부트캠프 TIL
1.[N111] TIL 및 회고

10월 7일. 드디어 오늘 개강을 했다. 첫 날이라서 OT만하고 끝나려나 했는데 아니였다. python책 안훑고 들었으면 진짜 처음부터 눈물 났을 거 같다. 그래도 pandas라이브러리는 처음 써봐서 머리가 나름 아팠다. SQL책도 끝내야하는데 그럴 시간이 있을까 의
2.[N112] TIL 및 회고
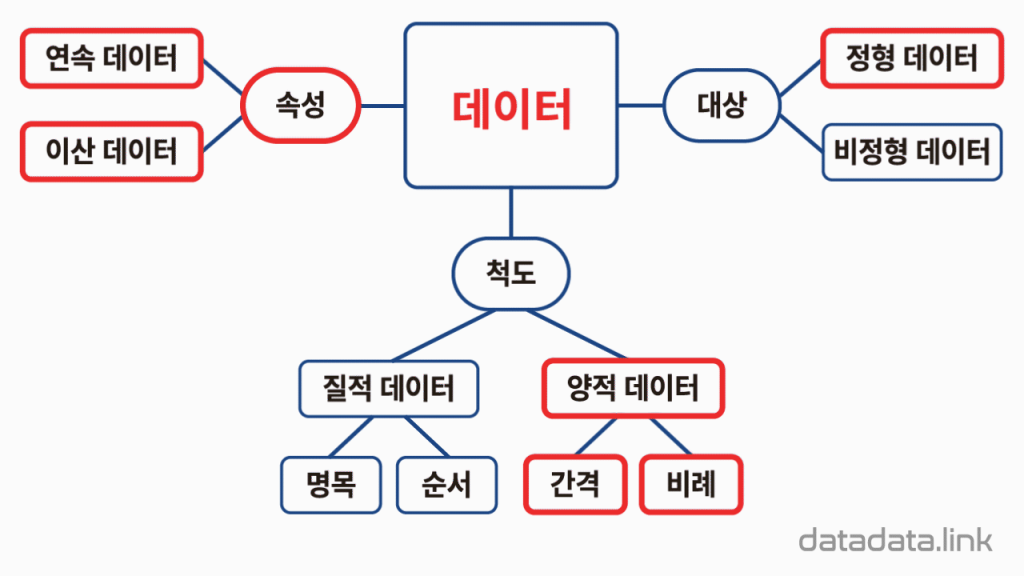
EDA에 대하여 이해한다.Feature Engineering의 목적을 이해할 수 있다.Business Insight를 도출할 수 있다.통계 및 시각화 기법을 활용할 수 있다.EDA는 exploratory Data Analysis의 약어로 탐색적 데이터 분석을 의미한다.
3.[N113] TIL 및 회고
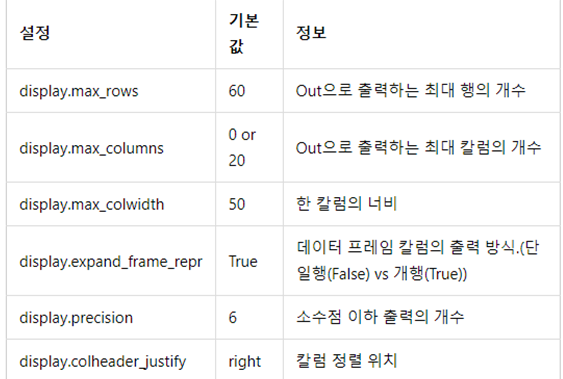
체계적인 Data Wrangling의 과정을 설명할 수 있다.
4.[N114] TIL 및 회고
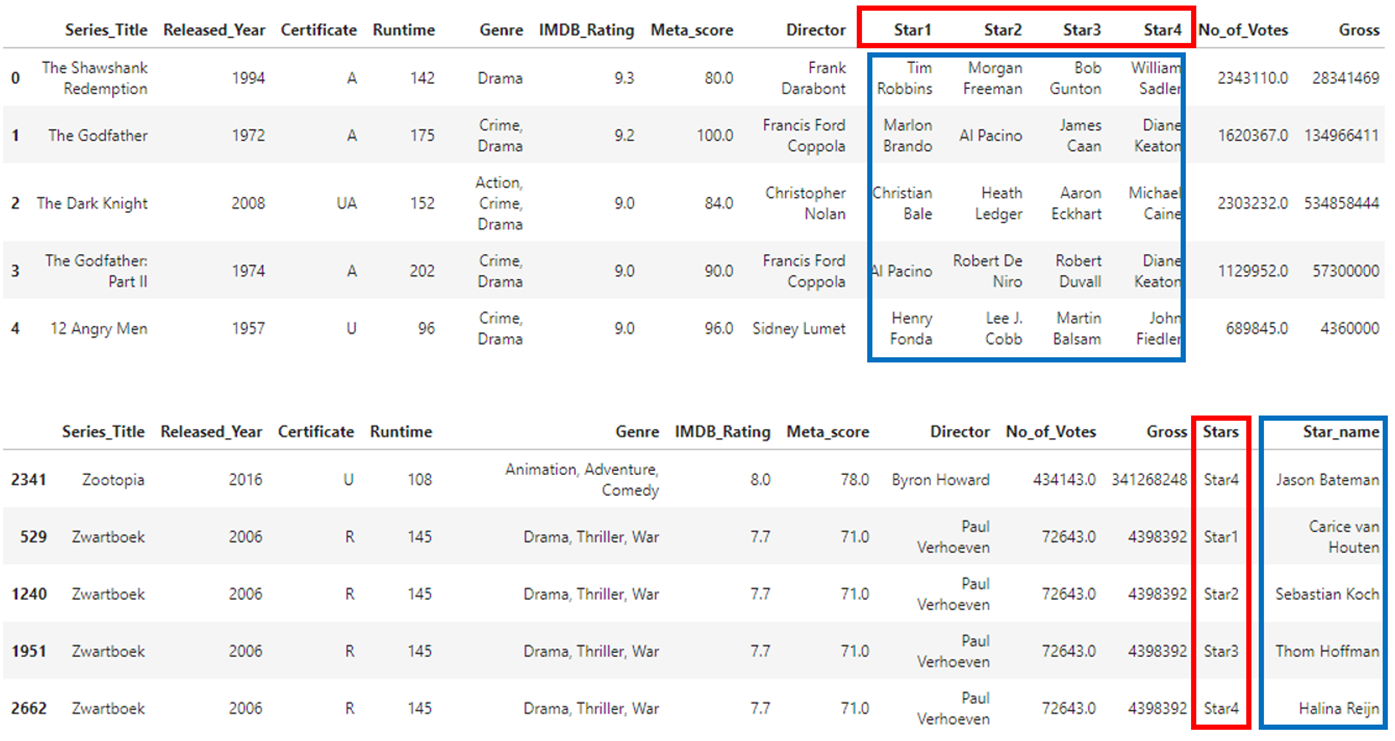
체계적인 Data Wrangling의 과정을 설명할 수 있다.데이터를 탐색해 데이터에 있는 다양한 이슈를 찾아낼 수 있다.
5.[N121] TIL 및 회고
이항 분포 (Binomial Distribution)에 대해 설명할 수 있다.조건부 확률 (Conditional Probability)에 대해 설명할 수 있다.베이지안 이론 (Bayesian Theorem)에 대해 설명할 수 있다.사건에 의해 발생한 모든 잠재적 결과들
6.[N122] TIL 및 회고
큰 수의 법칙에 대해 설명할 수 있습니다.중심 극한 정리에 대해 설명할 수 있습니다.신뢰 구간에 대해 설명 할 수 있습니다.
7.[N123] TIL 및 회고
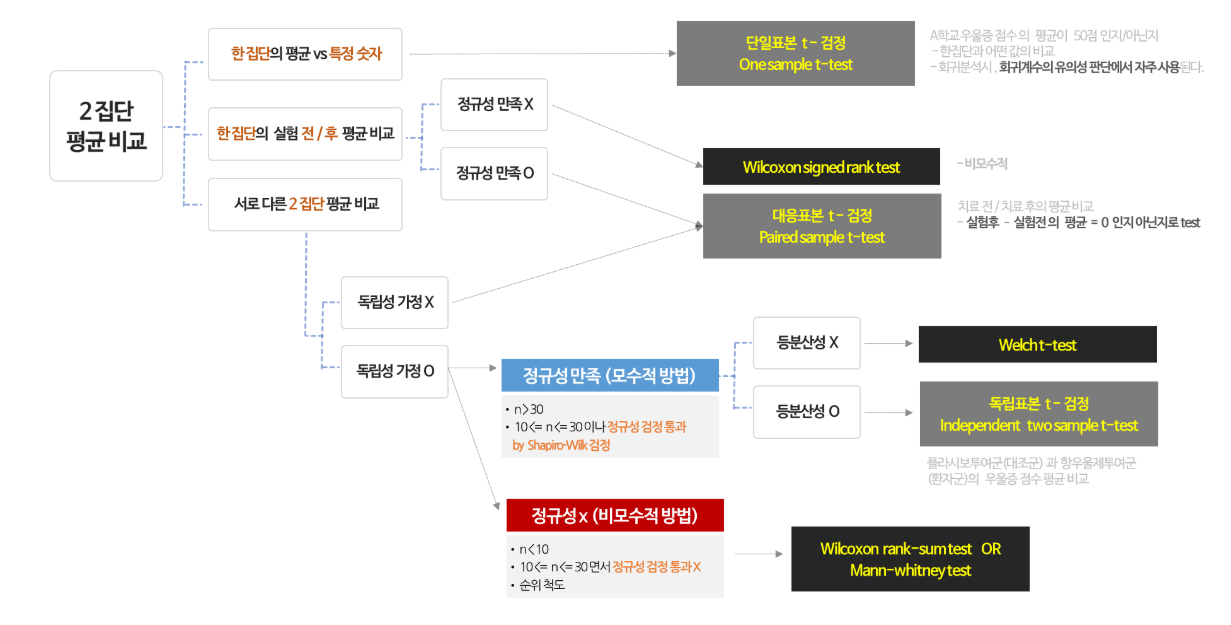
상황에 맞는 귀무가설과 대립가설을 세울 수 있다.1종 오류와 2종 오류를 설명할 수 있다.유의 수준을 이용하여 옳은 가설을 채택할
8.[N124] TIL 및 회고
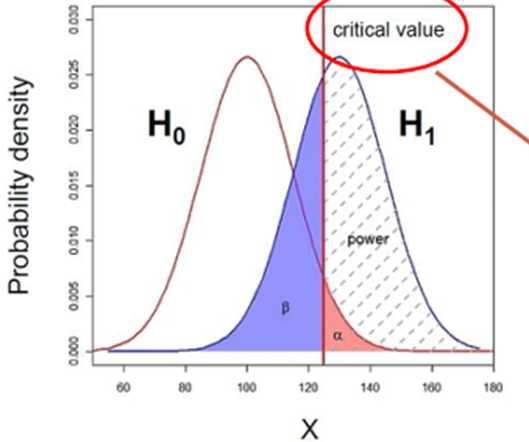
AB 테스트가 무엇인지 설명할 수 있다.주어진 데이터를 가지고 직접 AB테스트를 진행할 수 있다.
9.[N131] TIL 및 회고

Scalar, Vector, Matrix에 대해서 이해한다.Span, Basis, Rank에 대해서 이해한다
10.[N132] TIL 및 회고
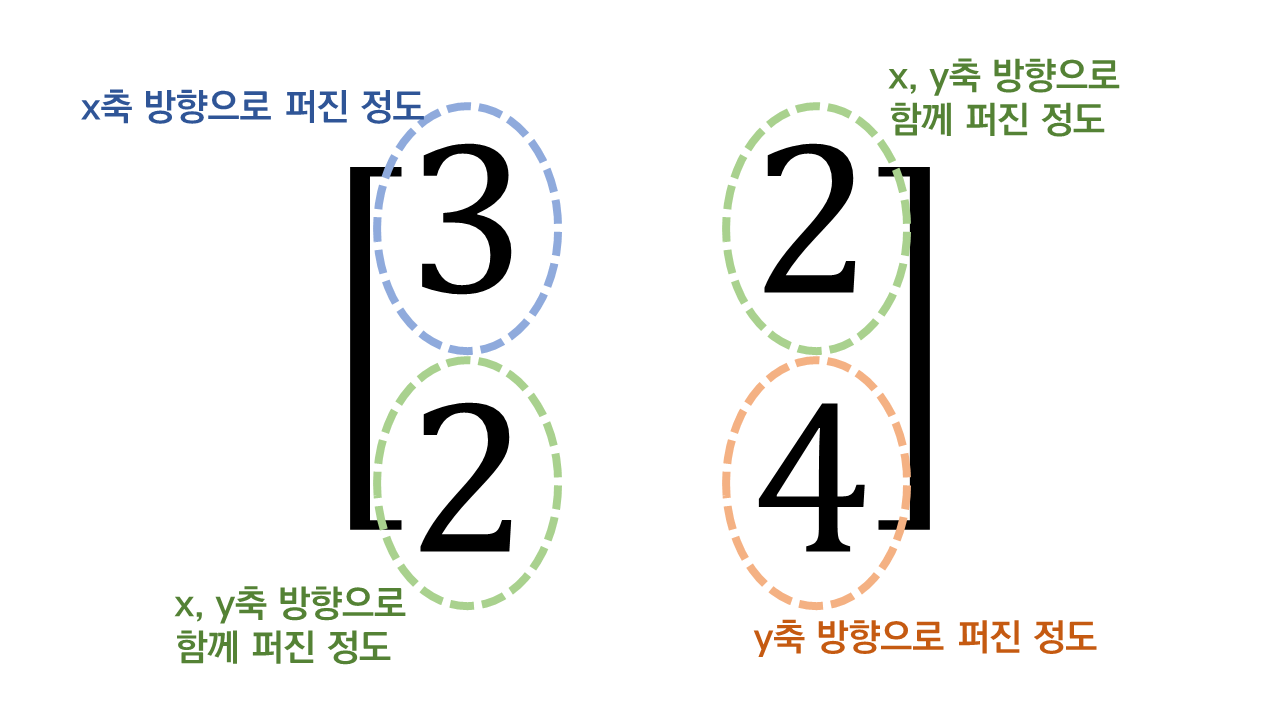
공분산, 상관계수의 목적과 차이점을 설명할 수 있다.Vector transformation에 대해서 이해한다.eigenvector / eigenvalue를 설명할 수 있다.linear projection에 대해서 이해한다.High dimensional data의 문제점
11.[N133]TIL 및 회고
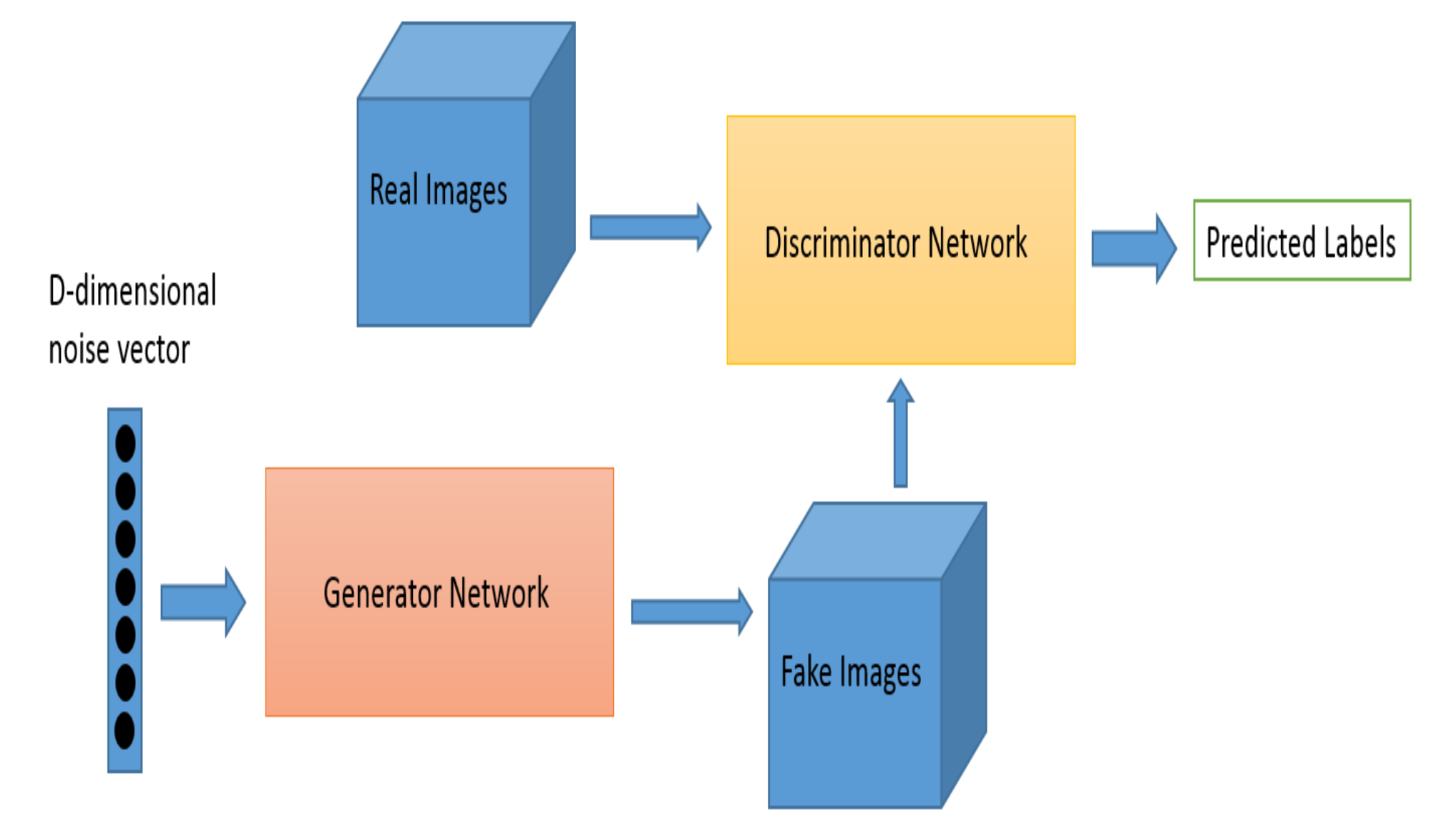
K-Means Clustering에 대해서 설명할 수 있다.RFM개념에 대해서 설명할 수 있다.Elbow method의 의미를 이해할 수 있다.지도학습은 머신러닝의 한 분야로, 데이터에서 반복적으로 학습하는 알고리즘을 사용하여 컴퓨터가 어디를 찾아봐야 하는 지를 명시적
12.[N134] TIL 및 회고
미분의 개념을 이해할 수 있다.Gradient Descent에 대해 설명할 수 있다.Linear Regression의 학습을 Gradient Descent를 이용해 설명할 수 있다.💡앞이 보이지 않는 안개가 낀 산을 내려올 때는, 모든 방향으로 산을 더듬어가며 산의
13.[N211] TIL 및 회고

정말 오랜만에 벨로그 글을 작성하는 것 같다. 지난주에 프로젝트를 진행하느라 TIL할게 없었다. 빠른 시일내로 프로젝트 진행과정이랑 리뷰 정리해서 올려야 하는데...할게 너무 많아지는 느낌이다.여하튼 이제 Section2로 들어왔다.
14.[N212] TIL 및 회고
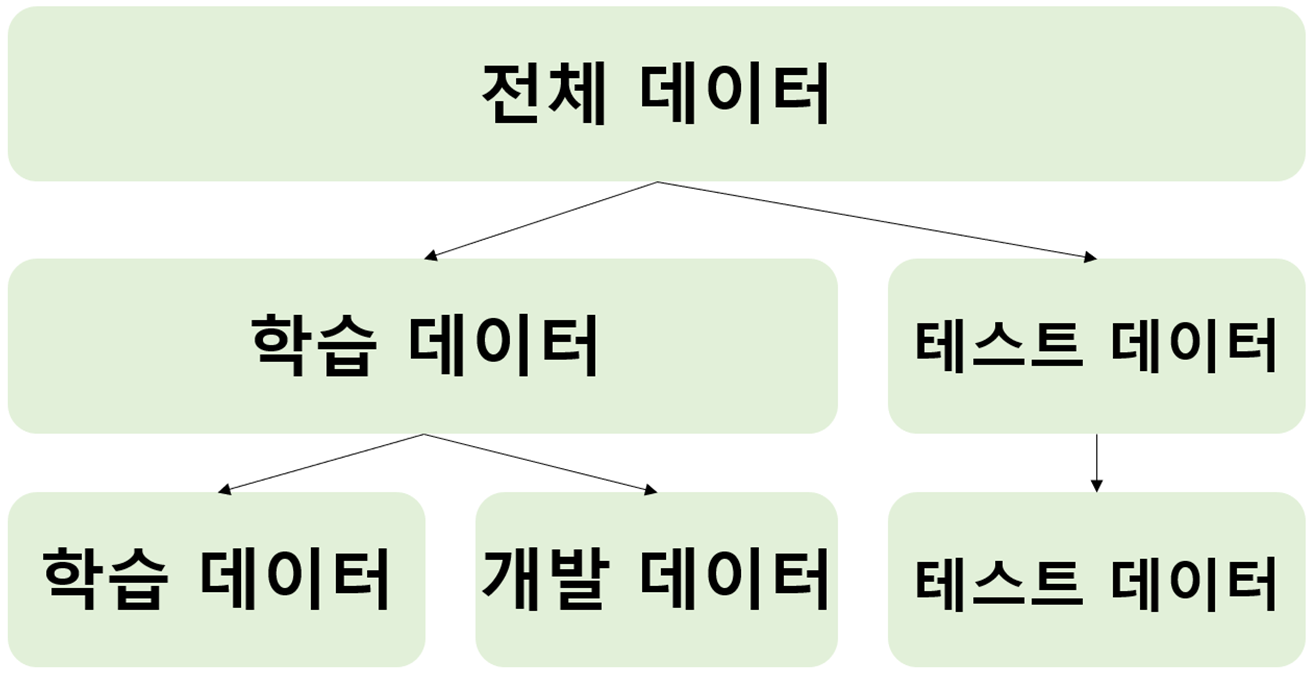
머신러닝 모델을 만들 때 학습과 Test data를 분리 해야 하는 이유를 설명할 수 있다.다중선형회귀를 이해하고 사용할 수 있다.
15.[N213] TIL 및 회고

TIL이라고 했지만, 오늘은 월요일 새벽이고 난 N213을 지난주 금요일에 배웠다. 맞다. 시원하게 놀아버렸다. 미래에 이거 읽는 나 자신은 반성하고 또 반성하길 바란다. 사실 난 오늘도 미래의 나에게 미룰거다. 오늘 아침에 눈뜨면 이거 알아서 끝내라...
16.[N214] TIL 및 회고
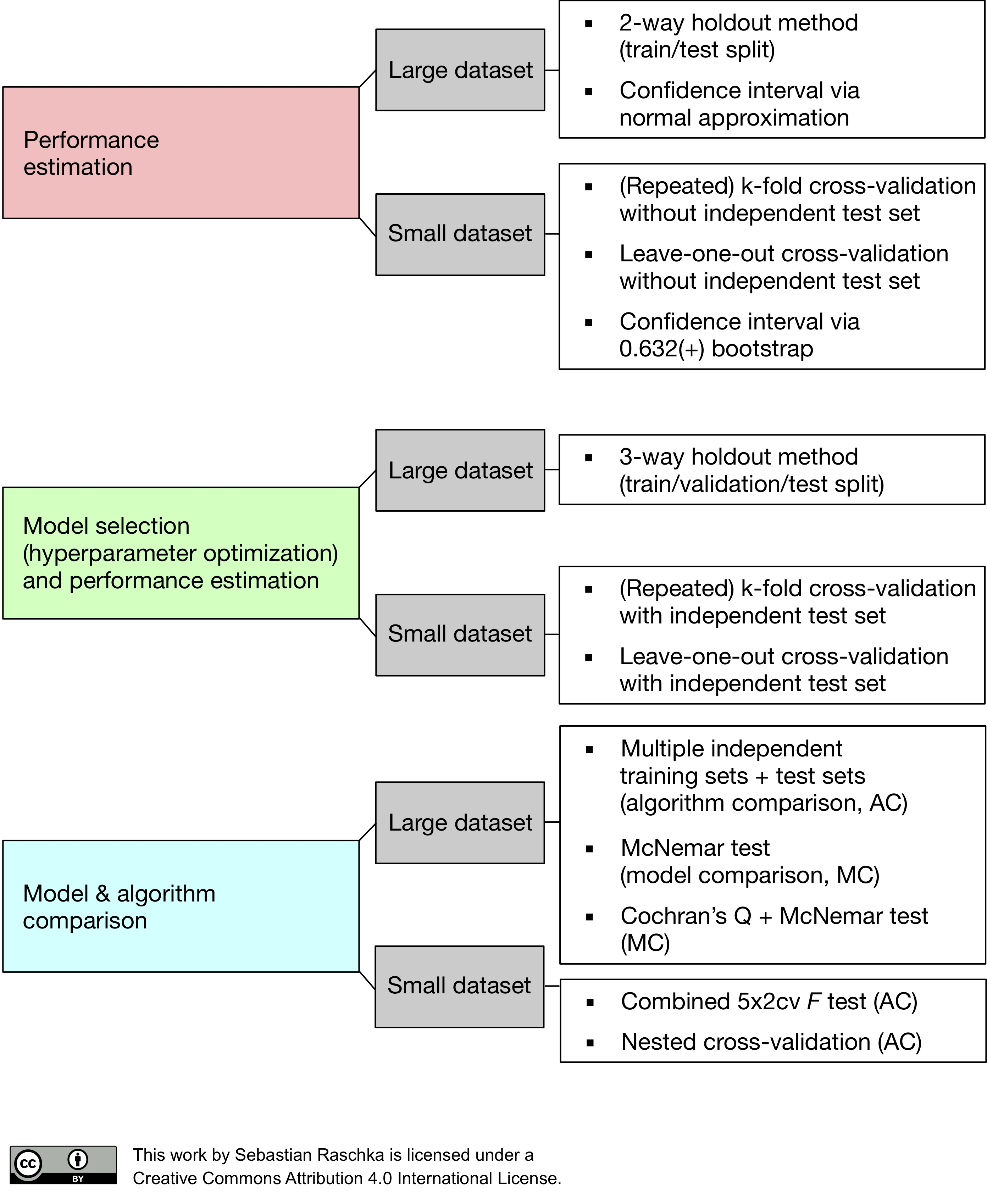
훈련/검증/테스트(train/validate/test) 데이터를 분리하는 이유를 명확히 이해하고 사용한다.분류(Classification)문제와 회귀문제의 차이점을 파악하고 문제에 맞는 모델을 사용할 수 있다.
17.[N221] TIL 및 회고
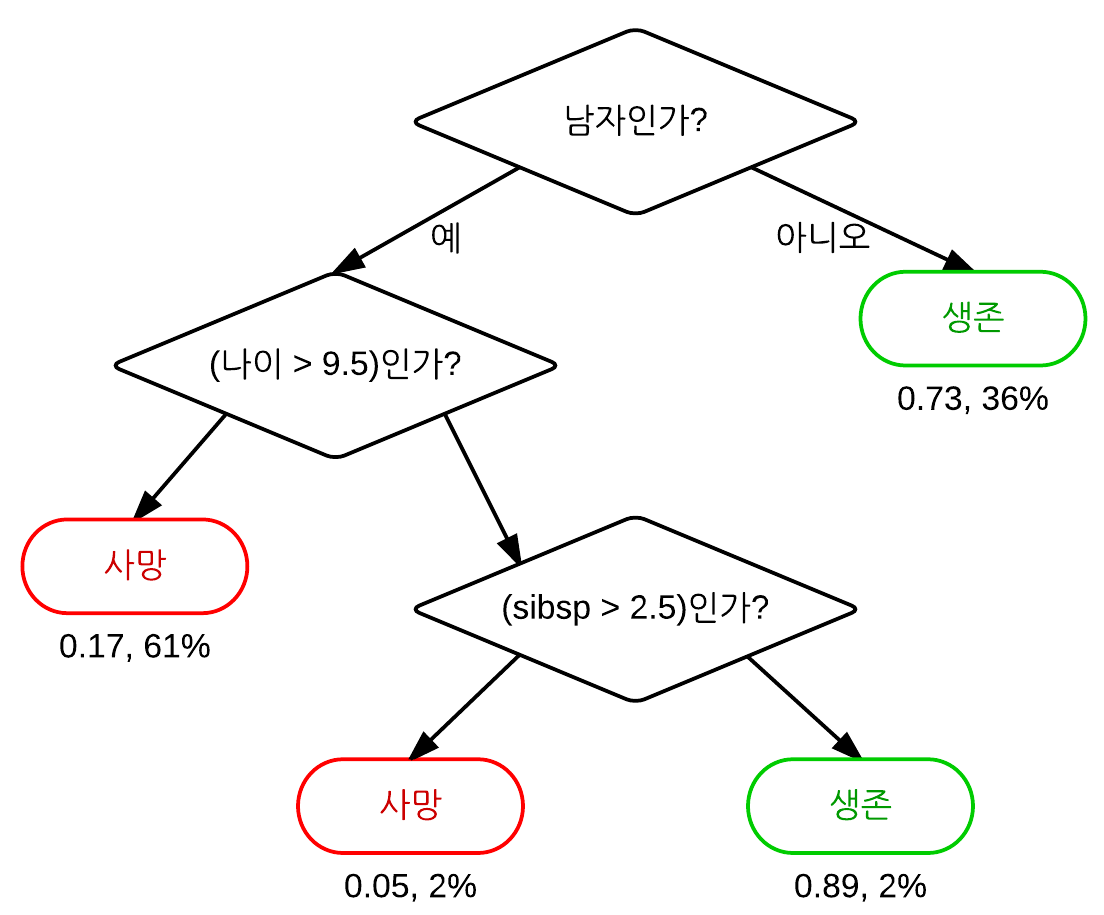
사이킷런 파이프라인(Pipelines)을 이해하고 활용 할 수 있다.사이킷런 결정트리(Decision Tree)를 사용할 수 있다.결정트리의 특성 중요도(Feature importances)를 활용할 수 있다.
18.[N222] TIL 및 회고
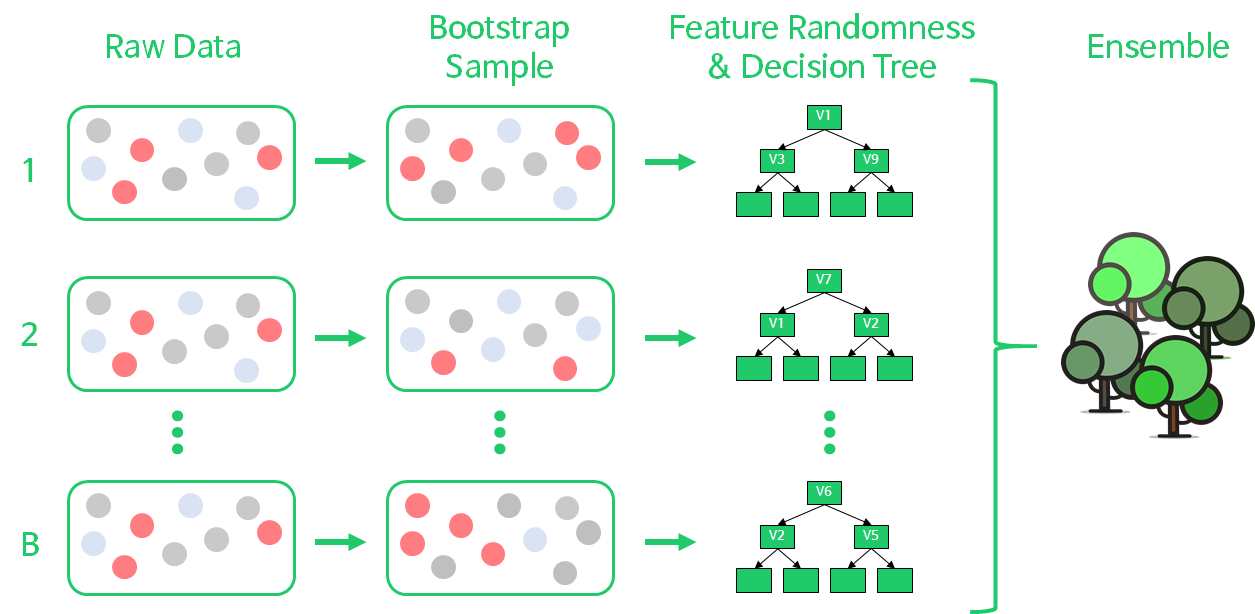
Random Forests모델을 이해하고 문제에 적용할 수 있다.순서형 인코딩(Ordinal Encoding)과 원핫인코딩(One-hot Encoding)을 구분하여 사용할 수 있다.범주형 변수의 인코딩 방법이 트리모델과 선형회귀 모델에 주는 영향을 이해한다.앙상블 학
19.[N223] TIL 및 회고
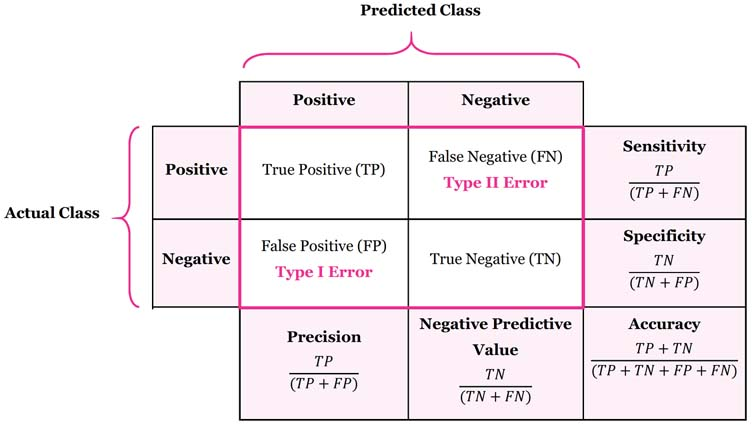
Confusin matrix를 만들고 해석할 수 있다.정밀도, 재현율을 이해하고 사용할 수 있다.ROC curve, AUC점수를 이해하고 사용할 수 있다.
20.[N224] TIL 및 회고

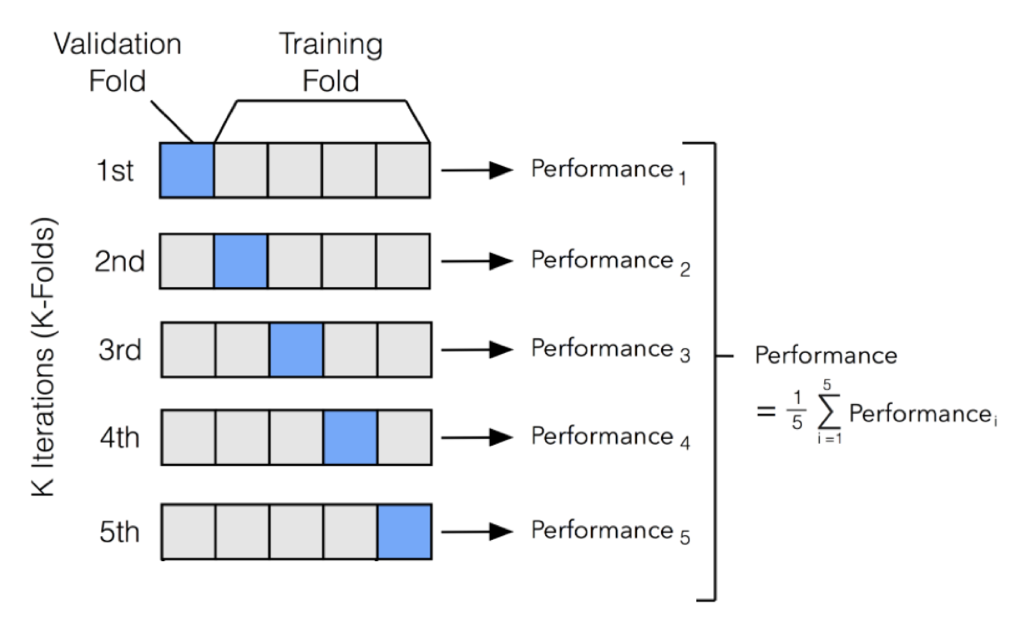
모델선택을 위한 교차검증 방법을 이해하고 활용할 수 있다.하이퍼파라미터를 최적화하여 모델의 성능을 향상시킬 수 있다.
21.[N231] TIL 및 회고
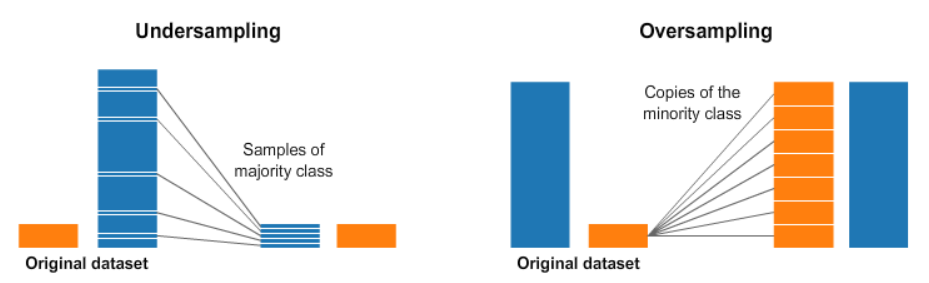
예측 모델을 위한 타겟을 올바르게 선택하고 그 분포를 확인할 수 있다.테스트/학습 데이터 사이 or 타겟과 특성들간 일어나는 정보의 누출(leakage)을 피할 수 있다.상황에 맞는 검증 지표(metrics)를 사용할 수 있다.
22.[N232] TIL 및 회고
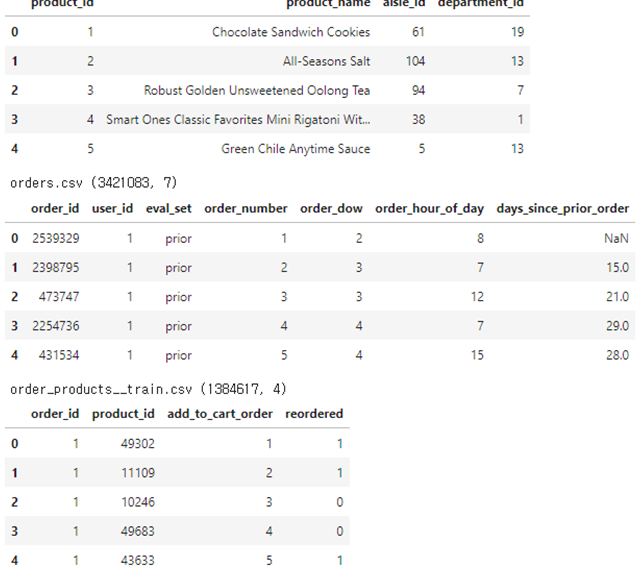
지도학습(Supervised machin learning)모델을 학습하기 위한 훈련 데이터를 생성 한다.지도학습을 위한 데이터 엔지니어링 방법을 이해하고 올바른 특성을 만들어 낼 수 있다.
23.[N233] TIL 및 회고

TIL이라 적고 3일이나 지나서 쓰는게 양심에 찔리긴 하지만 그렇다고 시리즈 이름을 바꾸기엔 좀 많이 불편해서 그대로 작성한다.
24.[N234] TIL 및 회고

이번주 월요일에 들은 수업인데 화요일 밤이 되서야 작성하고 있다. 진짜 이게 TIL이라고 할 수 있는지 나도 모르겠다. 내일부터 프로젝트만 아니였다면 더 미뤘을 거 같은데 이거 정리 끝내야 내일부터 시작하는 프로젝트 Daily정리를 할 수 있을 거 같다...
25.[N311] TIL 및 회고
터미널 등 CLI(Command-line interface,명령 줄 인터페이스)를 접근하고 활용하여 아래의 작업들을 수행할 수 있다.간단한 터미널 명령어를 이해하고 활용할 수 있다.파이썬 가상환경을 만들고 사용할 수 있다.Git을 사용해 프로젝트 관리를 할 수 있다.
26.[N312] TIL 및 회고
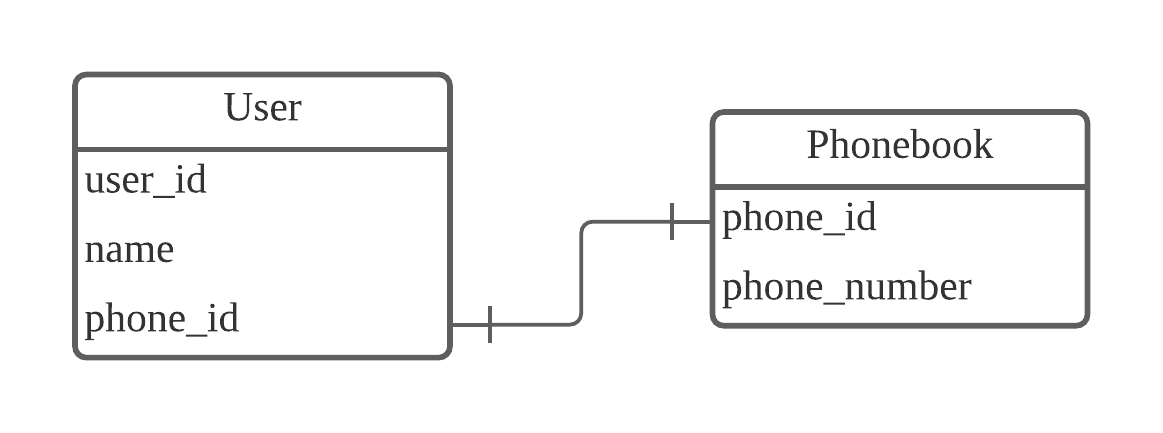
SQL 특징을 설명할 수 있다.데이터베이스 관계를 설정할 수 있다.SQL 싱글 테이블 관련 문법을 활용할 수 있다.이전에 SQL을 공부하고 정리해둔 글이 있다. 수업은 현재 SQLite기준으로 진행되고 내가 정리한 것은 MYSQL이다. 대다수가 동일하다. 다만 SQL문
27.[N313] TIL 및 회고

트랜잭션에 대해서 설명할 수 있다.ACID에 대해서 설명할 수 있다.SQL 다중 테이블 쿼리를 날릴 수 있다.GROUP BY를 사용할 수 있다.
28.[N314] TIL 및 회고
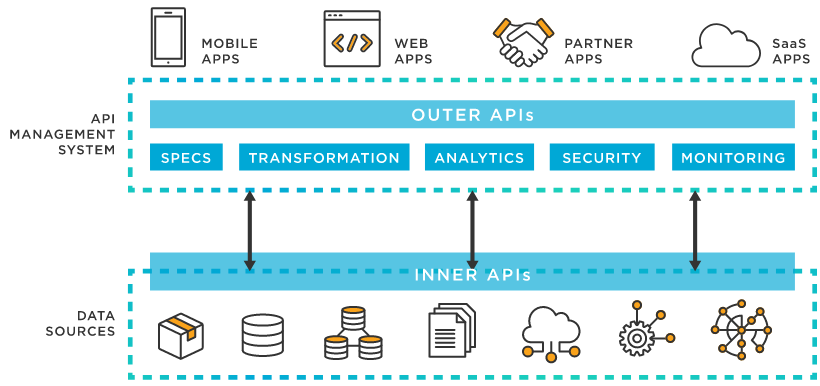
DB API를 사용하는 이유에 대해서 설명할 수 있다.DB API를 활용할 수 있다.로컬 VS 클라우드 데이터베이스에 대해서 설명할 수 있다.excutemanypragma_table_info
29.[N321] TIL 및 회고

"파이썬의 모든 요소는 객체다"
30.[N322] TIL 및 회고
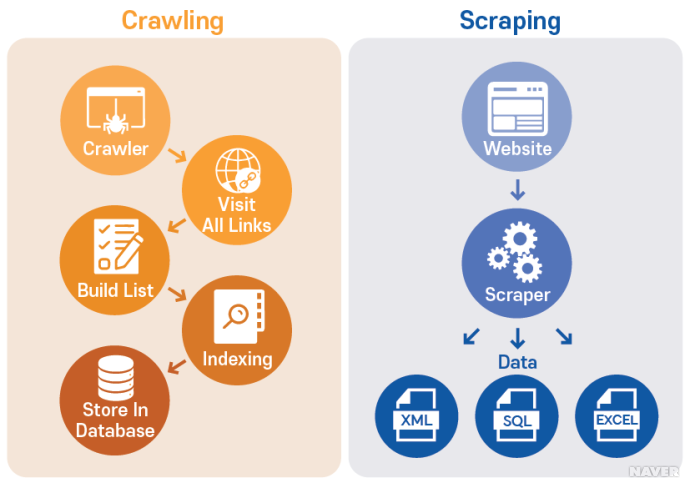
0. 학습목표
31.[N323] TIL 및 회고
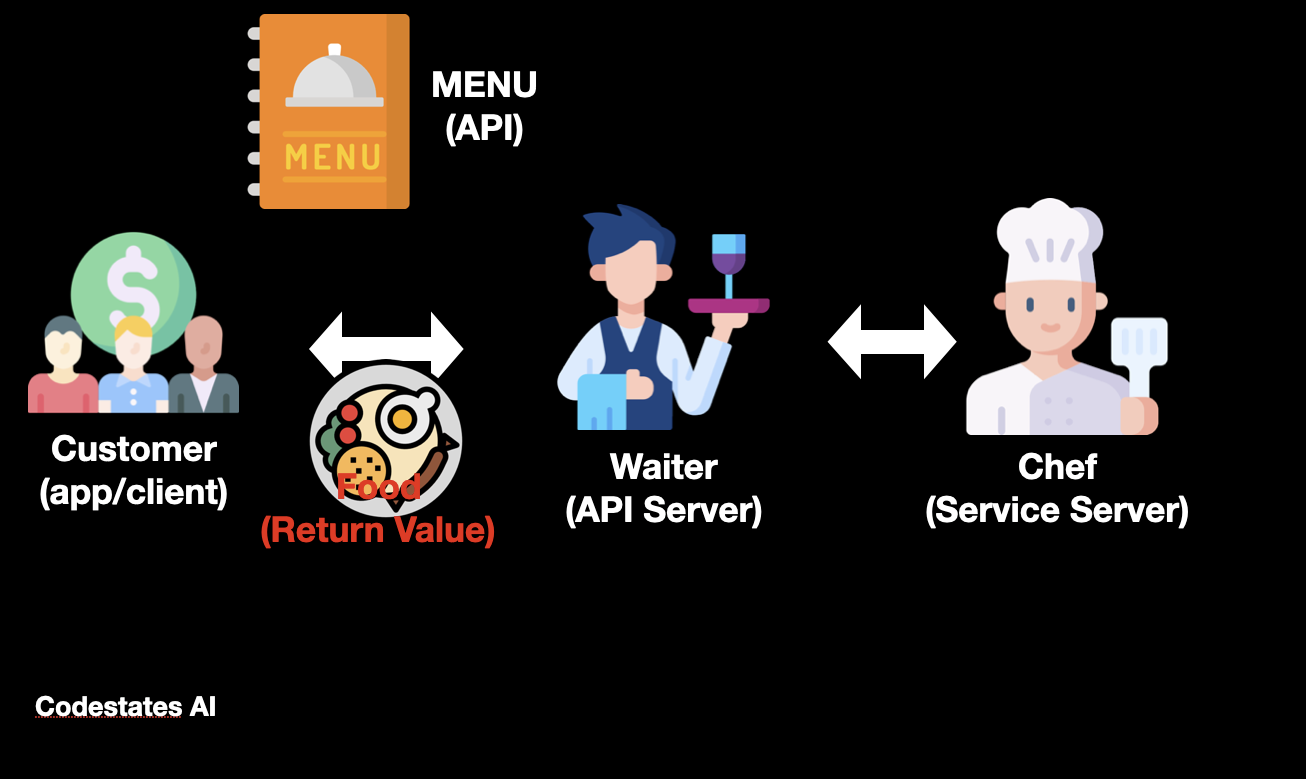
API를 이해하고 사용할 수 있어야한다.RESTful API에 대해서 설명할 수 있어야한다.API의 데이터를 받아와 데이터베이스에 저장할 수 있어야한다.
32.[N324] TIL 및 회고
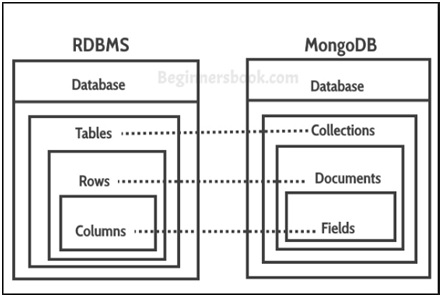
0. 학습목표 1. 주요개념 2. 회고
33.[N331] TIL 및 회고
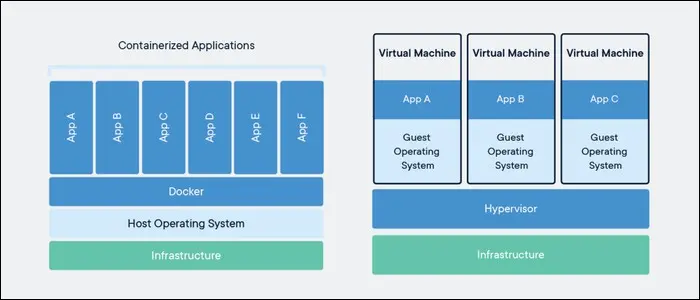
Docker에 대하여...
34.[N332] TIL 및 회고

API 와 HTTP 등 웹과 관련된 부분들을 어느 정도 배웠습니다. 이번 시간에는 직접 API 를 제공할 수 있는 웹 애플리케이션을 제작해 볼 예정입니다. 이번 노트는 총 두 개의 부분으로 나누어진 Flask 애플리케이션의 앞 부분입니다. 여기에서는 최종 목적인 웹 애
35.[N411] TIL 및 회고
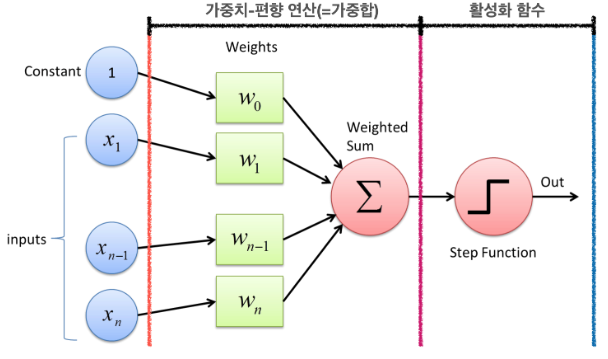
퍼셉트론(Perceptron)의 개념과 구조에 대해 설명할 수 있다.신경망을 왜 다층으로 구성해야 하는 지와 신경망 각 층(입력층, 은닉층, 출력층)의 역할에 대해 설명할 수 있다.MINIST 예제 코드를 이해하고 재현할 수 있다.
36.[N412] TIL 및 회고
0. 학습목표 Level 1. 신경망이 학습되는 메커니즘(순전파, 손실계산, 역전파)에 대해 적절한 비유를 들어 설명할 수 있다. 경사 하강법(Gradient Descent, GD)을 통해 갱신되는 과정을 대략적으로 설명할 수 있다. 옵티마이저(Optimizer)의 개
37.[N413] TIL 및 회고
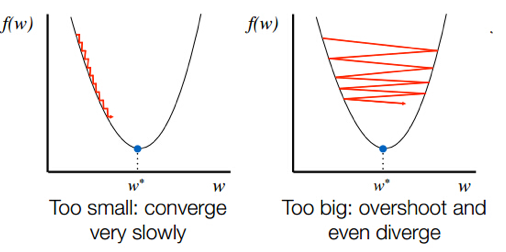
0. 학습목표 Level 1. Level 2. Level 3.
38.[N414] TIL 및 회고
N414 학습목표, 하이퍼파라미터 튜닝
39.[N421] TIL 및 회고
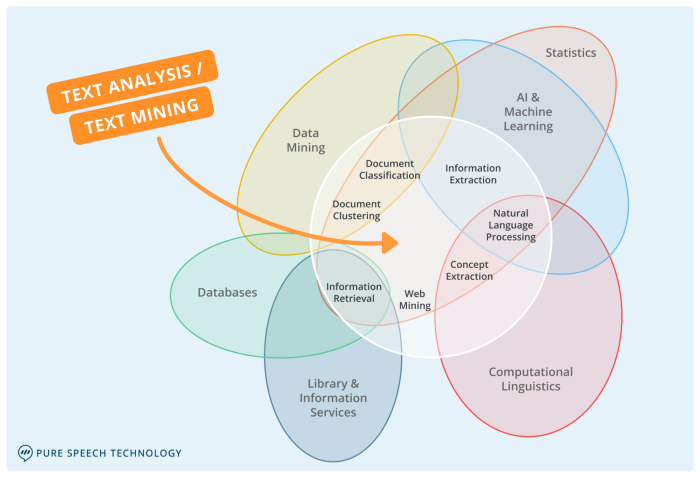
자연어처리를 통해 할 수 있는 Task에는 어떤 것이 있는지 설명할 수 있다. 토큰화(Tokenization)에 대해 설명할 수 있으며 SpaCy라이브러리를 활용하여 토큰화를 진행할 수 있다. 불용어(Stop words), 어간 추출(Stemming)과 표제어 추출(L
40.[N422] TIL 및 회고
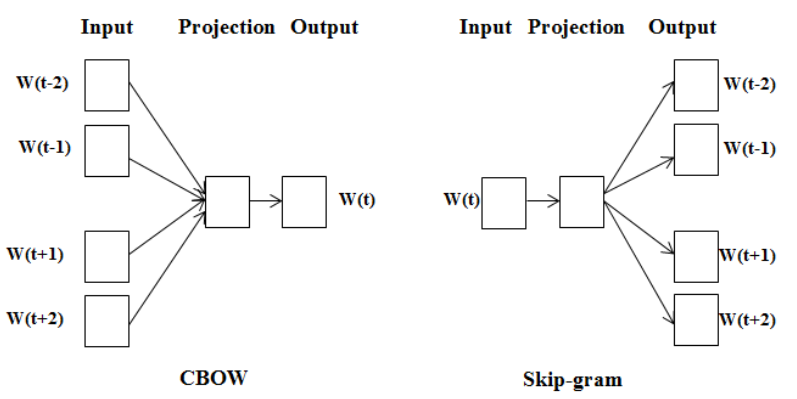
임베딩(Embedding)의 개념과 One-Hot Encoding과 비교되는 장점에 대해 설명할 수 있다.Word2Vec의 두 방법(CBoW, Skip-gram)의 차이와 Word2Vec으로 임베딩한 단어 벡터의 특징에 대해 설명할 수 있다.FastText에서 적용된
41.[N431] TIL 및 회고
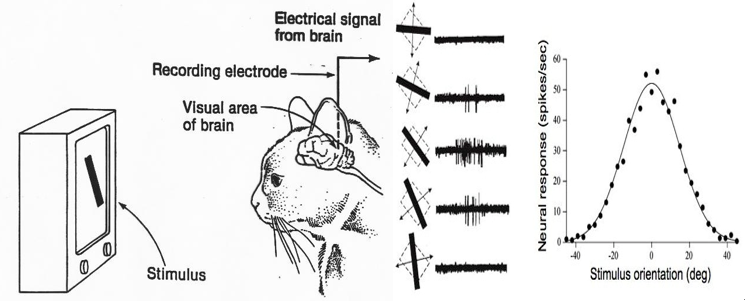
CNN(Convolutional Neural Network)의 기본 구조에 대해 설명할 수 있다.Convolution & Pooling Layer 의 동작 방식과 조정할 수 있는 값(Stride, Padding 등)에 대해 설명할 수 있다.전이 학습(Transfer L
42.[N432] TIL 및 회고

이제 이 정리글을 TIL이라고 할 수 있는지 의문이다. 처음에 시작할 때 매일 꾸준히 정리하자는 의미에서 TIL을 사용했는데 이게 참 나라는 사람이 꾸준하지 못한 것 같다. N432도 분명 지난주에 배웠는데 주말이 지나고서야 정리를 시작한다.
43.[N531] 내용정리
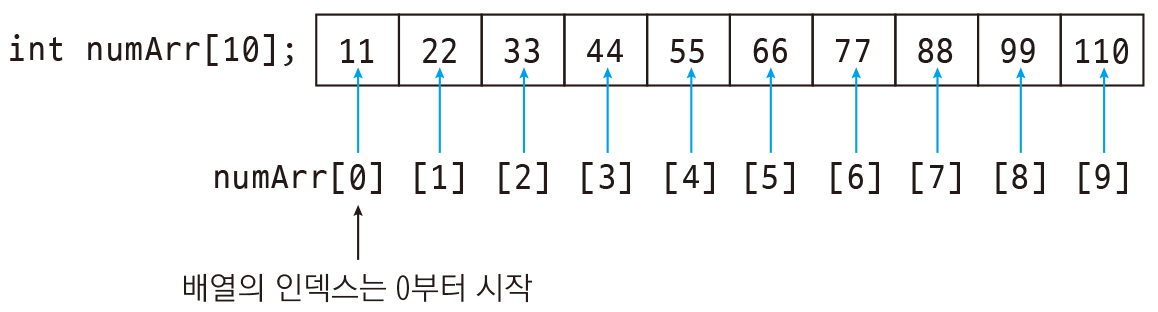
❗️ 화이트 모드 권장중요한 자료구조인 Hash Table에 대해 학습한다.N531~N534의 방향은 기본적인 자료구조를 활용하여 다양한 프로그램을 위한 자료구조와 알고리즘에 대해서 익힌다.해시 테이블은 Key(키)를 활용하여 Value(값)에 직접 접근이 가능한 자료
44.[N532] TIL 및 회고(TIL이라 했지만 일주일이 지난..)
CS 그래프와 트리 그리고 순회, DFS,BFS
45.[N533] 내용정리
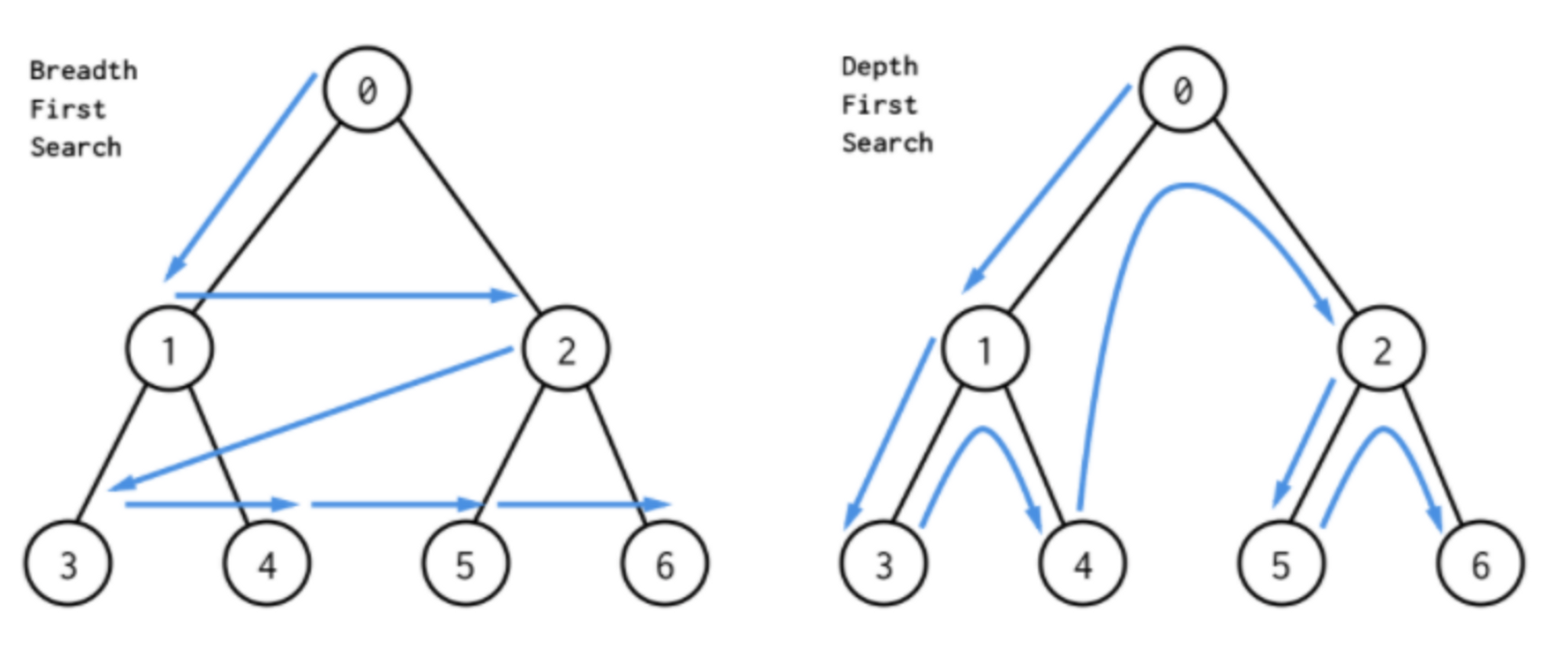
깊이 우선 탐색(Depth-First Search, DFS), 너비 우선 탐색(Breadth-First Serach, BFS)
46.[N534] 내용정리

알고리즘 개념을 숲을 보는 시점으로 생각하기.Dynamic Programming(동적계획법)에 대해 배운다.Greedy Algorithm(그리디 알고리즘 - 탐욕 알고리즘)에 대해 배운다.브루트 포스(Brute Force) \- 무차별 대입 공격, 가능한 모든 조합을