지면서,
옵티마이저가 예상하는 필터링 비율(filtered)은 이전 케이스보다 감소했다.
[ 실제 실행 결과 기반 성능 분석 ]
-> Limit: 100 row(s) (cost=210347 rows=100) (actual time=254..258 rows=100 loops=1)
-> Nested loop left join (cost=210347 rows=496391) (actual time=254..258 rows=100 loops=1)
-> Nested loop inner join (cost=153897 rows=496391) (actual time=254..257 rows=100 loops=1)
-> Nested loop inner join (cost=102535 rows=496391) (actual time=254..257 rows=100 loops=1)
-> Sort: w.created_at DESC (cost=50513 rows=496391) (actual time=254..254 rows=100 loops=1)
-> Filter: ((w.`status` = 'COMPLETED') and (w.created_at >= TIMESTAMP'2025-01-01 00:00:00') and (w.created_at <= TIMESTAMP'2025-01-31 00:00:00')) (cost=50513 rows=496391) (actual time=0.426..241 rows=6045 loops=1)
-> Table scan on w (cost=50513 rows=496391) (actual time=0.383..169 rows=500000 loops=1)
-> Filter: (wf.user_id is not null) (cost=0.346 rows=1) (actual time=0.028..0.0282 rows=1 loops=100)
-> Single-row index lookup on wf using PRIMARY (workflow_id=w.workflow_id) (cost=0.346 rows=1) (actual time=0.0277..0.0278 rows=1 loops=100)
-> Single-row index lookup on u using PRIMARY (user_id=wf.user_id) (cost=0.25 rows=1) (actual time=0.00614..0.00617 rows=1 loops=100)
-> Single-row index lookup on ac using UKk2kvwlai7l0sa9n5dp448f9oo (work_id=w.work_id) (cost=0.988 rows=1) (actual time=0.00904..0.00907 rows=1 loops=100)Filter: ((w.`status` = 'COMPLETED')
and (w.created_at >= TIMESTAMP'2025-01-01 00:00:00')
and (w.created_at <= TIMESTAMP'2025-01-31 00:00:00'))
(cost=50513 rows=496391)
(actual time=0.426..241 rows=6045 loops=1)상태 조건만 적용했던 Case 1에서는
정렬 단계에서 약 32만 건의 row를 처리해야 했지만,
기간 조건을 추가하자 정렬 대상이 약 6천 건으로 줄어들었고,
조회 시간은 258ms로 이전 케이스와 큰 차이를 보였다.
비록 Table Scan 자체는 동일하게 발생했지만,
정렬 단계에서 처리해야 하는 데이터 양의 차이가 성능에 영향을 미칠 수 있다는 것을 알 수 있었다.
Case 3. 사용자 이메일 + 최신순
WHERE userEmail LIKE '%testuser1219%'
ORDER BY w.created_at DESC
LIMIT 100 [ 예상 실행 계획 ]

위 케이스들과 다르게 조인 순서가
user(u) -> workflow(wf) -> work(w) -> ai_content(ac) 순으로
user 테이블이 드라이빙 테이블로 선택되었다.
(드라이빙 테이블은 조인을 시작할 기준 테이블을 의미한다.)
조건절에 있는 이메일 컬럼이 user 테이블에 있기 때문으로 보인다.
user 테이블 기준으로 봤을 때,
-
type = ALL : 전체 테이블 스캔
-
key = NULL : 사용할 인덱스가 없음
-
Extra = Using temporary : 임시 테이블 생성
-
Extra = Using filesort : ORDER
이메일 LIKE 조건으로 필터링하는데,
옵티마이저는 드라이빙 테이블인 user 테이블에
정렬(ORDER BY) 대상 컬럼인 w.created_at 컬럼이 없어
임시테이블을 만들고(Using temporary) 정렬하도록 실행계획을 세웠다.
[ 실제 실행 결과 기반 성능 분석 ]
-> Limit: 100 row(s) (actual time=71.9..71.9 rows=23 loops=1)
-> Sort row IDs: w.created_at DESC, limit input to 100 row(s) per chunk (actual time=71.8..71.8 rows=23 loops=1)
-> Table scan on <temporary> (cost=87935..88604 rows=53257) (actual time=71.6..71.6 rows=23 loops=1)
-> Temporary table (cost=87935..87935 rows=53257) (actual time=71.6..71.6 rows=23 loops=1)
-> Nested loop left join (cost=82610 rows=53257) (actual time=19.5..71.1 rows=23 loops=1)
-> Nested loop inner join (cost=24505 rows=53257) (actual time=15.5..41.3 rows=23 loops=1)
-> Nested loop inner join (cost=5865 rows=10822) (actual time=11.6..23 rows=7 loops=1)
-> Filter: (u.email like <cache>(concat('%','testuser1219','%'))) (cost=1023 rows=1109) (actual time=3.36..14.7 rows=1 loops=1)
-> Table scan on u (cost=1023 rows=9984) (actual time=1.88..6.77 rows=10000 loops=1)
-> Index lookup on wf using FKav9n48jp20yik7vh3wgxcac3p (user_id=u.user_id) (cost=3.39 rows=9.76) (actual time=8.21..8.26 rows=7 loops=1)
-> Index lookup on w using FKbhtldpqf1j34o02ycd4154e6t (workflow_id=wf.workflow_id) (cost=1.23 rows=4.92) (actual time=2.27..2.62 rows=3.29 loops=7)
-> Single-row index lookup on ac using UKk2kvwlai7l0sa9n5dp448f9oo (work_id=w.work_id) (cost=0.991 rows=1) (actual time=1.29..1.29 rows=1 loops=23)(1) user 테이블 : 필터링 -> 조인
Table scan on u
(cost=1023 rows=9984)
(actual time=1.88..6.77 rows=10000 loops=1)
Filter: (u.email like <cache>(concat('%','testuser1219','%')))
(cost=1023 rows=1109)
(actual time=3.36..14.7 rows=1 loops=1)email LIKE '%testuser1219%' 조건으로 인해
이번 실행계획에서는 user 테이블이 드라이빙 테이블로 선택되었다.
하지만 선행 와일드카드가 포함된 LIKE 조건으로 인해
user 테이블에서 인덱스를 활용하지 못하고 전체 테이블 스캔이 발생했다.
(2) 임시테이블 생성
Temporary table
(cost=87935..87935 rows=53257)
(actual time=71.6..71.6 rows=23 loops=1)
Table scan on <temporary>
(cost=87935..88604 rows=53257)
(actual time=71.6..71.6 rows=23 loops=1)
Sort row IDs: w.created_at DESC, limit input to 100 row(s) per chunk
(actual time=71.8..71.8 rows=23 loops=1)드라이빙 테이블인 user에
정렬 컬럼 w.created_at이 없어,
조인 이후 임시 테이블을 생성한 뒤 정렬(filesort)을 수행되었다.
(3) LIMIT 적용
Limit: 100 row(s)
(actual time=71.9..71.9 rows=23 loops=1)LIMIT은 모든 필터링과 정렬 이후에 적용되었다.
이 케이스를 수행하기 위해 총 71.9ms가 소요되었다.
결과적으로 Case1과 마찬가지로 LIMIT 100이 존재함에도 불구하고,
필터링과 정렬이 모두 완료된 이후에야 LIMIT이 적용되어
정렬 비용이 쿼리 성능을 차지하게 되었다.
2. 해결 방안
2.1 인덱스 설계 전략
각 케이스의 실행 계획을 바탕으로, 아래 세 가지 내용을 고려하여 설계하기로 했다.
- WHERE 조건 컬럼의 인덱스를 생성하여 Full Scan 제거
- ORDER BY 컬럼의 인덱스에 생성하여 filesort 제거
- 다중 컬럼 인덱스의 순서는 컬럼의 카디널리티와 쿼리 패턴을 고려
work 테이블은 블로그 포스팅 작업 단위로 데이터가 계속 누적되며,
작업 생성, 상태 변경, 완료 처리 과정에서
INSERT와 UPDATE가 매우 빈번하게 발생하는 테이블이다.
이러한 특성에도 불구하고
모든 조건에 만족하는 인덱스를 생성하게 된다면,
인덱스 수가 증가하면서 성능 저하로 이어질 수 있다.
따라서 이번 인덱스 적용에서는
모든 경우를 최적화하기보다,
실제 사용 빈도가 가장 높은 조회 시나리오를 기준으로
성능 개선 효과가 큰 인덱스를 우선 적용하는 방향으로 설계하기로 했다.
2.2 인덱스 적용
Case 1. 특정 상태 + 최신순
1번 케이스의 문제점은 아래와 같다.
status조건이 있지만 50만 건에 대한 Full Scan- ORDER BY 컬럼의 인덱스 부재로 인한 filesort
이를 토대로 아래와 같은 복합 인덱스를 적용하려고 한다.
CREATE INDEX idx_work_status_created
ON WORK(status, created_at DESC)왜 status를 선두 컬럼으로 선택했는가?
일반적으로 카디널리티가 높은 컬럼을 둬야 인덱스 효과를 볼 수 있는데,
둘 중 비교했을 때 카디널리티가 더 높은 created_at이 아닌
카디널리티가 낮은 status를 인덱스의 선두 컬럼으로 둔 이유는
status가 모든 검색에 필수 조건은 아니지만
관리자 검색에서 빈번하게 사용되는 검색 조건이기 때문이다.
created_at을 선두로 둘 경우
- 최신 데이터부터 인덱스를 탐색한다.
- 각 row마다
status를 검사한다. - 이때 원하는
status값이 아닐 경우 계속 스킵하게 된다. - LIMIT 100을 채우기 위해 많은 row를 탐색하게 될 수 있다.
status를 선두로 둘 경우
- 원하는
status에 해당하는 row들로 범위를 좁힌다. created_at기준으로 정렬이 되어있다.- 거기서 100개만 읽고 종료하면 된다.
그래서 카디널리티보다 쿼리 패턴과 LIMIT의 특성을 우선으로 하여
status는 선두 컬럼, created_at은 후행 컬럼으로 선택했다.
Case 2. 특정 상태 + 날짜 범위 + 최신순
2번 케이스의 문제점은 아래와 같다.
status+created_at두 가지 조건으로 검색 범위는 줄었지만 인덱스 미사용- 50만 건 모두 Full scan 후 6천 건 filesort
하지만 이 경우는 Case 1에서 설계한 idx_work_status_created 인덱스로 커버가 가능하다.
status + created_at 이번 케이스와 같은 조건으로 설계된 인덱스이기 때문에
별도의 인덱스 생성 없이 해결할 수 있다.
Case 3. 사용자 이메일 + 최신순
3번 케이스의 문제점은 아래와 같다.
- 선행 와일드카드가 존재하는 LIKE 조건절로 인덱스 활용 불가능
- user 테이블의 Full Scan이 불가피하게 발생
- 임시 테이블 생성 및 정렬 작업 발생
이번 케이스의 한계는 LIKE 조건절이 인덱스 활용이 불가능하여 인덱스 생성이 불가능하다.
3. 결과
이제 인덱스 적용 후 예상 실행 계획과 실제 실행 결과를 비교해보자.
Case 1. 특정 상태 + 최신순
[ 예상 실행 계획 ]

type : ALL -> ref
key : NULL -> idx_work_status_created
Extra : Using filesort -> NULL
실행 계획을 보면,
기존의 Full Table Scan 대신 인덱스를 이용한 동등 조건 탐색으로 변경되었고,
정렬 또한 인덱스 순서를 활용하면서 filesort가 제거되었다.
[ 실제 실행 결과 기반 성능 분석 ]
-> Limit: 100 row(s) (cost=473200 rows=100) (actual time=0.48..1.81 rows=100 loops=1)
-> Nested loop left join (cost=473200 rows=248195) (actual time=0.478..1.8 rows=100 loops=1)
-> Nested loop inner join (cost=201176 rows=248195) (actual time=0.452..1.27 rows=100 loops=1)
-> Nested loop inner join (cost=114308 rows=248195) (actual time=0.44..0.955 rows=100 loops=1)
-> Index lookup on w using idx_work_status_created (status=''COMPLETED'') (cost=27440 rows=248195) (actual time=0.415..0.455 rows=100 loops=1)
-> Filter: (wf.user_id is not null) (cost=0.25 rows=1) (actual time=0.00458..0.00471 rows=1 loops=100)
-> Single-row index lookup on wf using PRIMARY (workflow_id=w.workflow_id) (cost=0.25 rows=1) (actual time=0.00435..0.00439 rows=1 loops=100)
-> Single-row index lookup on u using PRIMARY (user_id=wf.user_id) (cost=0.25 rows=1) (actual time=0.00289..0.00293 rows=1 loops=100)
-> Single-row index lookup on ac using UKk2kvwlai7l0sa9n5dp448f9oo (work_id=w.work_id) (cost=0.996 rows=1) (actual time=0.00494..0.00498 rows=1 loops=100)
Index lookup on w using idx_work_status_created (status='COMPLETED')
(cost=27440 rows=248195)
(actual time=0.331..0.363 rows=100 loops=1)새로 인덱스를 추가한 인덱스도 정상적으로 사용하며
LIMIT 100에 도달하자 추가 탐색 없이 바로 종료되는 것을 확인할 수 있었다.

결과적으로
쿼리 실행 속도는 447ms -> 1.81ms,
API 호출 속도는 2473ms -> 270ms 로 개선되었다.
Full Table Scan과 filesort가 제거되면서
처리해야 할 레코드 수와 정렬 비용이 줄어든 것으로 보인다.
Case 2. 특정 상태 + 날짜 범위 + 최신순
[ 예상 실행 계획 ]

type : ALL -> range
key : NULL -> idx_work_status_created
Extra : Using filesort -> NULL
두 번째 케이스는 Full Table Scan에서 범위 탐색으로 변경되었고,
동일하게 정렬 또한 인덱스 순서를 활용하면서 filesort가 제거되었다.
[ 실제 실행 결과 ]
-> Limit: 100 row(s) (cost=13539 rows=100) (actual time=0.276..1.62 rows=100 loops=1)
-> Nested loop left join (cost=13539 rows=6045) (actual time=0.275..1.61 rows=100 loops=1)
-> Nested loop inner join (cost=6952 rows=6045) (actual time=0.264..1.09 rows=100 loops=1)
-> Nested loop inner join (cost=4836 rows=6045) (actual time=0.243..0.757 rows=100 loops=1)
-> Index range scan on w using idx_work_status_created over (status = 'COMPLETED' AND '2025-01-31 00:00:00.000000' <= created_at <= '2025-01-01 00:00:00.000000'), with index condition: ((w.`status` = 'COMPLETED') and (w.created_at >= TIMESTAMP'2025-01-01 00:00:00') and (w.created_at <= TIMESTAMP'2025-01-31 00:00:00')) (cost=2721 rows=6045) (actual time=0.228..0.319 rows=100 loops=1)
-> Filter: (wf.user_id is not null) (cost=0.25 rows=1) (actual time=0.00385..0.00402 rows=1 loops=100)
-> Single-row index lookup on wf using PRIMARY (workflow_id=w.workflow_id) (cost=0.25 rows=1) (actual time=0.00356..0.00362 rows=1 loops=100)
-> Single-row index lookup on u using PRIMARY (user_id=wf.user_id) (cost=0.25 rows=1) (actual time=0.00292..0.00298 rows=1 loops=100)
-> Single-row index lookup on ac using UKk2kvwlai7l0sa9n5dp448f9oo (work_id=w.work_id) (cost=0.99 rows=1) (actual time=0.00465..0.00471 rows=1 loops=100)-> Index range scan on w using idx_work_status_created over
(status = 'COMPLETED' AND '2025-01-31 00:00:00.000000' <= created_at <= '2025-01-01 00:00:00.000000'),
with index condition: ((w.`status` = 'COMPLETED') and (w.created_at >= TIMESTAMP'2025-01-01 00:00:00') and (w.created_at <= TIMESTAMP'2025-01-31 00:00:00'))
(cost=2721 rows=6045)
(actual time=0.228..0.319 rows=100 loops=1)Case 1에서 생성했던 idx_work_status_created 인덱스를 잘 사용하는 걸 확인할 수 있었다.
created_at 범위가 역순으로 보이는 이유
그런데 created_at 범위가 역순(끝 <= created_at <= 시작)으로 표시되어
잘못 조회하는 것은 아닌지 의문이 들 수 있다. 내가 그랬다 ..
하지만 이건 인덱스가 (status, created_at DESC)로 정의되어 있어
MySQL은 인덱스를 역방향으로 스캔한다.
EXPLAIN에서 끝 <= created_at <= 시작 형태로 표시되는 것은
역방향 스캔의 시작점과 끝점을 보여주는 것일 뿐,
실제 WHERE 조건(2025-01-01 ~ 2025-01-31)은 정상적으로 적용된다.

결과적으로
쿼리 실행 속도는 258ms -> 1.62ms,
API 호출 속도는 811ms -> 116ms 로 개선되었다.
Case 3. 사용자 이메일 + 최신순
세 번째 케이스는 인덱스를 통한 성능 개선은 어렵다고 생각되어
이번 포스팅의 개선 대상에서 제외하였다.
이미 실행 계획 분석 단계에서 확인했듯이,
이 병목은 인덱스 설계로 해결할 수 있는 문제가 아니라
쿼리 구조 자체의 제약으로 인한 문제라고 생각된다.
따라서 인덱스 추가보다는 검색 방식 변경이나 조회 구조 분리 등
다른 방향의 개선이 필요할 것으로 보인다.
본 포스팅에서는 인덱스 적용을 통한 성능 개선에 초점을 두고 있기 때문에,
이 케이스의 추가적인 개선 방안은 추후 검토해볼 예정이다.
개선 전 후 비교표
| 케이스 | 조회 조건 | 인덱스 적용 전 후 | 쿼리 실행 시간 |
|---|---|---|---|
| Case 1 | 상태 + 최신순 | 적용 전 → 적용 후 | 447ms → 1.81ms |
| Case 2 | 상태 + 기간 + 최신순 | 적용 전 → 적용 후 | 258ms → 1.62ms |
| Case 3 | 사용자 이메일 + 최신순 | 적용 안 함 | 71.9ms |
4. 배운점
인덱스 설계는 이론만으로 결정되지는 않는다는 걸 느꼈다.
원래는 "인덱스 설계는 정해진 원칙대로만 하면 되는 것 아닐까" 라는 생각을 가지고 있었다.
하지만 이번 포스팅을 작성하면서 직접 쿼리를 분석하고 정리해보니,
쿼리 패턴이나 실제 사용 용도에 따라 이론이 항상 그대로 적용되지는 않는다는 걸 느끼게 되었다.
중요한 것은 인덱스 원칙 자체보다,
이 쿼리가 어떤 상황에서, 어떤 데이터를 가장 많이 조회하는지를 먼저 이해하고
그에 맞게 인덱스를 설계하는 것이라는 생각이 들었다.
LIMIT은 만능이 아니며, 인덱스와 함께 사용할 때 의미가 있다.
LIMIT으로 조회 건수를 줄이면 성능도 자연스럽게 좋아질 것이라고 막연하게 생각했던 적이 있다.
하지만 대량의 데이터를 만들어 직접 실행해보니,
LIMIT 자체보다 LIMIT이 언제 적용되느냐가 훨씬 중요하다는 걸 체감할 수 있었다.
정렬과 필터링이 끝난 이후에 LIMIT이 적용되는 구조라면,
LIMIT이 있어도 이미 대부분의 비용이 발생한 뒤였다.
결국 LIMIT은 인덱스와 함께 사용될 때에만
실제로 성능 개선 효과를 낼 수 있다는 점을 알게 되었다.
모든 성능 문제를 인덱스로 해결할 수 있는 것은 아니었다.
처음에는 세 번째 케이스 역시 인덱스를 통해
개선할 수 있을 것이라 생각하고 분석 대상으로 포함했다.
하지만 실행 계획을 살펴보고 실제로 인덱스 적용을 검토하는 과정에서,
이 경우에는 인덱스로 해결하기 어려운 구조라는 점을 확인할 수 있었다.
이번 분석을 통해 성능 이슈라고 해서 항상 인덱스 추가가 정답은 아니며,
문제의 원인이 어디에 있는지를 먼저 파악하는 것이 더 중요하다는 점을 느꼈다.
