<논문>
Auto-Encoding Variational Bayes
<참고자료>
[YouTube] 오토인코더의 모든것
[github.io] Variational AutoEncoder
[arXiv] Tutorial on Variational Autoencoders
Variational AutoEncoder (이하 VAE)는 AutoEncoder 구조를 가진 생성모델이다. 하지만 AutoEncoder와 구조만 같을 뿐, 목적은 완전히 다르다. VAE를 알아보기에 앞서 AutoEncoder가 무엇인지 간단하게 알아보자.
1. AutoEncoder
AutoEncoder는 비지도학습(unsupervised learning)을 위해 제안된 모델이다. 라벨이 없는 이미지를 분류하려고 한다면, 어떻게 하는 것이 좋을까?
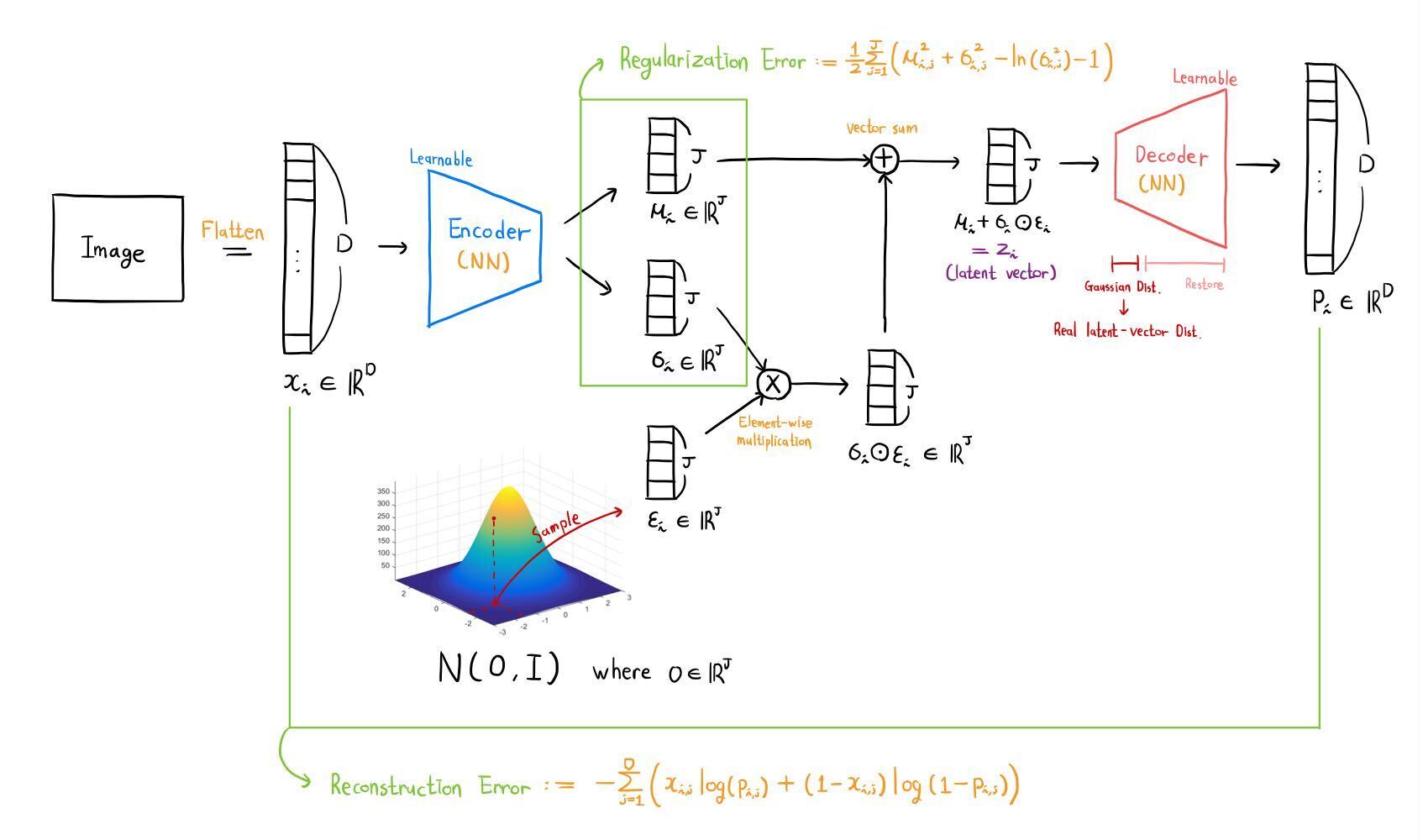
Latent Vector
이미지는 벡터로 볼 수 있다. MNIST 이미지를 예로 들면, 각 이미지는 28x28=784개의 픽셀을 가지므로 784차원의 벡터로 볼 수 있다. 즉, 784개의 숫자(값)가 하나의 이미지를 표현한다고 볼 수 있다.
조금 다르게 해석하면, MNIST의각 이미지를 구성하는 784가지 특성이 존재한다고 볼 수 있다. 이러한 특성을 조합하여 이미지를 구성할 것이다.
하지만 한 이미지를 표현하는 데 784개의 특성이 필요하진 않을 듯 하다. 즉 784차원의 벡터를 더 낮은 차원으로 압축하여 표현할 수 있고, 압축된 벡터를 latent vector라 부른다. 압축을 담당하는 Neural Network를 Encoder라 한다.
비지도학습
AutoEncoder의 목적은 라벨이 없는 데이터를 압축된 벡터로 잘 표현하는 것이다. 하지만 라벨이 있는 데이터와는 달리, 데이터가 잘 압축되었는지 확인할 방법이 없다.
데이터로부터 latent vector를 잘 추출하였는지 확인하기 위해 Decoder를 추가하였다. Decoder는 latent vector를 받아, 처음 입력했던 이미지(벡터)를 복원하는 역할을 한다. 처음 이미지와 복원된 이미지의 차이를 Loss Function으로 설정하여, 이미지를 잘 압축하고 잘 복원하도록 네트워크를 학습시킨다.
그 결과 latent vector를 잘 추출하는 Encoder(Neural Network)를 얻을 수 있다.
학습된 Encoder는 다음과 같이 사용할 수 있다.
- Encoder의 마지막에 Classification을 위한 fully-connected layer를 덧붙인다.
- 소수의 라벨이 있는 데이터를 이용하여 마지막 layer만을 학습시킨다.
예를 들어 MNIST 데이터라면, 0부터 9까지를 분류하는 layer를 학습시키는 것이다. - Encoder는 latent vector를 잘 추출하고, 마지막 layer는 latent vector로부터 classification을 잘 수행하므로, 라벨이 없는 이미지를 분류하는 모델을 완성하였다.
요약
AutoEncoder는 잘 학습된 Encoder를 얻기 위해 Decoder를 붙인 모델이다.
VAE에 들어가기 앞서, AutoEncoder는 Encoder를 얻기가 목적이었음을 잊지 말자.
2. Variational AutoEncoder (VAE)
VAE는 이름 안에 AutoEncoder를 담고 있지만, AutoEncoder와의 공통점은 구조가 똑같다는 점 뿐이다. 생김새가 비슷하다는 점만 기억해두고 AutoEncoder는 잠시 잊어두자.
개요
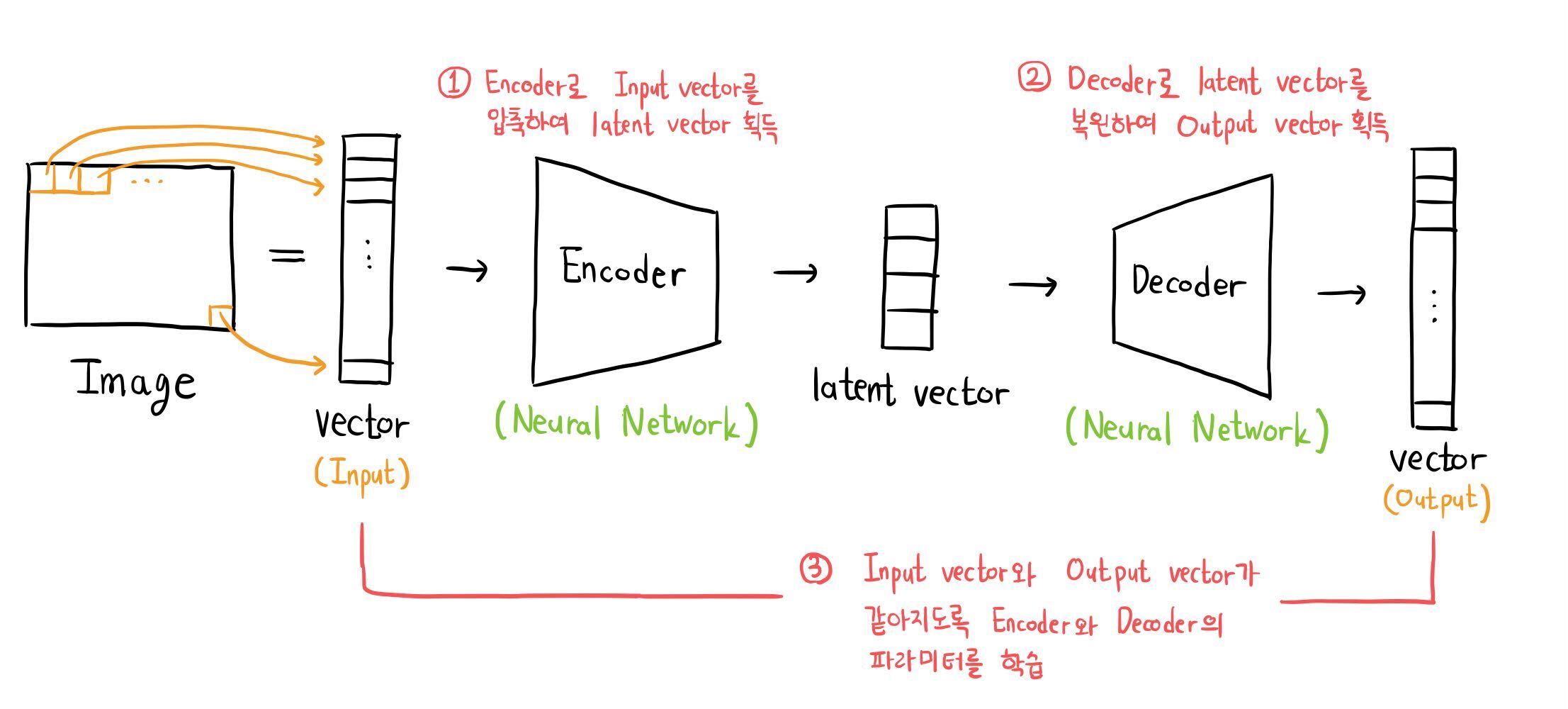
VAE의 목적은 Training data와 유사한 이미지를 생성하는 것이다. 주 아이디어는 "낮은 차원의 벡터(latent vector)로부터 높은 차원의 벡터(이미지)를 획득"하는 것이다. 차원을 높이기 위해 Decoder(Neural Network)가 활용된다.
latent vector를 네트워크의 입력으로 이용하는 이유는 무엇일까? AutoEncoder에서처럼, 이미지는 낮은 차원의 latent vector로 압축될 수 있다. 이때 유사한 이미지의 latent vector는 어떠한 공간에 모여있을 것임이 전제된다. [1]
만약 Training data의 latent vector가 어디에 모여있는지 찾을 수 있고 이를 잘 복원하는 Decoder가 있다면, 그 인근의 latent vector 를 Sampling 하여 새로운 Training data에 있을법한 이미지를 얻을 수 있을 것이다.
1차 학습
이제 학습 구조를 설계해보자. 1차 학습이라 칭한 이유는, 이 방법이 실패할 것이기 때문이다.
앞으로 자주 쓰일 표현을 정리하고 시작하자. 필자도 이 표현을 해석하는 것이 가장 골치아팠다.
-
: Training data 가 실제 Training data 분포에서 Sampling 될 가능도 [2], 를 변수로 본다면 확률분포의 PDF라 해석할 수 있으며, 가 Sampling 되는 분포 그 자체로 해석될 수도 있다.
-
를 쉽게 해석해보자. 우리는 사실 실제 Training data 분포를 찾는 것이 가장 좋다. 그 분포에서 점을 Sampling하는 것만으로도 새로운 이미지를 생성해낼 수 있기 때문이다. 하지만 실질적으로 실제 Training data 분포를 찾기는 불가능하다. [3]
-
따라서 우리가 가진 Training data가 실제 Training data 분포에서 Sampling 되었을 것이라 가정하고, 그 분포가 무엇인지 추정할 것이다. 분포에서 점은 확률적으로 Sampling 되므로, Training data를 Sampling 하였다고 말할 수 있는 분포는 수없이 많을 것이다. 단, 분포마다 그 가능성은 다를 것이다. [4]
-
수많은 분포 중 어떤 분포를 선택하는 것이 가장 합리적일까? 이를 비교하기 위해 가능도 개념이 필요하다. 우리가 가진 Training data가 그 분포로부터 Sampling 되었을 가능성을 가능도로 측정하는 것이다. [5] [6]
-
따라서 실제 Training data 분포에서 점(이미지)을 Sampling 하였을 때, 우리가 가진 Training data가 Sampling 될 가능성이 가장 높은 분포를 찾을 것이다. 설령 진짜 분포가 아니더라도, 그 분포는 실제 Training data 분포일 가능성이 가장 높을 것이다.
-
즉, 네트워크는 가 최대가 되는 방향으로 학습될 것이다.
-
-
: latent vector 가 주어질 때, Training data 가 실제 Training data 분포에서 Sampling 될 가능도, 를 변수로 본다면 확률분포의 PDF라 해석할 수 있으며, 가 Sampling 되는 분포 그 자체로 해석될 수도 있다.
-
어떠한 latent vector 가 주어질 때의 가능도이다. latent vector 는 Decoder를 통과하여 어떠한 확률분포의 모수가 되며, 결국 모수가 결정된 확률분포에서 Training data 가 Sampling될 가능도라고 볼 수 있다.
-
와 모두 실제 Training 분포에서의 가능도지만, 분포의 형태는 다르다. 는 조건 가 추가되었으므로 의 분포의 일부라고 볼 수 있겠다.
-
latent vector 가 어떠한 확률분포의 모수로 잘 변하도록 Decoder는 학습하게 될 것이다. (= Neural Network인 Decoder의 파라미터가 최적화될 것이다.) 이를 명시하기 위해 를 붙인다.
-
- : 유의미한 (=Training data와 유사한) 이미지를 생성하는 latent vector의 분포에서 가 Sampling될 가능도, 를 변수로 본다면 확률분포의 PDF라 해석할 수 있으며, 가 Sampling 되는 분포 그 자체로 해석될 수도 있다.
- 아무 를 통과시킨다고 유의미한 이미지를 얻을 수 있진 않을 것이다. 유의미한 latent vector가 모여있는 공간이 존재할 것이고, 그 분포에서 가 Sampling될 가능도이다.
우리의 목표는 Training data 에 대하여 를 최대가 되도록 하는 것이다. 가 어떤 분포로부터 계산되었는지조차 모르지만, Bayesian Inference에 의해 는 다음과 같이 표현될 수 있다. [7]
와 를 최대화시켜 를 최대로 만들어보자.
- : 유의미한 latent vector가 Sampling 될 수 있도록 하는 확률분포가 존재할 것이다. 하지만 우리는 이를 평균이 (영벡터), 공분산이 (항등행렬)인 Multivariate Gaussian Distribution라 가정한다. [8]
- 결국 는 결정된 값이다. 더 이상 할 수 있는 것이 없다.
- : latent vector z가 Decoder를 통과하여 어떤 확률분포의 모수가 되고, 그 모수를 바탕으로 만들어진 확률분포에서 Training data 가 Sampling 될 가능도를 의미한다.
- 의 값을 높이는 방향와 같은 맥락의 식이 있다. 가 Decoder를 통과하여 나온 벡터를 라 할 때, 두 벡터 , 가 같아지는 방향이다. [9]
- 즉, 와 가 같아지도록 Decoder의 파라미터를 학습하자.
- : 적분을 컴퓨터 언어로 표현하기 위해 몬테카를로 근사(Monte Carlo Approximation)를 활용할 수 있다. [10] 모든 를 대상으로 하지 않고, 몇 개의 값을 Sampling 하여 그 합으로 대체하는 것이다.
이제 학습을 진행할 수 있을 듯 하다.
1차 학습 _ 실패
하지만 이 방법은 성공하지 못했다. 의미적으로 오류가 발생했기 때문이다.

(a)는 Training data이고, (b)와 (c)는 Sampling 된 로부터 생성된 이미지이다. 상식적으로 (c)가 (b)보다 '2'에 가깝지만, 실제 (a)와의 오차는 (a)~(b)가 (a)~(c)보다 작다. 즉, 모델은 (b)가 더 '2'에 가까운 이미지라고 학습한 것이다.
오차를 계산하는 metric을 변경하여 위의 문제를 해결할 수 있겠지만 이는 효율적인 방법이 아니라 판단하였고, 논문은 다른 방법을 제시한다.
2차 학습
중간점검을 해보자. 우리는 를 최대로 만들고 싶었으나 잘 모르므로
로 만들어 , 를 계산하려고 했다.
실질적으로 대부분의 에 대하여 가 거의 0이었다고 한다. 이는 몇 개의 만을 Sampling 하던 1차 학습 기법에서 좋지 않은 영향을 준다. 결국 Gaussian Distribution에서도 의미있는 만을 뽑아야 한다는 뜻이다.
를 잘 뽑아야 된다는 것은 결국 가 아닌 어떠한 입력 이미지 별 유의미한 의 분포로부터 가 뽑혀야 함을 의미한다. [11] 이는 Training data 를 잘 생성할 것 같은 의 분포를 의미하기 때문에 를 조건으로 둔 분포이고, 이 분포에서 가 Sampling 될 가능도를 라 정의한다.
사실 역시 알 방법이 없다. 따라서 이에 가장 근사하는, 비교적 간단한 분포 를 정의하고 그 모수를 학습으로 찾아낼 것이다. 이 모수는 입력되는 Training data 에 따라 달라질 것이다.
이 점을 고려하기 위해, 위의 식과 다른 방법으로 를 표현하고 해석해보자. 를 최대로 만들겠다는 목표는 변하지 않았지만, 대신 를 최대로 만들어보자.
가 3개의 항으로 분리되었다. 각 항의 의미를 살펴보자.
- : 기댓값으로 볼 수 있다. 즉,
- : 두 확률분포의 KL Divergence로 볼 수 있다. 즉,
- : 두 확률분포의 KL Divergence로 볼 수 있다. 즉,
이를 종합하면,
이다.
한 가지 트릭으로, 우리는 가 어떤 확률분포인지 알지 못한다. 하지만 가 에 근사하길 바라는 방향으로 Encoder와 Decoder를 학습시킬 것이므로, 최적화된 상태에서 는 0에 가깝다. 따라서 를 최대로 만들 때 항은 고려하지 않는다. [15]
이고, 의 하한(lower bound)을 최대로 끌어올림으로써 의 최대를 찾는다고 할 수 있겠다.
이제 컴퓨터가 를 최대로 만들도록 네트워크를 최적화(Encoder, Decoder의 파라미터를 학습)해보자.
우리는 경사하강법(Gradient Descent)을 이용하여 최적화할 것이므로, Loss Function의 하강이 곧 의 상승이 되도록 Loss Function을 설정해보자. 가장 간단한 방법은 무엇일까? 바로 마이너스(-)를 붙이는 것이다. 즉,
이므로, 를 Loss Function으로 설정한다면 결과적으로 가 최대가 되도록 파라미터를 학습할 수 있을 것이다.
Loss Function을 구체화하기 전, 의 각 항이 무엇을 의미하는지 간단히 살펴보자.
- : Training data 로부터, 와 유사한 이미지를 생성할 가능성이 있는 의 분포(의 모수)를 찾아내고, 해당 분포에서 Sampling 한 로부터 만들어진 '비슷한 끼리의 분포'에서 를 Sampling 할 음의 로그가능도이다.
- 즉, 입력 데이터 와 '비슷한 끼리의 분포'에서 생성된 데이터 간의 다른 정도를 의미한다. 낮을 수록 두 데이터는 유사하며, 이 항을 Reconstruction Error라 부른다.
- : 1차 학습 때 를 Sampling 하려던 분포 와, 입력 이미지 별 이상적인 를 Sampling 할 수 있는 분포 에 근사하려는 분포 간의 KL Divergence 이다.
- 즉, 두 확률분포 와 간의 비슷한 정도를 의미한다. 낮을수록 두 분포는 유사하며, 이 항을 Regularization Error라 부른다.
두 항 모두, 감소하는 방향이 우리가 원하는 방향과 같다.
마지막으로, 의 각 항을 Loss Function으로 만들어보자. 번째 데이터의 학습에 대해 (아래첨자)를 붙여 표현할 것이다.
- Reconstruction Error
- Regularization Error
계산에 앞서, 는 평균이 , 공분산이 인 Gaussian Distribution이라 가정한다. 는 개의 대각성분이 의 제곱과 같은 행렬이다. [20] 어차피 실제 분포가 아닌 근사 분포이고, 두 Multivariable Gaussian Distribution의 KL Divergence를 수월하게 구하기 위한 선택이다.
2차 학습 _ Architecture
학습할 준비가 끝났다. 2차 학습의 과정을 도식화한 그림은 다음과 같다.
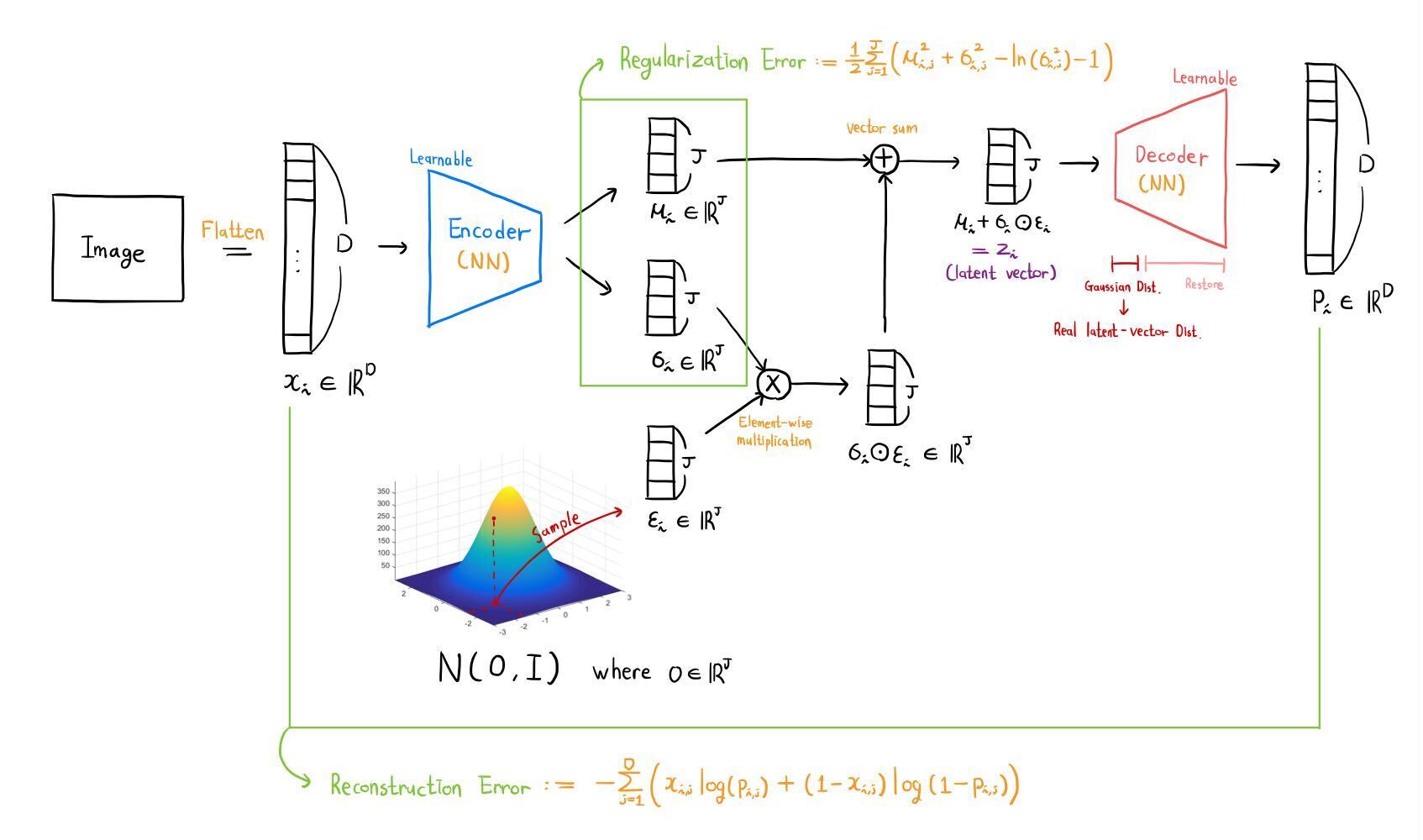
이전 문단에서 등장하지 않은 벡터가 있는데, 바로 이다. 가 도입된 이유는 Reparameterization Trick을 사용하기 위함이다. [22] [23]
2차 학습 _ Inference
VAE의 목적은 이미지를 생성하는 것이다. 즉, Inference는 Decoder를 이용하게 된다. VAE의 Encoder는 Decoder를 도운 역할이었음을 잊지 말자.
VAE의 Model Inference는 에서 Sampling 한 latent vector를 Decoder에 통과시켜 이미지를 얻어내는 방식으로 진행된다. 여기서 AutoEncoder와 차별화되는 VAE의 강점이 드러난다.
다음 그림은 latent vector space를 2차원이 되도록 네트워크를 구성하고, 학습이 완료된 후 Test data가 주어졌을 때의 latent vector를 시각화한 것이다. 왼쪽은 AutoEncoder, 오른쪽은 VAE이다.
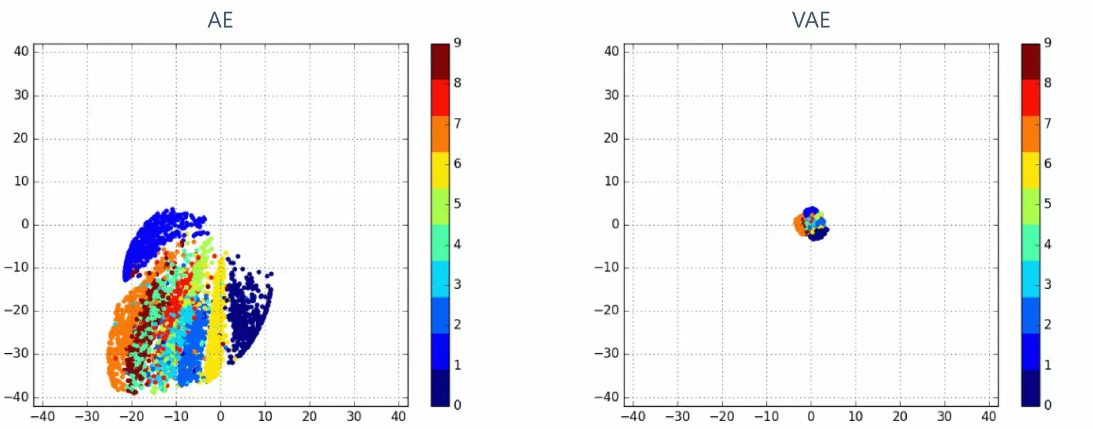
두 그림의 가장 큰 차이점은, latent vector가 잘 모여있는가이다. AutoEncoder는 latent vector의 반경이 넓고 불규칙적이므로, 어떤 latent vector를 선택하여 Decoder를 통과시켰을 때 유의미한 이미지를 얻을 수 있다고 보장받기 힘들다.
반면 VAE는 latent vector가 잘 모여있다. [24] 반경 내의 latent vector를 Sampling 하여 Decoder에 통과시키면 유의미한 이미지가 나올 가능성이 높다고 말할 수 있겠다. 즉, 유의미한 이미지를 만드는 latent vector의 범위를 예측 가능한지가 두 모델의 차이이다.
latent vector의 차원은 조절이 가능하다. latent vector의 차원이 클수록 이미지의 특성을 더 다양하게 함축하겠노라 말할 수 있겠다. 다음은 각각 2차원, 5차원, 10차원, 20차원으로 설정한 뒤 Model Inference (Generation)를 거친 결과이다.

Furthermore
이후에는 원하는 이미지에 대한 조건을 걸어 이미지를 얻어내는 Conditional Variational AutoEncoder (CVAE), GAN과 함께 이미지를 생성하는 Adversarial AutoEncoder (AAE) 등이 연구되었다.
3. Endnote
[1] MNIST 이미지로 예를 들어보자. 이미지는 벡터로 볼 수 있고, 벡터는 공간 상의 점으로 볼 수 있다. 즉 이미지 1장은 784차원 공간 상의 점 1개이다. 사람이 보기에 '3'으로 해석되는 이미지는 784차원의 공간 상에서 서로 모여있을 것이다. 겨우 한 두 픽셀의 차이로 '3'의 형태가 무너지지 않을 것이기 때문이다.
Encoder는 Neural Network이고, 세부적으로 살펴보면 여러 함수의 합성이다. 선형변환(Linear), ReLU, Sigmoid 모두 연속함수이고, 연속적으로 모여있는 점(이미지)들을 연속함수에 몇 번을 통과시키더라도 결과는 연속적일 수 밖에 없다. 즉, '3'처럼 같은 의미를 가진 이미지의 latent vector는 낮은 차원의 공간 상에서 서로 모여있을 것이라 추측할 수 있다.
[2] 연속확률변수의 개별 값은 모두 0의 확률을 갖는다. 하지만 확률밀도함수(이하 PDF)를 살펴보면 엄밀히 '빈도'의 차이는 발생한다. 표준정규분포에서 점을 Sampling할 때 100,000보다 0 근처 값이 많이 뽑히는 것처럼, '빈도'의 차이를 설명하기 위해 '가능도' 개념이 도입된다.
가능도는 확률이 아니다. 점을 Sampling할 때, 그 점이 뽑힐 상대적인 가능성으로 해석하면 좋을 듯 하다. 가능도 값은 PDF의 함숫값으로 표현된다.
[3] MNIST 이미지로 예를 들자. 실제 Training data 분포는 모든 0부터 9까지의 손글씨 이미지가 모여있는 분포를 의미한다. 실질적으로 이 분포를 찾기는 불가능한데, 그 이유는 사람마다 숫자를 쓰는 손글씨가 다르고 그 방법은 무궁무진하기 때문이다.
[4] 평균이 1,000,000이고 표준편차가 1인 정규분포에서 Sampling을 하더라도 -1,000,000이 뽑힐 가능성은 존재한다. 다만 아주 희박한 가능성이고, 따라서 우리가 원하는 분포는 아닐 것이다.
[5] 평균은 모르고 표준편차가 1인 정규분포를 생각해보자. 그 분포에서 점을 5개 뽑았더니 모두 10이 나왔다. 어떤 분포가 '5개의 점을 뽑았더니 모두 10이 나올 가능성'이 클까? 직관적으로 정답은 평균이 10인 정규분포이다. 이를 수치적으로 정확하게 비교하기 위해, 각 점이 뽑힐 가능성을 '가능도'로 표현하고, 가능도가 가장 높은 확률분포를 찾는 것이다.
평균이 , 표준편차가 1인 정규분포의 PDF 는 이고, 이 정규분포에서 10이 Sampling될 가능도는 이다. 다수의 값이 Sampling될 가능도는 각 가능도의 곱으로 표현하며, 10이 5번 Sampling될 가능도는 이고, 이 값이 최대가 되는 순간은 가 10일 때이다.
즉, 10이 5번 Sampling 될 가능성이 가장 높은 분포는 평균이 10인 정규분포이므로, 우리가 Sampling을 진행한 분포는 평균이 10인 정규분포일 것이라고 합리적으로 생각할 수 있다.
이는 최우원리를 전제로 한다. Sampling은 확률적이므로, 낮은 가능도의 점이라도 낮은 가능성으로 Sampling될 수 있다. 하지만 가장 높은 가능성의 사건이 발생했을 것이다라는 전제 때문에, 우리는 가능도가 가장 높은 분포를 찾는 것이 목표이다. Sampling 되는 점이 많을수록 (=Training data가 많을수록), 가능도가 가장 높은 분포는 우리가 원하는 분포일 가능성이 높을 것이다.
[6] 이것이 최대가능도 추정(Maximum Likelihood Estimation)이며, 보통은 확률분포가 무엇인지 아는 상태에서(정규분포, 베르누이분포 등) 그 분포의 모수를 추정하지만, 지금은 실제 Training data 분포가 복잡하여 어떤 확률분포를 따르는지 모르는 상태라고 보면 된다.
[7] 이 식은 Bayesian Inference에서 기인한 것이다. Bayesian Inference는 사전확률과 추가 정보를 바탕으로 사후확률을 추정하는 방법이다.
Sampling 된 데이터 가 주어졌을 때, Sampling이 이루어진 그 분포를 찾고자 한다. 달리 말하면, 그 분포의 모수 를 찾고자 한다. 이때, 사후확률(데이터가 주어졌을 때 모수의 가능도)는 다음과 같이 치환될 수 있다
이때 는 확률함수로, 모든 구간에 대해 적분하였을 때 1이 나와야 한다. 따라서
로 표현될 수 있다. 전확률법칙(law of total probability)을 생각한다면 자연스러운 표현이라 생각할 수 있을 것이다.
더 자세한 내용은 marginal likelihood 또는 normalization constant에서 찾아보자.
[8] 의아한 설정이지만, Decoder의 초기 1~2개의 layer를 통해 Gaussian Distribution을 따르는 값들이 유의미한 latent vector의 분포를 따르도록 바꿔줄 수 있다고 한다.
즉, latent vector가 어떤 분포를 가짐과 상관없이, 정규분포로부터 를 Sampling 하여 몇 개의 layer를 거치면, 값은 우리가 원하는 latent vector 분포를 따를 것이다.
이는 Neural Network가 근사 함수의 역할을 하기 때문이다. 본질적으로 딥러닝을 사용하는 이유는 Neural Network가 비선형 함수에 강력하게 근사할 수 있기 때문이다. 즉, 정규분포 점을 latent vector space의 점으로 mapping하는 함수에 근사한 것이다.
[arXiv] Tutorial on Variational Autoencoders
[9] 표준편차가 로 고정된 정규분포로 예를 들어보자. 어떤 입력데이터 가 어떤 Neural Network 를 거친 결과가 정답인 와 같아지기를 원한다고 하자. 즉, 와 가 같아지는 방향이다. 편의상 , 는 벡터가 아닌 하나의 값으로 둔다.
이제 평균이 , 표준편차가 인 정규분포에서 를 Sampling 할 가능도를 살펴보자. 정규분포에서 가장 Sampling 될 가능도가 높은 값은 무엇일까? 바로 평균()이다. 즉, 와 가 같아지는 방향은 곧 가 Sampling 될 가능도가 높아지는 방향이다.
[10] 를 살펴보면 마치 기댓값을 구하는 형태와 같음을 알 수 있다. 즉,
인데, 를 연속확률변수가 아닌 Sampling 에 의한 이산확률변수로 본다면 그 기댓값은
로 근사하게 된다.
[11] MNIST를 예로 들면, '2'를 잘 생성하는 latent vector 는 '8'을 만드는 데 고려될 필요가 없다는 뜻이다.
[12] 밑이 1보다 큰 로그함수는 증가함수이다. 논문의 는 밑이 자연상수()이므로, 의 증가감소는 의 증가감소와 같다.
[13] 는 확률분포의 PDF이므로 이다.
[14] Bayes' Theorem에 의해 이다.
[15] 모든 KL Divergence는 0 이상이다. 두 확률분포가 같을 때 0이고, 다를수록 값이 증가한다.
[16] Monte Carlo Approximation에 의해, 기댓값 은 몇 개의 를 뽑아 평균을 낸 와 근사한다. 값이 클수록 더욱 근사해진다.
[17] 학습 시 계산량이 방대한 이유로, 각 마다 1개의 를 Sampling 하여 학습을 진행하였다.
[18] [9]의 연장선이다. 가 증가하는 방향은, 가 Decoder를 통과하여 만들어진 가 와 같아지는 방향이고, 를 모수로 갖는 어떠한 확률분포로부터 가 Sampling 될 가능도가 증가하는 방향이다.
만약 어떠한 확률분포가 Gaussian Distribution이라면 는 MeanSquare Error로 계산되며, Bernoulli Distribution이라면 CrossEntropy Error로 계산된다.
- Gaussian Distribution
- Bernoulli Distribution
정리하자면, 가 어떤 확률분포이냐에 관계없이 가 증가하는 방향은 와 가 같아지는 방향이고, 특별히 가 베르누이 분포이면 CrossEntropy Error와 같은 형태가 되며 이 역시 와 가 같아지는 방향이므로, 를 Bernoulli Distribution이라 가정하더라도 학습은 잘 일어난다.
만약 를 Bernoulli Distribution이 아닌 Gaussian Distribution으로 가정했다면 다른 형태의 Reconstruction Error가 도출될 것이다.
[19] 위 식의 결과는 결국 벡터이다. 벡터의 모든 성분을 합하여 하나의 오차값으로 만들었다.
계산의 편의성을 위해 간단한 공분산을 가정한다.
[21] 두 Multivariable Gaussian Distribution의 KL Divergence를 구하는 공식은 다음과 같다.
은 행렬의 대각성분의 합이고, 는 Multivariate Gaussian Distribution의 차원 수이다. 즉, 의 차원 수이다.
[22] 우리는 역전파(Backpropagation)를 통해 Encoder와 Decoder의 파라미터를 학습할 것이므로 Loss Function은 미분 가능한 형태여야 한다. 문제는, 가 미분 가능한가에 대한 것이다. 원래대로라면 는 평균이 , 표준편차가 인 Gaussian Distribution에서 Sampling 되어야 한다. 비록 는 확률'변수'지만 미분이 가능할까? 는 , 에 크게 영향을 받는데, 그렇다면 나 를 구할 수 있을까?
정답은 불가능하다. 하지만 표현방식만 달리하면, 똑같은 의미임에도 미분이 가능하도록 바꿀 수 있다. Isotropic Gaussian Distribution 에서 를 Sampling 하여 로 표현하는 것이다. (element-wise multiplication)
직관적으로 와닿지 않는다면, 고등학교 확률과통계에서 배운 정규분포 표준화를 떠올려보자. 인 확률변수 에 대하여, 이 성립하므로 그 반대 방향도 가능하다는 직관을 얻을 수 있을 것이다.
무작위로 결정되는 값이 , 에 의존하지 않는다는 점이 Reparameterization Trick의 가장 큰 장점이다. 즉, 무작위값 는 역전파(Backpropagation) 시 상수로 취급된다. 이로써 는 미분이 가능하다.
[23] [22]의 예시는 우리가 원하는 상황과 조금 다르다. 우리는 Multivariate Gaussian Distribution으로부터 Sampling 하는 상황이며, 이는 일변수와는 조금 다르다.
Multivariate Gaussian Distribution에서의 Sampling 하는 방법은 이곳에서 확인할 수 있다. 조금 복잡해진 점은, 인 행렬 를 찾아야 한다는 것이다.
원래의 목적을 생각해보자. Multivariate Gaussian Distribution 로부터 latent vector 를 Sampling 할 것인데, 미분가능성을 생각하여 Reparameterization Trick을 이용할 것이다.
이곳에 따르면 로부터 Sampling 한 값 는 로 표현된다.
는 를 만족하는 행렬, , 각 는 에서 독립추출한 값
라 하자. 에 루트를 씌운 느낌이다. 이때 이므로
으로 조건을 만족한다. 따라서
이다.
Architecture에는 에서 를 Sampling 한다고 하였는데, 이것이 위 식의 과 같을까? 이것 역시 위의 방법대로 인 라 할 수 있다를 찾는다면 어렵지 않게 에서 번 독립추출한 값을 이어붙이는 것과 에서 하나의 벡터를 Sampling 하는 것이 같음을 알 수 있다.
[24] 사실 당연한 결과이다. 가 에 가까워지도록 학습을 진행했기 때문이다. 이는 Loss Function에서도 Regularization Loss로 남아있다.
