0. 들어가며
이번 포스팅에서는 로컬 캐시를 이용한 카테고리 캐시 적용으로 상품 조회 성능 개선 과정을 다뤄보려고 한다.
카페 주문 플랫폼에서 카테고리는 사용자가 상품을 조회할 때 가장 먼저 접하는 정보 중 하나로,
조회 빈도는 높지만 변경은 드문 데이터라는 특징을 가진다.
그럼에도 불구하고 사용자의 조회 요청마다 매번 DB를 조회하는 것이 과연 효율적인지 의문이 들었고,
이에 카테고리 조회에 캐싱을 적용했을 때 어떤 성능 개선 효과를 얻을 수 있는지 직접 확인해보기로 했다.
이번 글에서는 그 적용 과정과 결과를 정리해본다.
1. 문제 상황
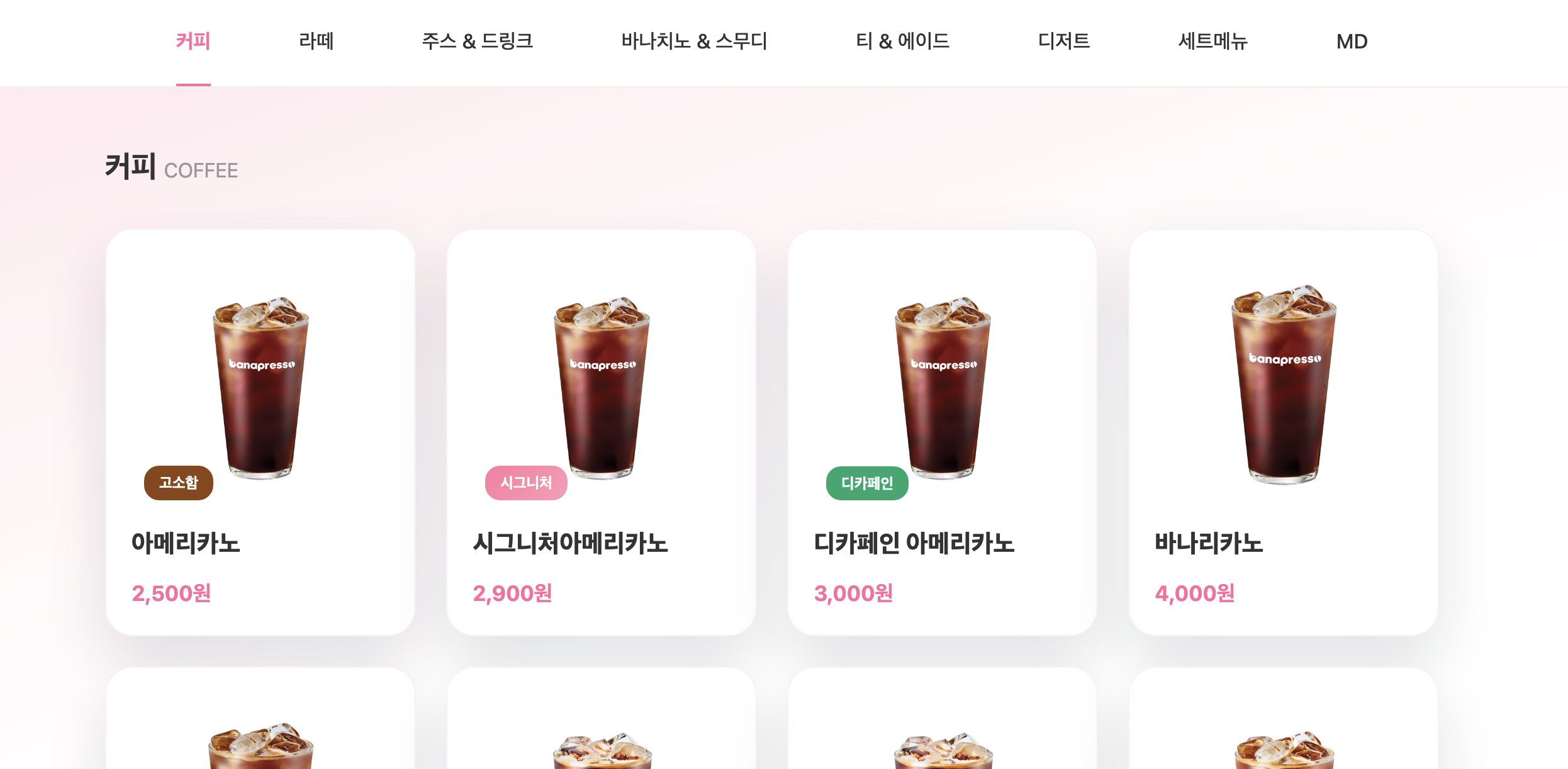
위 이미지는 우리 프로젝트의 상품 목록 페이지이다.
해당 페이지에는
커피, 라떼, 주스&드링크, 바나치노&스무디, 티&에이드, 디저트, 세트메뉴, MD
총 8개의 카테고리가 노출된다.
카테고리는 관리자가 직접 수정하지 않는 이상 거의 변경되지 않으며,
대부분의 경우 동일한 데이터가 지속적으로 유지된다는 특징을 가진다.
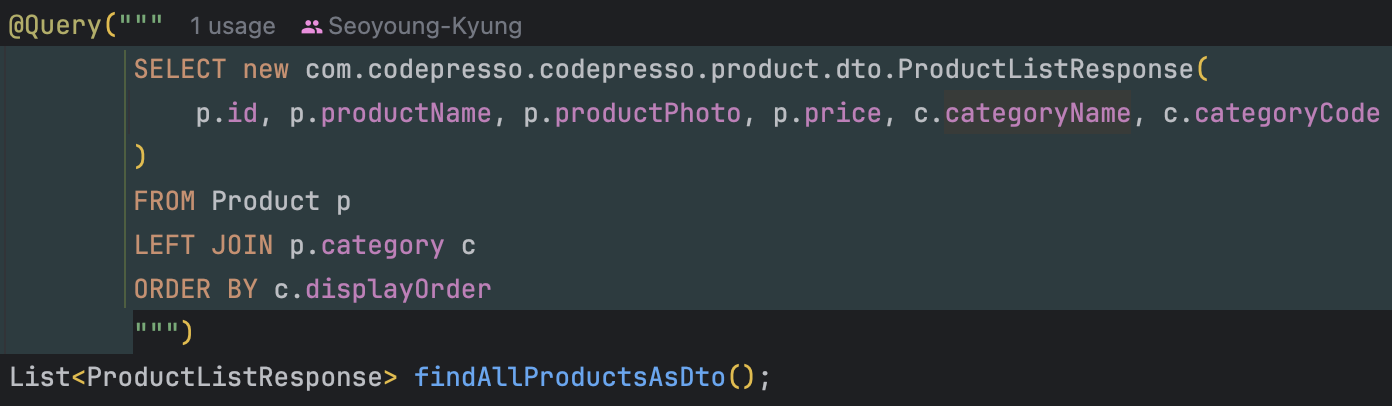
하지만 현재 구조에서는 상품 목록을 조회할 때마다
상품 데이터와 카테고리를 조인하여 함께 조회하고 있다.
카테고리 정보가 항상 동일함에도 불구하고
매 요청마다 DB 접근과 조인 연산이 반복적으로 발생하는 구조인 것이다.
이러한 구조는 사용자 수가 적을 때는 크게 문제되지 않지만,
상품 목록처럼 다수의 사용자가 반복적으로 조회하는 화면일수록
불필요한 DB I/O와 조인 비용이 누적되어 서비스 부하로 이어질 수 있다.
이 문제를 해결하기 위해,
변경 빈도는 낮고 조회 빈도는 높은 카테고리 데이터에 로컬 캐시를 적용하는 방향을 고려하게 되었다.
2. 해결 과정
간단 개념 정리 : https://velog.io/@se0o_129/cache-strategy
2.1 캐시 선택
카테고리 데이터에는 로컬 캐시를 선택했다.
카테고리는 조회는 자주 되지만 변경은 거의 없는 데이터라서,
매번 글로벌 캐시를 거쳐 외부 서버와 통신하는 것은 불필요하다고 생각했다.
로컬 캐시는 애플리케이션 내부 메모리에 데이터를 저장하기 때문에
네트워크 비용 없이 바로 조회할 수 있고,
자주 바뀌지 않는 카테고리 데이터와도 잘 맞는다고 판단했다.
또한 카테고리는 실시간 반영이 꼭 필요한 데이터가 아니기 때문에,
로컬 캐시로 인한 데이터 불일치도 크게 문제가 되지 않을 것 같았다.
2.3 캐시 읽기 전략 선택
캐시 읽기 전략으로는 Cache-Aside를 선택했다.
우선 상품 목록을 조회할 때마다 해당 메서드를 호출하지만,
카테고리 변경은 관리자만 수행하며 거의 발생하지 않는다.
조회가 많을수록 캐시를 활용했을 때 성능 개선 효과가 크다.
또한 카테고리 변경이 있어도 수십 분~몇 시간 뒤에 반영되어도 서비스에는 큰 영향을 주지 않는다.
즉시 정합성이 필요한 데이터(재고, 잔액 등)는 캐시보다는 DB 직접 조회가 적합하고 생각했다.
2.2 캐시 만료 전략 선택
캐시 만료 방식으로는 TTL과 명시적 무효화를 병합하여 사용하는 전략을 선택했다.
카테고리 데이터는 특성상 변경 빈도가 매우 낮아
데이터 변경 시점에 캐시를 직접 제거하는 명시적 무효화만으로도 충분히 관리 가능하다.
하지만 모든 변경 상황에서 무효화를 완벽하게 보장하기는 어렵기 때문에
무효화가 누락되는 경우를 대비해 TTL을 보조 수단으로 함께 적용하기로 했다.
TTL은 24시간으로 설정하여
최악의 경우에도 캐시 데이터가 하루 이상 유지되지 않도록 하였고,
이를 통해 오래된 데이터가 지속적으로 제공되는 상황을 방지하고자 한다.
2.4 코드 개선
1. cacheManager 설정
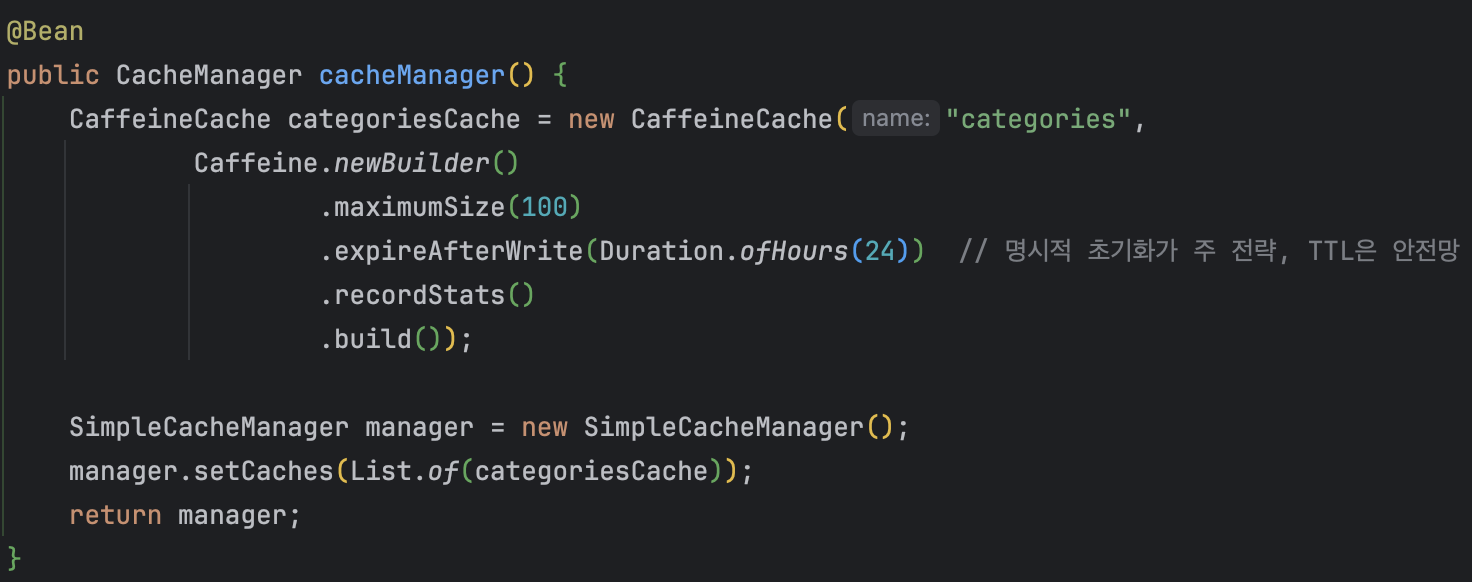
TTL을 24시간으로 설정하여, 최악의 경우에도 캐시 데이터가 하루 이상 유지되지 않도록 관리했다.
용량 초과 시에는 Caffeine의 eviction 정책(LRU 기반)에 따라
오래 사용되지 않은 데이터가 자동으로 제거되도록 구성했다.
2. @Cacheable 적용
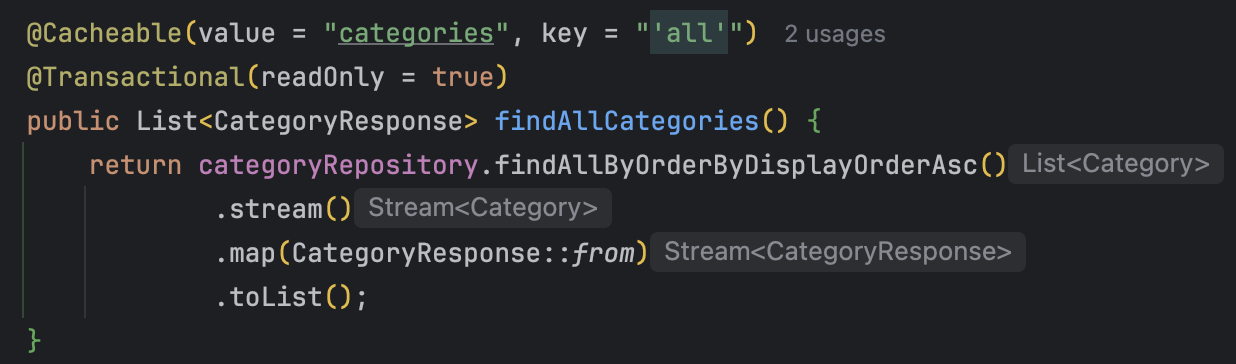
@Cacheable 어노테이션을 카테고리를 가져오는 메서드에 적용했다.
캐시 이름은 categories로 지정하여,
메서드 호출 결과를 이 캐시 영역에 저장하고 재사용할 수 있도록 설정했다.
3. 조인 제거 및 캐시 데이터 활용
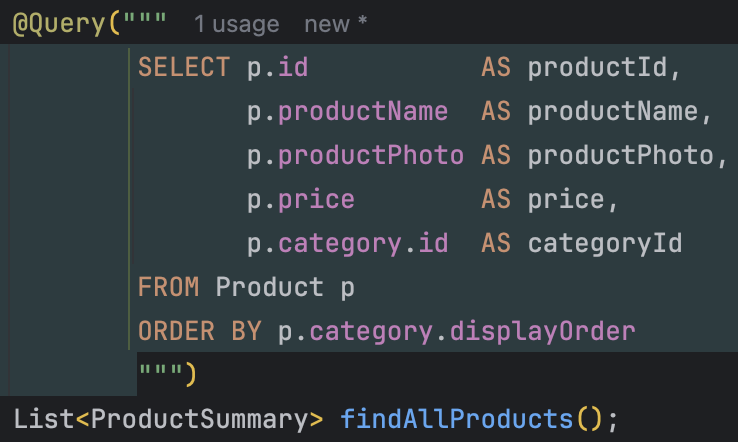
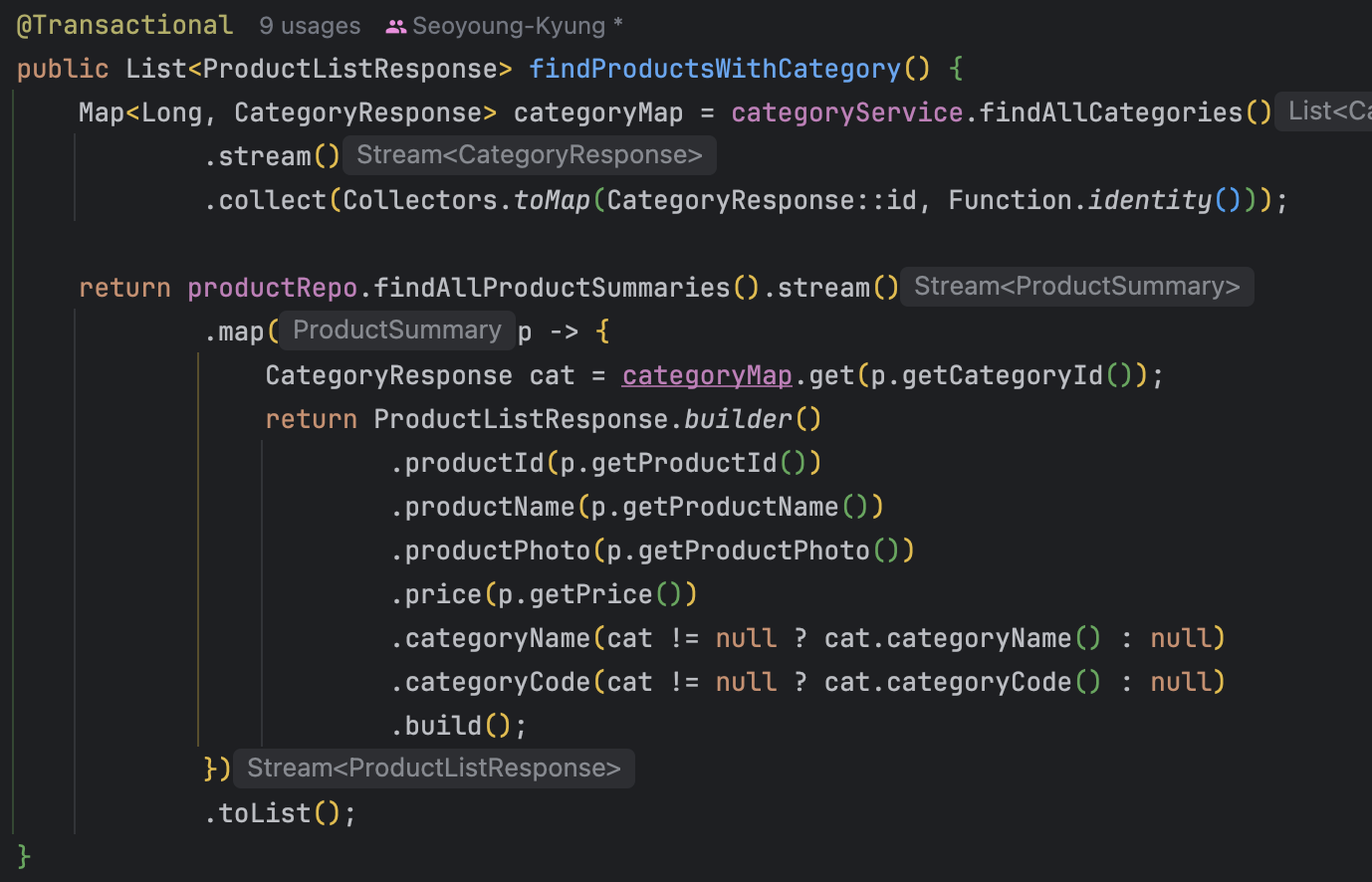
기존에는 상품 조회 시 카테고리와 조인하여 데이터를 가져왔지만,
이제는 조인을 제거하고 캐시된 카테고리 데이터를 이용해 상품과 매치하는 방식으로 개선했다.
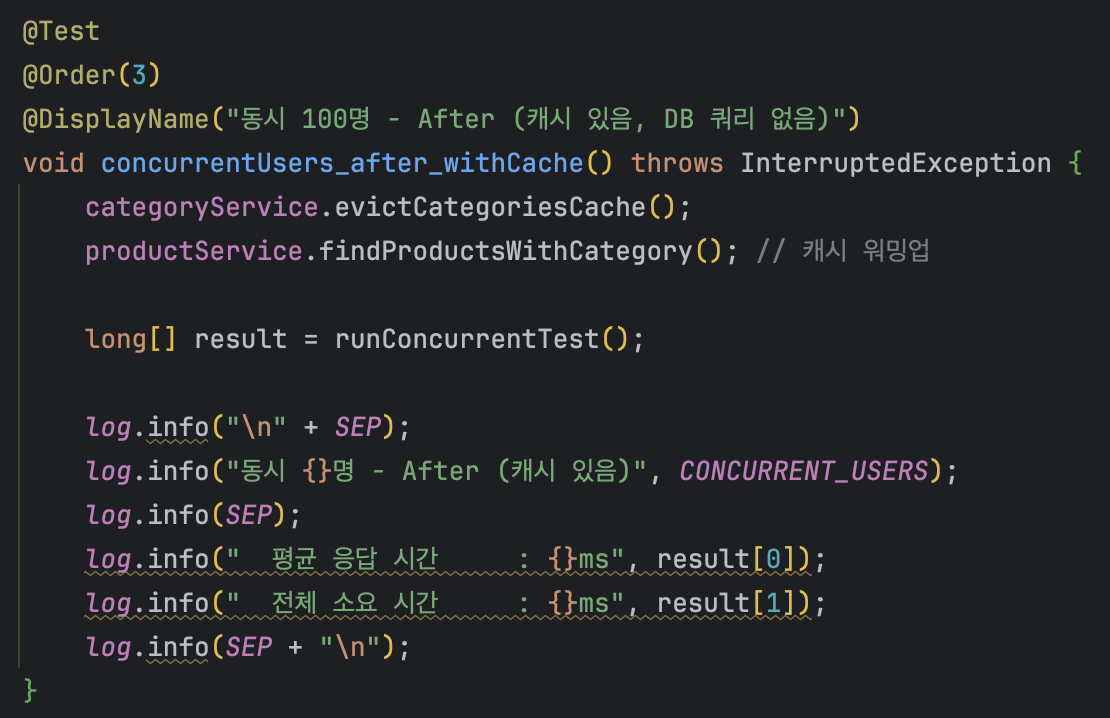
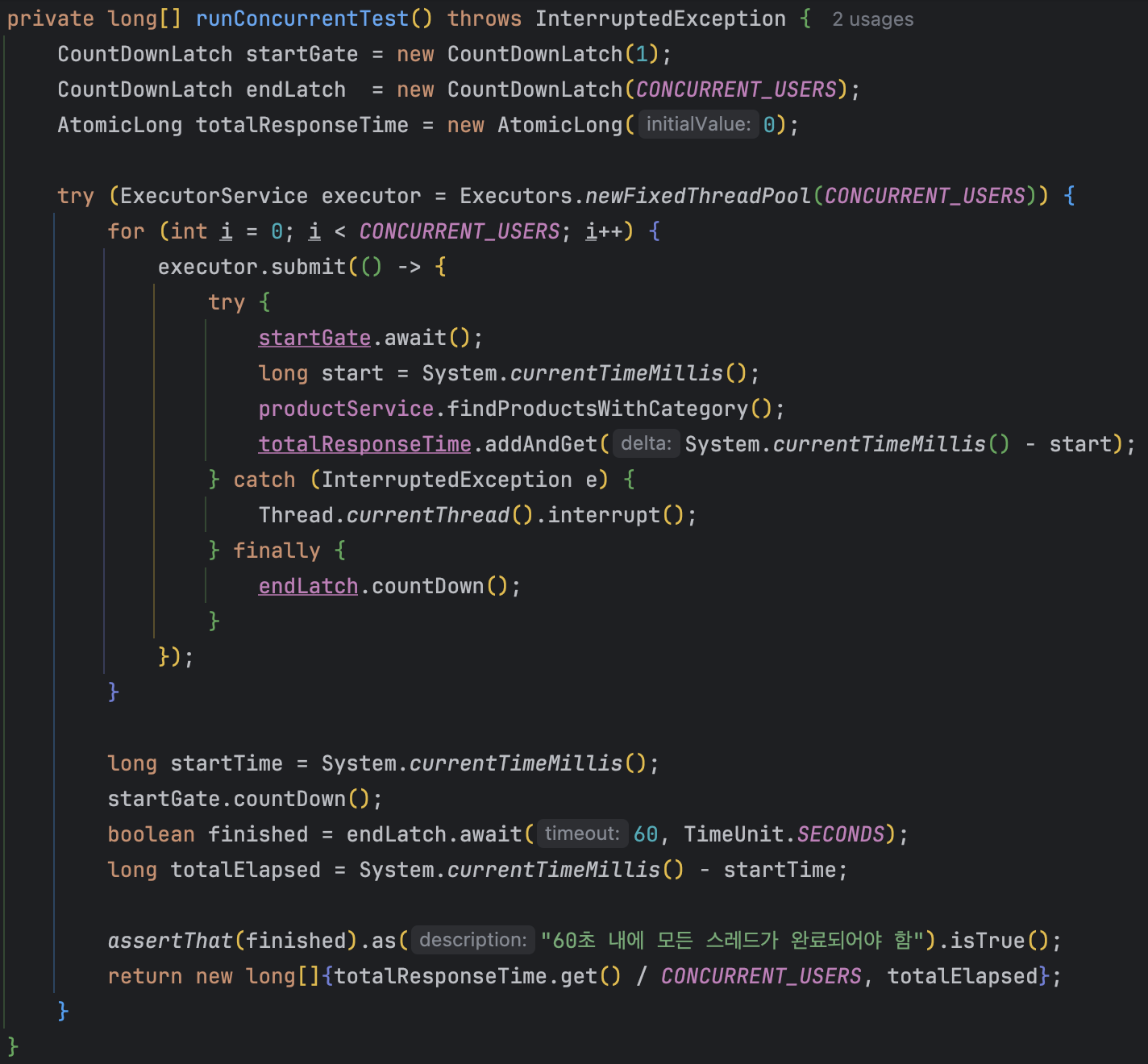
2.5 테스트 코드
피크타임에 여러 매장에서 동시 100명이 상품 목록을 조회하는 상황을 가정하여 테스트 코드를 구성했다.
캐시 적용 전과 후를 동일한 조건으로 측정하여 성능 차이를 비교하였다.

3. 결과
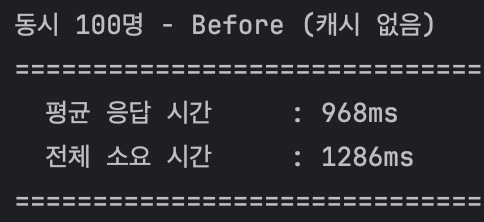
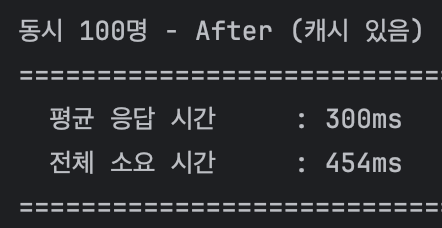
캐시 적용 전에는 평균 968ms가 소요되었지만,
캐시 적용 후에는 평균 300ms로 줄어드는 것을 확인할 수 있었다.
단일 조회 시에는 큰 병목이 발생하지 않지만,
동시 접속자가 늘어나면 DB 조회 부담은 급격히 증가하게 된다.
같은 조건에서도 캐시 유무에 따라 성능 차이가 뚜렷하게 발생함을 확인할 수 있었다.
4. 배운점
이번 캐시 적용을 통해 조회 성능을 개선할 수 있었지만,
카테고리 데이터가 8개로 매우 적고 조회 비용이 크지 않았다는 점을 고려하면
필수적인 최적화는 아니었다고 생각한다.
다만 조회 빈도가 높은 데이터에 대해 캐시를 적용하고,
Cache-Aside 전략과 무효화 방식(TTL + 명시적 제거)을 직접 설계해본 경험은 의미 있었다.
실제 서비스에서는 데이터 규모와 트래픽을 기준으로
캐시 도입 여부를 판단하는 것이 중요하다는 점을 배울 수 있었다.
