<논문>
Auto-Encoding Variational Bayes
<코드>
VAE_MNIST.ipynb
이론으로 알아본 VAE를 실습해보자. 목표는 VAE 모델을 학습시켜 MNIST 이미지를 생성하는 것이다. 일련의 과정은 colab에서 진행하였다.
라이브러리 준비
필요한 라이브러리를 준비한다. PyTorch를 이용할 것이고, 데이터는 torchvision의 MNIST 데이터를 가져올 것이다.
import torch
import torch.nn as nn
import torchvision.datasets
import torchvision.transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from tqdm import tqdm시각화와 진행도 확인을 위해 각각 matplotlib.pyplot, tqdm을 가져왔다.
하이퍼파라미터 설정
하이퍼파라미터를 한 곳에서 결정할 수 있도록 딕셔너리를 정의하였다.
config = {'batch_size' : 16, 'latent_dim' : 10, 'learning_rate' : 0.00001, 'epoch' : 30}
데이터셋 준비
torchvision에서 제공하는 MNIST 데이터셋을 학습에 사용하고, MNIST 이미지를 생성할 것이다.
# 학습 디바이스 설정
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# MNIST datasets을 다운로드
train_data = torchvision.datasets.MNIST('./data', train=True, download=True, transform=torchvision.transforms.ToTensor())
# DataLoader에 데이터셋 탑재
train_dataloader = DataLoader(train_data, batch_size=config['batch_size'], shuffle=True, drop_last=True)device를 정의하여 GPU가 있다면 GPU에서 학습이 진행되도록 할 것이다. 흔히 "device에 올린다"고 표현한다.
모델 설계
VAE의 핵심인 Encoder와 Decoder를 설계하고 Loss Function을 구성하자.
# Encoder, Decoder를 각각 설계
# Encoder의 결과(mu, logvar)가 Loss Function에 사용되므로 따로 구성
class Encoder(nn.Module):
def __init__(self, x_dim=784, h1_dim=196, h2_dim=49, z_dim=config['latent_dim']):
super(Encoder, self).__init__()
# 1st hidden layer : 784 -> 196
self.fc1 = nn.Sequential(
nn.Linear(x_dim, h1_dim),
nn.ReLU()
)
# 2nd hidden layer : 196 -> 49
self.fc2 = nn.Sequential(
nn.Linear(h1_dim, h2_dim),
nn.ReLU()
)
# output layer : 49 -> 10
self.mu = nn.Linear(h2_dim, z_dim)
self.logvar = nn.Linear(h2_dim, z_dim)
# Reparameterization Trick을 위한 함수수
def reparameterization(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
mu = self.mu(x)
logvar = self.logvar(x)
z = self.reparameterization(mu, logvar)
return z, mu, logvar
class Decoder(nn.Module):
def __init__(self, x_dim=784, h1_dim=196, h2_dim=49, z_dim=config['latent_dim']):
super(Decoder, self).__init__()
# 1st hidden layer : 10 -> 49
self.fc1 = nn.Sequential(
nn.Linear(z_dim, h2_dim),
nn.ReLU()
)
# 2nd hidden layer : 49 -> 196
self.fc2 = nn.Sequential(
nn.Linear(h2_dim, h1_dim),
nn.ReLU()
)
# output layer : 196 -> 784
self.fc3 = nn.Linear(h1_dim, x_dim)
# 0~1의 값을 도출하기 위해 Sigmoid를 추가
def forward(self, z):
z = self.fc1(z)
z = self.fc2(z)
z = self.fc3(z)
pred = nn.Sigmoid()(z)
return pred이론에서 다룬 부분과 차이가 있는 부분은, Encoder에서 를 추출하는 대신 (=logvar)를 추출하였다.
- logvar는 마지막으로 nn.Linear를 거친 뒤 나온다. 즉, logvar 벡터는 양수뿐만 아니라 0과 음수도 가질 수 있다. 하지만 표준편차는 항상 양수여야 한다. 그렇다고 nn.ReLU와 같은 함수를 걸어준다면 값이 왜곡될 것이다.
- 이것의 해결책으로, 대신 를 추출하는 것이다. 가 양수이므로 는 양수만을 정의역으로 가지고, 치역은 실수 전체이므로 nn.Linear를 거친 뒤 음수값을 갖더라도 문제되지 않는다.
- 정리하면, 양수가 아닌 값을 갖는 문제를 해결하기 위해 변환된 표준편차값을 추출한 셈 치겠다고 볼 수 있고, 엄밀하게 말하면 실수 전체를 치역으로 갖는 일대일 함수의 함수값으로 보고, 역함수로부터 본래 값(=표준편차)을 구하겠다고 볼 수 있다. [1]
mu와 logvar를 추출할 때, 위 코드와 같이 각각의 nn.Linear를 두는 방법이 있고, out_channel이 2배인 nn.Linear 하나를 두고 결과를 반으로 쪼개어 사용하는 방법도 있다.
Optimizer 설계
두 모델의 파라미터를 모아 Optimizer에 넘겨주고, learning_rate를 넘겨주자.
# Encoder, Decoder를 생성하고 device에 올리기
encoder = Encoder().to(device)
decoder = Decoder().to(device)
# 모델 파라미터, Learning rate를 기반으로 Optimizer 정의
parameters = list(encoder.parameters()) + list(decoder.parameters())
optimizer = torch.optim.Adam(parameters, lr=config['learning_rate'])
모델 학습
Encoder와 Decoder로 Forward를 구성하고, loss를 계산하고 미분, 학습하여 Backward를 구성하자.
# 이미지의 label은 사용되지 않는다
for epoch in tqdm(range(config['epoch'])):
for i, (x, _) in enumerate(train_dataloader):
# Forward
input = x.view(config['batch_size'], -1).to(device)
z, mu, logvar = encoder(input)
output = decoder(z)
# Reconstruction loss, Regularization loss 계산
reconst_loss = nn.BCELoss(reduction='sum')(output, input)
regular_loss = 0.5 * torch.sum(mu**2 + torch.exp(logvar) - logvar - 1)
# Backward
loss = reconst_loss + regular_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f" Loss : {loss}")위 모델은 label이 사용되지 않는다. 또한 생성모델이므로 성능을 측정하는 valid dataset이 필요없다. 학습이 진행되고 있는지를 loss의 변화로 확인하자.
모델 Inference
# N(0, 1)에서 반복추출하여 latent vector z를 Sampling
# check_num_image : Inference 하고자 하는 이미지 수
check_num_image = 10
z = torch.randn(check_num_image, config['latent_dim']).to(device)
sampled_images = decoder(z).view(check_num_image, 28, 28)
# Inference 결과 시각화
fig = plt.figure(figsize=(10, (check_num_image//2)))
for idx, img in enumerate(sampled_images):
ax = fig.add_subplot(2, check_num_image//2, idx+1)
img = img.detach().numpy()
ax.imshow(img, cmap='gray')다음은 Inference 결과를 시각화한 것이다.
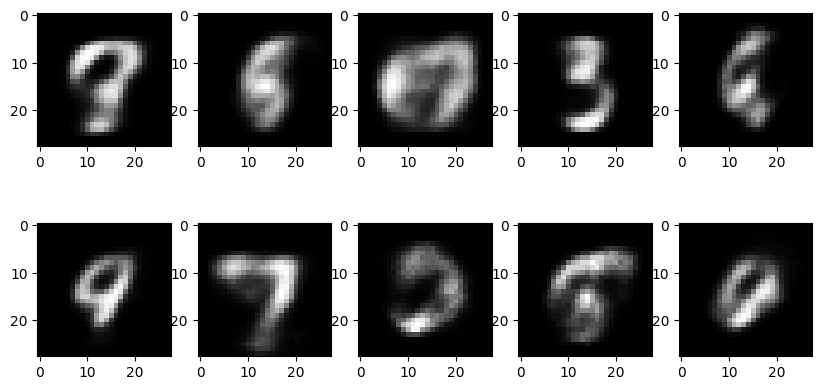
숫자처럼 보이는 이미지도 있고, 그렇지 않은 것도 있다. Encoder에서 특징을 잘 추출할 수 있다면 더 좋은 이미지를 얻을 수 있을 것이다. 또한 이미지 화질이 낮은데, 이는 VAE의 단점으로 지적된다.
전체 코드는 다음과 같다.
"""
# VAE 코드구현
## 1. 사전준비
### 1-1. 필요한 라이브러리 불러오기
"""
import torch
import torch.nn as nn
import torchvision.datasets
import torchvision.transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from tqdm import tqdm
"""### 1-2. 하이퍼파라미터 정의"""
config = {'batch_size' : 16, 'latent_dim' : 10, 'learning_rate' : 0.00001, 'epoch' : 30}
"""## 2. 데이터 불러오기"""
# 학습 디바이스 설정
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# MNIST datasets을 다운로드
train_data = torchvision.datasets.MNIST('./data', train=True, download=True, transform=torchvision.transforms.ToTensor())
# DataLoader에 데이터셋 탑재
train_dataloader = DataLoader(train_data, batch_size=config['batch_size'], shuffle=True, drop_last=True)
"""## 3. 모델 설계
### 3-1. Encoder, Decoder 설계
"""
# Encoder, Decoder를 각각 설계
# Encoder의 결과(mu, logvar)가 Loss Function에 사용되므로 따로 구성
class Encoder(nn.Module):
def __init__(self, x_dim=784, h1_dim=196, h2_dim=49, z_dim=config['latent_dim']):
super(Encoder, self).__init__()
# 1st hidden layer : 784 -> 196
self.fc1 = nn.Sequential(
nn.Linear(x_dim, h1_dim),
nn.ReLU()
)
# 2nd hidden layer : 196 -> 49
self.fc2 = nn.Sequential(
nn.Linear(h1_dim, h2_dim),
nn.ReLU()
)
# output layer : 49 -> 10
self.mu = nn.Linear(h2_dim, z_dim)
self.logvar = nn.Linear(h2_dim, z_dim)
# Reparameterization Trick을 위한 함수수
def reparameterization(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
mu = self.mu(x)
logvar = self.logvar(x)
z = self.reparameterization(mu, logvar)
return z, mu, logvar
class Decoder(nn.Module):
def __init__(self, x_dim=784, h1_dim=196, h2_dim=49, z_dim=config['latent_dim']):
super(Decoder, self).__init__()
# 1st hidden layer : 10 -> 49
self.fc1 = nn.Sequential(
nn.Linear(z_dim, h2_dim),
nn.ReLU()
)
# 2nd hidden layer : 49 -> 196
self.fc2 = nn.Sequential(
nn.Linear(h2_dim, h1_dim),
nn.ReLU()
)
# output layer : 196 -> 784
self.fc3 = nn.Linear(h1_dim, x_dim)
# 0~1의 값을 도출하기 위해 Sigmoid를 추가
def forward(self, z):
z = self.fc1(z)
z = self.fc2(z)
z = self.fc3(z)
pred = nn.Sigmoid()(z)
return pred
"""### 3-2. Optimizer 설계"""
# Encoder, Decoder를 생성하고 device에 올리기
encoder = Encoder().to(device)
decoder = Decoder().to(device)
# 모델 파라미터, Learning rate를 기반으로 Optimizer 정의
parameters = list(encoder.parameters()) + list(decoder.parameters())
optimizer = torch.optim.Adam(parameters, lr=config['learning_rate'])
"""## 4. 모델 학습"""
# 이미지의 label은 사용되지 않는다
for epoch in tqdm(range(config['epoch'])):
for i, (x, _) in enumerate(train_dataloader):
# Forward
input = x.view(config['batch_size'], -1).to(device)
z, mu, logvar = encoder(input)
output = decoder(z)
# Reconstruction loss, Regularization loss 계산
reconst_loss = nn.BCELoss(reduction='sum')(output, input)
regular_loss = 0.5 * torch.sum(mu**2 + torch.exp(logvar) - logvar - 1)
# backprop and optimize
loss = reconst_loss + regular_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f" Loss : {loss}")
"""## 5. 모델 Inference"""
# N(0, 1)에서 반복추출하여 latent vector z를 Sampling
check_num_image = 10
z = torch.randn(check_num_image, config['latent_dim']).to(device)
sampled_images = decoder(z).view(check_num_image, 28, 28)
# Inference 결과 시각화
fig = plt.figure(figsize=(10, (check_num_image//2)))
for idx, img in enumerate(sampled_images):
ax = fig.add_subplot(2, check_num_image//2, idx+1)
img = img.detach().numpy()
ax.imshow(img, cmap='gray')[1] 일대일 함수가 아니면 불가능하다. 즉, 가 일대일 함수이므로 역함수가 존재하고 , logvar에 역함수를 취함으로서 를 얻을 수 있다.
코드에서는 self.reparameterization에서 위 과정을 살펴볼 수 있다. 를 얻기 위해 torch.exp(0.5*logvar)를 하는 코드를 찾을 수 있다.
