0. 학습목표
- 트랜잭션에 대해서 설명할 수 있다.
- ACID에 대해서 설명할 수 있다.
- SQL 다중 테이블 쿼리를 날릴 수 있다.
- GROUP BY를 사용할 수 있다.
1. 주요개념
1. 트랜잭션(Transaction)
DatabaseTransaction은 통상적으로 데이터베이스의 상태를 변화시키기 위한 작업 수행의 논리적 단위를 의미한다. 이때 작업 수행의 논리적 단위란 데이터베이스의 무결성이 보장된 상태에서 요청된 작업을 완수하기 위한 작업의 기본 단위로 간주한다.
간단하게 정리하면 "데이터베이스의 상태를 변화시키는 작업의 모음"이라고 할 수 있다.

위는 트랜잭션의 한 예시로 5개의 작업 중 하나라도 실패한다면 이 트랜잭션은 실행되어서는 안된다. 이는 추후에 다룰 ACID라는 개념과 이어진다.
2. ACID
💡 ACID
- Atomicity(원자성)
- Consistency(일관성)
- Isolation(고립성)
- Durability(지속성)
ACID 는 Atomicity, Consistency, Isolation, Durability 를 가리킨다. 각 단어는 데이터베이스 내에서 일어나는 하나의 트랜잭션(transaction)이 보장하는(보장해야하는) 성질이다.
이는 트랜잭션이 안전하게 수행된다는 것을 보장하기 위한 성질이기도 하다. 대체로 DBMS에서 이를 만족하도록 강제한다.
말이 헷갈리는 것 같아서 다시 정리하면, ACID는 안전하게 수행된 트랜잭션이 보장하는 성질이자, 트랜잭션이 안전하게 수행되기 위해서 만족해야하는 성질이다. 이제 각각의 성질에 대해서 자세히 알아보면 다음과 같다.
2-1. Atomicity(원자성)
원자성은 트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는 능력이다.
위의 예시를 다시 살펴보자. 만일 3번까지 정상적으로 작업이 처리되었는데 돈을 보내고자 하는 B의 통장이 거래 중지상태라고 가정해보자. 만일 여기서 원자성이 보장되지 않는다면 A의 100만원은 출금되었지만 그 어디에도 존재하지 않는 상태가 된다.
원자성은 이와 같이 중간단계까지 실행되고 실패하는 일이 없도록 하는 것이다.
2-2. Consistency(일관성)
일관성은 모든 규칙과 제약 조건을 따르는 유효한 데이터만 데이터베이스에 기록되도록 하는 속성이다. 트랜잭션 결과 유효하지 않은 데이터가 발생하면 데이터베이스는 모든 관례적인 규칙과 제약 조건을 준수하는 이전 상태로 되돌아간다.
이 일관성은 데이터무결성을 유지하는데 중요하다. 모든 불일치 데이터는 삭제되고 불일치를 유발할 수 있는 모든 트랜잭션은 중단되어 오류를 생성하거나 오류 로그에 기록을 남긴다. 여기서 불일치란 관례적인 규칙과 제약에 일치하지 않음을 의미한다.
예를 들어 통장잔고가 마이너스가 될 수 없다고 할 때 위의 예시에서 A가 100만원을 뽑으려 한다면 제약조건에 맞지 않아서 돈을 출금하지 못하게 되고 따라서 트랜잭션은 중지된다.
2-3. Isolation(고립성)
이는 각 트랜잭션이 고립되어 다른 트랜잭션의 영향을 받지 않도록 보장하는 속성이다. 이는 트랜잭션이 상호간의 간섭없이 동시에 안전하고 독립적으로 처리되도록 보장하지만 트랜잭션의 순서를 보장하지 않는다.
이 특성은 성능관련 이유로 인해서 가장 유연성 있는 제약 조건이라고 한다.
예를 들어 사용자 A와 B가 Z라는 계좌에서 돈을 인출한다고 하자. A, B 모두 Z에서 인출되기 때문에 사용자 중 한 명은 다른 사용자의 트랜잭션이 완료될 때까지 기다려야(=고립성) 일관성 없는 데이터를 피할 수 있다.
2-4. Durability(지속성)
지속성은 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함을 의미한다. 시스템 문제, DB 일관성 체크 등을 하더라도 유지되어야 함을 의미한다. 전형적으로 모든 트랜잭션은 로그로 남고 시스템 장애 발생 전 상태로 되돌릴 수 있다. 트랜잭션은 로그에 모든 것이 저장된 후에만 Commit상태로 간주될 수 있다.
💡 Commit
모든 작업을 정상적으로 처리하겠다고 확정하는 명령어로, 트랜잭션의 처리과정을 데이터베이스에 반영하기 위해서, 변경된 내용을 모두 영구 저장한다.(지속성)
COMMIT을 수행하면, 하나의 트랜잭션 과정이 종료되게 된다. 따라서 이전 데이터가 완전히 UPDATE된다. 그리고 이러한 변경 데이터를 확인할 수 있다.
3. Query문 실행 순서
❗ 실행 순서
FROM👉ON👉JOIN👉WHERE👉GROUP BY👉CUBE|ROLLUP
👉HAVING👉SELECT👉DISTINCT👉ORDER BY👉TOP
SQL은 문법 순서와 실행 순서가 다르다. 따라서 Query문을 작성함에 있어서 실행순서를 알고 있으면 Query문을 작성하고 이해함에 있어서 도움이 될 수 있다.
4. SUBQUERY
하나의 SQL문에 포함되어 있는 또 다른 SQL문을 의미한다. 서브쿼리는 알려지지 않은 기준을 이용한 검색을 위해서 사용한다.
서브쿼리는 메인쿼리의 Column을 모두 사용할 수 있지만, 반대로 메인쿼리는 서브쿼리에서 불러온 Column을 사용할 수 없다. 따라서 서브쿼리에서 불러온 테이블의 Column을 표시해야 한다면 조인 방식으로 변환하거나 함수, 스칼라 서브쿼리 등을 사용해야 한다.
서브쿼리를 사용할 때는 다음 사항을 주의해야 한다.
❗ 주의사항
1. 서브쿼리를 괄호로 감싸서 사용한다.
2. 서브쿼리는 단일 행(Single Row) 또는 복수 행(Multiple Row)비교 연산자와 함께 사용 가능하다. 단일 행 비교 연산자(<,>,=,<=,...)는 서브쿼리의 결과가 반드시 1건 이하이어여 하고 복수 행 비교 연산자(IN,ALL,ANY,...)는 서브쿼리의 결과 건수와 상관없다.
3. 서브쿼리에서는ORDER BY를 사용하지 못한다.ORDER BY절은SELECT절에서 오직 한 개만 올 수 있기 때문에ORDER BY절은 메인쿼리의 마지막 문장에 위치해야 한다.
서브쿼리의 논리적 실행순서는 항상 메인쿼리에서 읽혀진 데이터에 대해 서브쿼리에서 해당 조건이 만족하는지를 확인하는 방식으로 수행된다. 하지만 실제 서브쿼리의 실행순서는 상황에 따라서 달라질 수 있다.
또한 반환되는 데이터의 형태에 따라서 서브쿼리를 분류할 수 있다.
💡 서브쿼리 분류
1. Single Row 서브쿼리(단일 행 서브쿼리)
서브쿼리의 실행 결과가 항상 1건 이하인 서브쿼리를 의미한다.
2. Multi Row 서브쿼리(다중 행 서브쿼리)
서브쿼리의 실행 결과가 여러 건인 서브쿼리를 의미한다.
3. Multi Column 서브쿼리(다중 컬럼 서브쿼리)
서브쿼리의 실행 결과로 여러 칼럼을 반환한다. 메인쿼리의 조건절에 여러 칼럼을 동시에 비교할 수 있다. 서브쿼리와 메인쿼리에서 비교하고자 하는 칼럼 개수와 칼럼의 위치가 동일해야 한다.
5. 데이터 무결성
데이터베이스에 저장된 데이터의 정확성,일관성,유효성을 지키는 것이다. 보통 데이터 무결성은 제약조건으로 데이터베이스 시스템이 강제한다.
❗ 정확성
데이터는 모델링하려는 실제 개체 및 이벤트를 반영한다. 정확성은 주로 값이 올바른 것으로 알려진 정보 소스와 얼마나 일치하는지에 따라 측정된다.
❗ 유효성
데이터는 정의된 비지니스 규칙을 준수하며 해당 규칙이 적용될 때 허용되는 매개 변수 내에 속한다.
여기서 제약조건이란 데이터베이스의 정확성, 일관성을 보장하기 위해 저장, 삭제, 수정 등을 제약하기 위한 조건을 의미한다. 주된 목적은 데이터베이스에 저장된 데이터의 무결성을 보장하고, 데이터베이스의 상태를 일관되게 유지하는 것이다.
제약조건의 장점으로는 스키마를 작성할 때 한 번만 제약조건을 명시하면, 데이터베이스가 갱신될 때마다 DBMS가 자동으로 제약조건을 검사하므로 어플리케이션들은 제약조건을 일일이 검사할 필요가 없다. 또한 제약조건을 사용하면 데이터를 실생활의 의미에 맞게 사용할 수 있으며, 응용 프로그램에서 직접 조건을 유지하는 경우보다 에러가 발생할 가능성이 더 낮다. 마지막으로는 제약조건 그 자체 덕분에 데이터에 대한 신뢰도가 올라간다.
💡 제약조건 종류
1. 개체 무결성
모든 테이블은 기본키를 가져야 하며, 기본키를 구성하는 속성으로 NOT Null과 Unique Key가 있다. 각각 NULL값이나 중복된 값을 가질 수 없다는 뜻이다.
2. 참조 무결성
참조 관계에 있는 두 테이블의 데이터가 항상 일관된 값을 갖도록 유지되어야 한다. 다시 말해, 외래키 값은 NULL이거나 참조하는 테이블의 기본키값과 동일해야 한다.
3. 도메인 무결성
테이블에 존재하는 필드의 무결성을 보장해야 하는 것으로, 데이터의 타입에 맞아야 한다.
예를 들어 '성별'이라는 속성에서 '남','여'를 제외한 데이터는 제한되어야 한다.
4. NULL 무결성
테이블의 특정 속성값을 NULL이 될 수 없도록 제한했다면 해당 속성에 NULL이 있으면 안된다.
5. 고유 무결성
테이블의 특정 속성에 대해 고유한 값(Unique Key)을 가지도록 조건이 주어진 경우, 각 레코드가 가지는 값들이 달라야 한다.
2. 명령어
1. GROUP BY와 HAVING: 그룹화 및 필터링
GROUP BY는 Pandas의 groupby()와 동일한 역할을 수행한다. 데이터를 조회하게 될 때 묶어서 조회하게 해주는 기능이다.
그리고HAVING절은 GROUP BY로 조회된 결과에 대한 필터이다. 이는 WHERE절과 적용되는 방식이 다르다. 앞서 다룬 Query실행 순서에 대해서 생각해보면 된다. WHERE절은 GROUP BY절 이전에 실행되기 때문에 그룹화 이전의 데이터 레코드를 필터한다. 따라서 GROUP BY후의 레코드에 대해서 필터기능을 추가하고 싶다면 HAVING절을 사용해야 한다.
SELECT CustomerId, AVG(Total)
FROM invoices
GROUP BY CustomerId /*CustomerId로 그룹화*/
HAVING AVG(Total) > 6.00 /*CustomerId로 그룹화된 데이터에 대한 {Total}의 평균*/2. 집계함수
2-1. COUNT(): 각 그룹에 속한 데이터의 수
말 그대로 해당 그룹에 속한 값이 몇 개인지 값을 리턴한다.
SELECT State, COUNT(*) FROM customers
GROUP BY State;2-2. SUM(): 각 그룹에 속한 데이터의 합
조회된 값들에 대한 합을 구해 리턴한다.
SELECT InvoiceId, SUM(UnitPrice)
FROM invoice_items
GROUP BY InvoiceId;2-3. AVG(): 각 그룹에 속한 데이터의 평균
조회된 값들에 대한 평균을 구해 리턴한다.
SELECT TrackId, AVG(UnitPrice)
FROM invoice_items
GROUP BY TrackId;2-4. MAX(),MIN(): 각 그룹에 속한 데이터의 최대,최소
조회된 값들에서 최대 또는 최소의 값을 반환한다.
SELECT CustomerId, MIN(Total)
FROM invoices
GROUP BY CustomerIdMIN()을 MAX()로만 바꾸면 최대값을 명시할 수 있다.
3. CASE: SQL의 IF문
정해진 조건에 따라 다른 결과를 받을 수 있으며, 조건에 따라서 GROUP화 할 수 있다.
SELECT CASE
WHEN CustomerId <= 25 THEN 'GROUP 1'
WHEN CustomerId <= 50 THEN 'GROUP 2'
ELSE 'GROUP 3'
END
FROM customers25, 50을 기준으로 총 3개의 그룹으로 나누게 된다.
4. ROW_NUMBER(): 그룹별 순서번호 부여(?)
각 PARTITION내에서 ORDER BY절에 의해 정렬된 순서를 기준으로 고유한 값을 반환하는 함수이다.
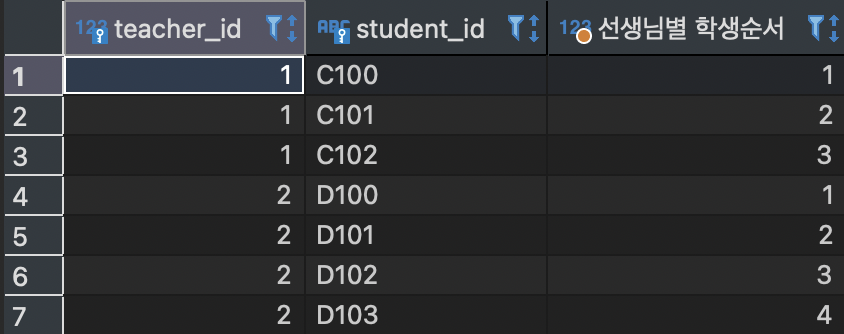
SELECT teacher_id, student_id, ROW_NUMBER () OVER(PARTITION BY teacher_id)
FROM Student;위 코드를 실행하면 아래와 같은 사진의 결과가 출력된다. 이때 컬럼명은 AS를 활용하여 사용자 마음대로 지정할 수 있다.
5. ROWID: 내부적 기본키
SQLite에서는 명시적으로 기본키를 설정하지 않거나 기본키를 설정하더라도 INTEGER자료 형이 아닌 경우에는 내부적으로 숨겨진 기본키인 ROWID를 추가한다. 이는 SELECT문으로 Query를 날릴 때 *로는 가져올 수 없고, 명시적으로 ROWID라고 지정해야 한다.
Pandas에서 Index를 지정하지 않으면 자동으로 생성되는 번호 인덱스라고 보면 편하다. 단, SQLite에서는 1번부터 시작한다.
ROWID는 _ROWID_,OID라는 별칭을 가지고 있기 때문에 어느 것을 사용해도 무방하다.
SELECT teacher_id, student_id, ROWID AS '전체 학생순서'
FROM Student;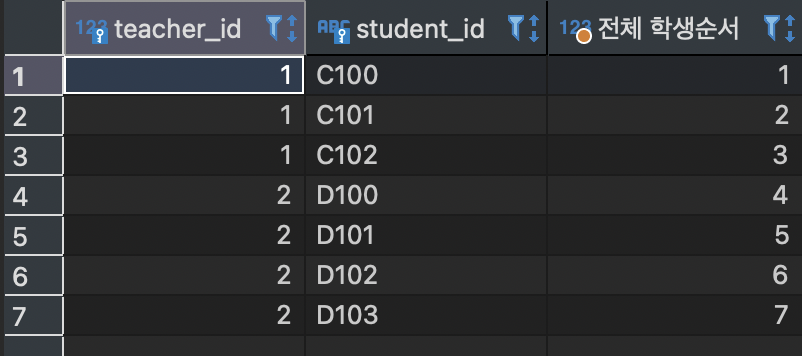
3. 회고

오늘은 그래도 8시반에 일어나서 출석하고 물론 30분 다시 드러눕기는 했지만 오랜만에 좀 제대로 된 시간에 시작한 것 같다. 프로젝트 핑계를 계속 대는 거 같은데, 진짜 프로젝트 끝나고 좀 일상루틴이 좀 많이 꼬여서 아침에 졸리고 낮에도 졸리고 밤에는 쌩쌩하게 살았는데 다시 원래대로 돌아오고 있는 거 같다.
왜인지 모르겠지만 양 자체가 많아서 그런지, 맥북 블루투스 키보드 조그만걸로 해서 그런지 과제를 수행하는데 시간이 너무 오래 걸린다. 화면이 작은 것도 한 몫하는 거 같다. 아이패드까지 더블 모니터를 써도 뭔가 답답한 느낌이다. 역시 답은 아이맥인가..
그래도 이번 섹션은 진짜 뭐를 많이 배우는 것 같아서 좋다. 근데 문제는 안알려준걸 과제에 내고 직접 찾아봐라 해서 좀 짜증이 나긴하지만 그래도 나름 만족하고 있는 중이다.
내일부터는 좀 사둔 책을 좀 보고 풀어보고 싶은데 시간이 날란가 모르겠다...
❗ 참고자료
1. 트랜잭션
2. ACID_1
3. ACID_2
4. 서브쿼리
5. 데이터 품질의 요소
6. 데이터 무결성
