0. 들어가며
문제 발견
지금까지 개발하면서 조회용 메서드에는 습관적으로
@Transactional(readOnly = true)를 붙였다.
조회에 @Transactional(readOnly = true) 를 설정함으로써
성능상 이점을 얻을 수 있다고 알고있지만,
정작 내부에서 어떻게 동작하는지는 제대로 이해하지 못했다.
- 왜 성능이 좋아지는 걸까?
- 내부적으로 무슨 일이 일어나는 걸까?
- 실제로 얼마나 차이가 날까?
궁금증을 해결하기 위해 직접 테스트하고 내부 동작을 분석해보았다.
테스트 환경
- Spring Boot 3.x, JPA/Hibernate
- MySQL 8.0
한계
- 실제 운영 환경의 대량 데이터(수만~수십만 건)에서는 차이가 더 클 수 있다.
1. 문제 분석
1.1 현재 코드
@Transactional
public ProductDetailResponse findByProductId(Long productId) {
Product product = productRepo.findProductById(productId);
long favCount = favoriteRepo.countByProductId(productId);
List<ProductOption> options = productOptRepo.findOptionByProductId(productId);
return productConverter.toDetailDto(product, favCount, options);
}이 메서드는 상품 상세 조회 API의 서비스 코드로, 기본값 트랜잭션을 사용한다.
Spring의 @Transactional 기본 설정은 readOnly = false
즉, “쓰기 가능 트랜잭션” 으로 인식된다.
비록 SQL은 SELECT만 실행되지만
JPA/Hibernate는 ‘언제든 엔티티가 변경될 수 있다’고 가정한다.
1.2 무엇이 문제일까 ?
JPA는 기본적으로 다음을 전제로 동작한다.
"트랜잭션 안에서 조회한 엔티티는
변경될 수도 있으니, 끝날 때 반드시 확인해야 한다."
그래서 읽기 전용이라고 명시하지 않으면,
JPA는 단순 조회도 쓰기 가능 상태로 관리한다.
문제 1 : 영속성 컨텍스트 + 스냅샷 생성
조회 메서드를 호출했을 때 아래와 같은 과정은 거친다.
- Product 엔티티 조회
- 영속성 컨텍스트에 엔티티 저장
- 동시에 스냅샷(초기 상태 복사본) 생성
[ 영속성 컨텍스트 ]
- Product 엔티티
- Product 스냅샷 (변경 감지용)
스냅샷은 변경 감지를 위해서만 존재하는데
조회만 하는데도 엔티티 개수만큼 메모리를 사용하게 되고, 대량 조회시 메모리 압박이 증가하게 된다.
읽기 전용 트랜잭션에서는 전혀 필요없는 작업이다.
문제 2 : 더티 체킹(변경 감지) 수행
트랜잭션 종료시 Hibernate는
- 현재 엔티티 상태
- 스냅샷 상태
위 두 가지의 모든 필드를 비교한다.
for (엔티티의 모든 필드) {
현재값 == 스냅샷값 ?
}실제로는 변경한 적 없는 조회 전용 메서드에서
의미 없는 객체 필드 비교와 엔티티 수 * 필드 수 만큰 CPU를 사용하게 되어 낭비가 발생한다
문제 3 : 불필요한 flush 가능성
flush란 영속성 컨텍스트 내용을 DB와 동기화하는 작업을 말한다.
보통 트랜잭션 커밋 시 JPQL 실행 전 자동 발생 가능하다.
@Transactional
public List<Product> findByProductId(...) {
// 다른 로직이 추가되면?
}의도치 않게 엔티티 상태가 변경되면 flush 발생 → UPDATE 쿼리 실행할 수 있는 상태가 되고
조회 메서드인데 DB 변경되는 사고가 날 수 있다.
2. 해결 방법: readOnly = true
2.1 개선 코드
@Transactional(readOnly = true)
public ProductDetailResponse findByProductIdReadOnly(Long productId) {
Product product = productRepo.findProductById(productId);
long favCount = favoriteRepo.countByProductId(productId);
List<ProductOption> options = productOptRepo.findOptionByProductId(productId);
return productConverter.toDetailDto(product, favCount, options);
}2.2 readOnly = true가 하는 일
(1) 스냅샷 저장 안 함
일반 트랜잭션에서는 조회한 엔티티의 원본 상태(스냅샷)을 영속성 컨텍스트에 저장하지만
readOnly = true에서는 스냅샷을 생성하지 않는다 (메모리 사용량 감소)
(2) 변경 감지(더티 체킹) 안 함
일반 트랜잭션 종료 시 현재 상태 vs 스냅샷 비교하여 변경 여부 판단하지만
readOnly = true에서는 비교 대상 자체가 없다. (CPU 사용 감소)
(3) 플러시 모드 변경
readOnly = true 적용 시 Hibernate FlushMode가 MANUAL 로 변경하여
트랜잭션 종료 시 자동 flush 발생하지 않는다.
(4) 데이터베이스 힌트 (DB에 따라)
@Transactional(readOnly = true)가 선언되면
Spring은 JDBC Connection에 읽기 전용(read-only) 힌트를 전달한다.
이 힌트는
“이 트랜잭션은 데이터를 변경하지 않는다”
는 의미를 DB 및 인프라 계층에 명시적으로 알리는 역할을 한다.
레플리케이션 환경에서의 동작
DB가 다음과 같은 레플리케이션 구조로 구성된 경우:
Master DB → Replica DB (복제본)
(쓰기) (읽기)- Master DB : INSERT / UPDATE / DELETE 담당
- Replica DB : SELECT 전용 조회 담당
읽기 전용 힌트가 전달되면,
DataSource 라우팅 설정이나 미들웨어(MySQL Router, Aurora Reader Endpoint 등)에 따라
해당 트랜잭션을 Read Replica로 라우팅할 수 있다.
단, readOnly = true만으로 자동 라우팅이 되는 것은 아니며
실제 라우팅은 인프라 및 애플리케이션 설정에 따라 결정된다.
결과적으로
조회 트래픽이 Replica로 분산됨으로써,
Master DB 부하 감소하고 읽기 요청이 많은 서비스에서 전체 처리량 및 안정성 향상된다.
3. 성능 테스트
3.1 테스트 시나리오
Product 10건을 기준으로 연관된 엔티티인
Hashtag 55건, NutritionInfo 10건, ProductOption 179건이 함께 조회되어
총 254개의 데이터가 로딩되는 상황을 가정하였다.
동일한 조회 조건에서
@Transactional(readOnly = false) 와
@Transactional(readOnly = true) 를 각각 10회 측정하여
평균 수행 시간을 비교하였다.
테스트 코드와 레파지토리 메서드는 아래와 같다.
테스트 코드는 @Transactional의 readOnly true와 false를 적용한 메서드 사용외에 모두 동일하다.
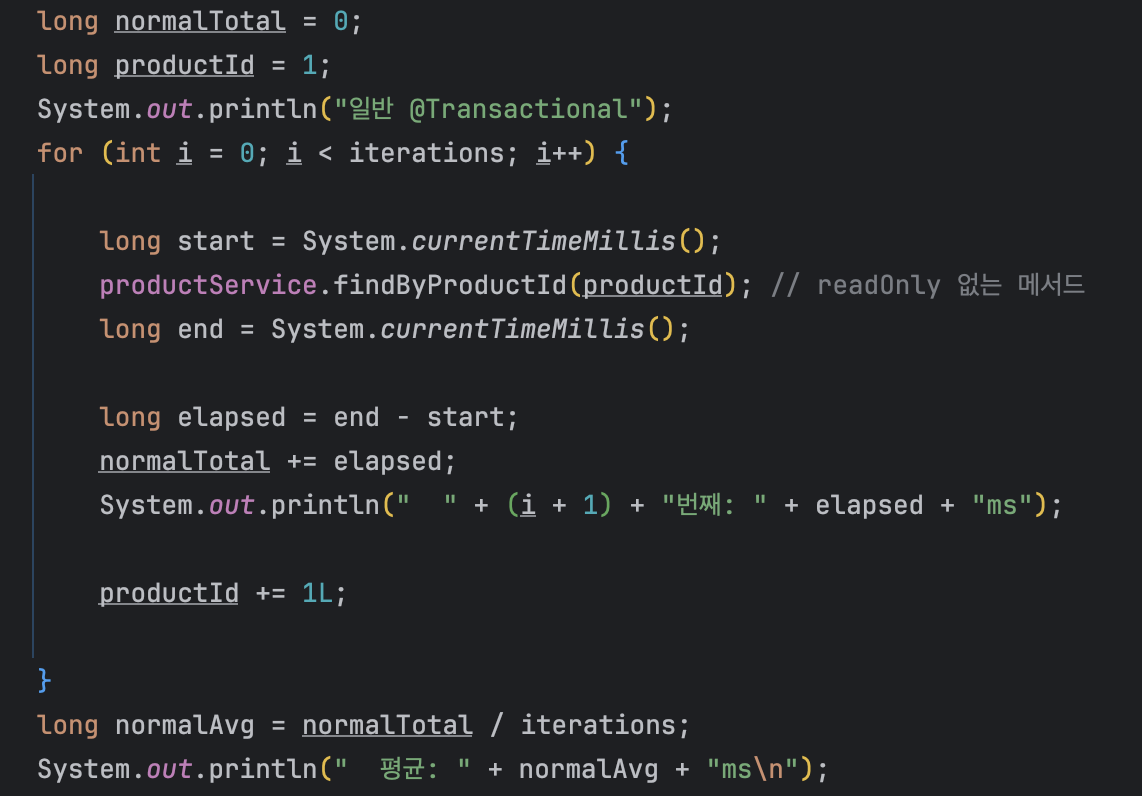
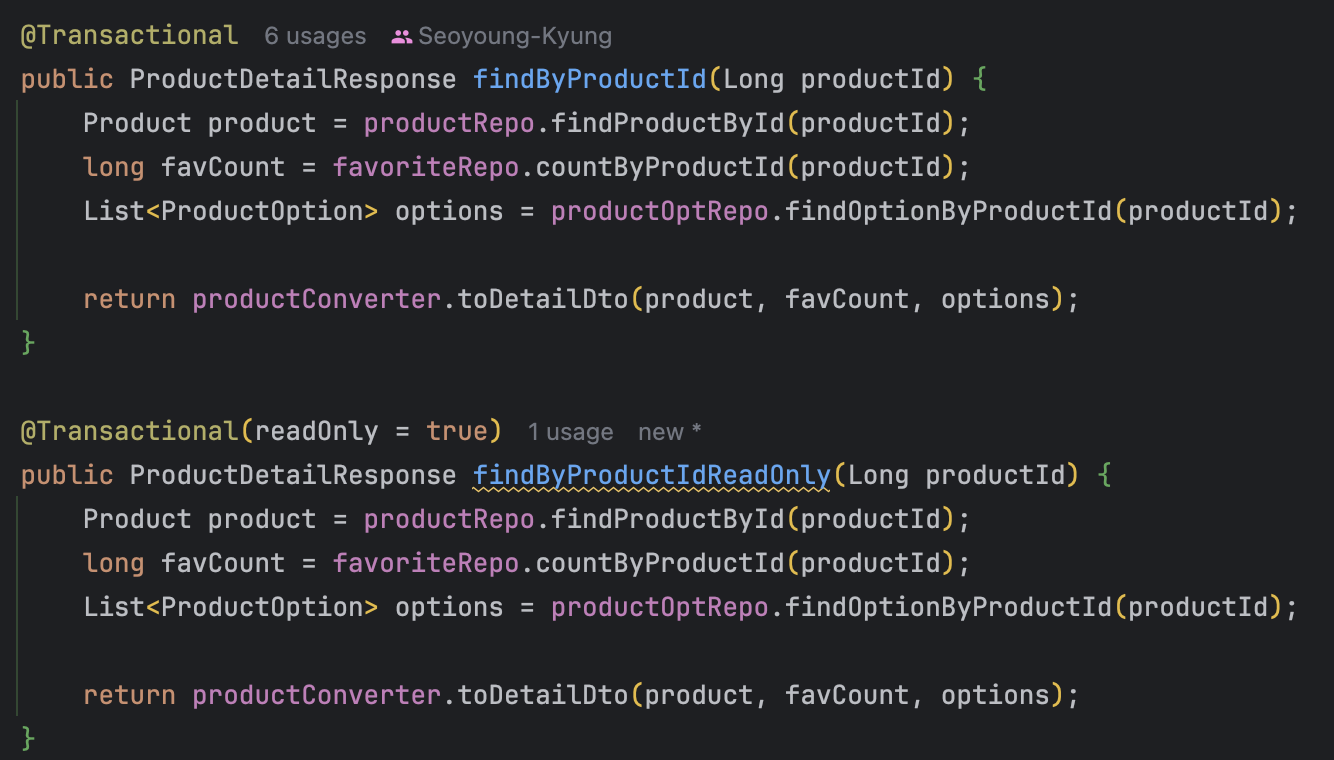

3.2 측정 결과
| 방식 | 평균 시간 | 개선율 |
|---|---|---|
| @Transactional | 35ms | 기준 |
| @Transactional(readOnly=true) | 18ms | 48.6% ↑ |
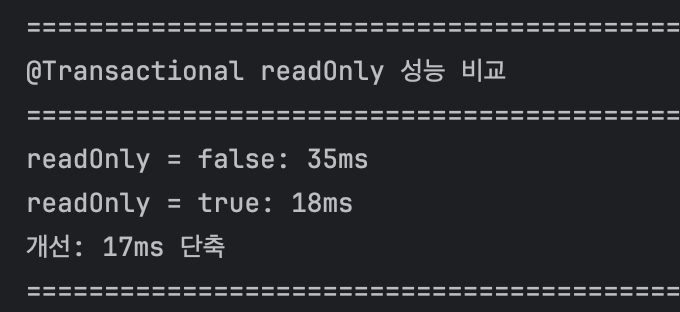
소량 데이터 조회라 큰 변화는 없었지만
readOnly=true를 적용했을 때 시간이 단축된 걸 확인해볼 수 있었다.
이는 조회에는 불필요한 스냅샷 저장과 더티 채킹 과정을 생략함으로써 나올 수 있는 결과이다.
4. 주의사항
4.1 읽기 전용 트랜잭션에서 수정하면 무슨 일이 생길까 ?
@Transactional(readOnly = true)
public void updateProduct(Long productId) {
Product product = productRepository.findById(productId);
product.setName("변경"); // 변경 감지 안 됨
// DB에 반영되지 않음
}겉보기에는 문제 없는 코드처럼 보이지만
readOnly = true 트랜잭션에서는
엔티티 스냅샷을 만들지 않고, Dirty Checking(변경 감지)을 하지 않기 때문에
엔티티 값은 바뀐 것처럼 보이지만 트랜잭션 종료 시 UPDATE SQL이 실행되지 않는다.
그렇기 때문에 readOnly 트랜잭션에서는 절대로 엔티티 상태를 변경하면 안 된다.
4.2 언제 사용해야 할까 ?
사용해야 할 때 :
- 단순 조회 API
- 리포트 생성
- 통계 조회
- 검색 기능
사용하면 안 될 때 :
- 데이터 수정이 필요한 경우
- CUD(Create, Update, Delete) 작업
5. 적용 팁
5.1 Service 계층 패턴
@Service
@Transactional(readOnly = true) // 클래스 레벨 기본값
public class ProductService {
// 조회 - readOnly 상속
public List<Product> findAll() { ... }
// 수정 - 메서드에서 오버라이드
@Transactional // readOnly = false
public void updateProduct(Long id, String name) { ... }
}조회 메서드가 대부분인 서비스의 경우,
클래스 레벨에 @Transactional(readOnly = true)를 두고
변경이 필요한 메서드에서만 트랜잭션을 오버라이드하는 것이
가장 자연스럽다.
5.2 복제(Replication) 환경
Master/Replica 구조를 사용하는 경우,
readOnly 트랜잭션은 조회 요청을
읽기 전용 DB로 분리하기 위한 기준으로 활용될 수 있다.
# application.yml
spring:
datasource:
hikari:
data-source-properties:
readOnlyRoutingDataSource: true그러나 실제 라우팅 동작 여부는 DataSource 구성 및 인프라 설정에 따라 달라진다.
6. 배운 점
이번 테스트로 얻은 성능 차이는 크지 않았다.
하지만 막연하게 사용하던 readOnly = true 설정이
단순한 성능 수치 이상의 의미를 가지며
내부 동작을 제어하는데 큰 차이를 만들어냄을 확인할 수 있었다.
조회 로직을 쓰기 가능 트랜잭션으로 조회한다는 것은
변경이 필요하지 않음에도 불구하고
변경에 대비한 불필요한 과정을 거침으로써
불필요한 메모리 사용과 비용을 감수할 수 있었다는 것을 알게 되었다.
이번 포스팅을 통해, 어떤 기능을 사용할 때
어떤 과정을 통해 이루어지고 어떤 이점이 있어 사용하는지 이해한 상태에서
사용하는 것이 중요하는 점을 다시 한번 느낀다.
끊임없이 의문을 던지면서 의식하고 공부하는 것이 중요하다고 느꼈다.
