0. 학습목표
- 웹 스크레이핑을 이해하고 설명할 수 있다.
- 파이썬을 통해서 웹 스크레이픙을 할 수 있다.
- HTML 혹은 CSS를 설명할 수 있다.
- DOM에 대해서 설명할 수 있다.
- requests 라이브러리를 사용할 수 있다.
- beautifulsoup 라이브러리를 사용할 수 있다.
1. 주요개념
1. HTML, CSS

위 사진은 구글 홈페이지의 HTML과 CSS이다. 왼쪽이 HTML, 오른쪽이 CSS이다.
1-1. HTML
HyperText Markup Language의 약자로 웹에서 페이즈를 표시할 때 사용한다. [MDN]에서는 웹페이지가 어떻게 구성되어 있어야 하는지 알려주는 마크업 언어라고 소개되어 있다. 즉, 웹페이지에서 보여지는 각 요소들이 어디에 위치해야 하는지 알려주는 마크업 언어이다.
HTML에서는 요소(element)라는 것들이 존재한다. 그리고 각 요소들은 Tag를 통해서 표현된다. 즉, head라는 요소는 <head> </head>처럼 표현된다는 것이다. 이 태그를 잘 보면 두가지 태그로 이루어진 것을 알 수 있는데, 하나는 열어주는 태그(Opening Tag)이고 두 번째는 닫아주는 태그(closing Tag)이다. 두 태그 모두 꺽쇠를 사용하지만 닫아주는 태그만 슬래시 /를 사용한다.
여기서 주의해야하는 것은 모든 요소들에서 닫아주는 태그가 있는 것은 아니다. 요소에 따라서 열어주는 태그만 사용할 때도 있다. 빈 줄을 추가하는 <br>이나 수평으로 줄을 그어주는 <hr>과 같은 요소들이 그 예시이다.
그리고 하나의 요소 안에 다른 요소(Children)을 추가할 수 있다. 방식은 다음과 같다.
<ul>
<li>hello</li>
<li>World</li>
<li>!</li>
</ul>위는 리스트를 HTML에서 표현할 때 쓰는 표현방식으로 이렇게 표현되는 리스트는 내부에 HTML요소가 자동으로 포함되어야 한다.
1-2. CSS
HTML이 웹페이지가 어떻게 구성되어야 있어야 하는지 알려주는 뼈대와 같은 역할을 한다면 CSS는 이를 꾸며주는, 즉 어떻게 표현되는지 알려주는 스타일시트 언어이다. Cascading Style Sheets의 약자로 알 수 있듯이 CSS는 HTML이 표현한 문서가 어떻게 표현되는지 알려준다.
HTML에서도 태그 내에 스타일에 대해서 알려줄 수 있다. 하지만 스타일에 관한 내용이 많아지면 HTML이 복잡해지고 편의성도 떨어지기 때문에 분리해서 사용한다.
CSS에서는 특정 요소를 선택할 수 있는 방법인 셀렉터라는 것들이 존재한다. 다양한 종류의 셀렉터가 존재하며, 그 중에서 기본적인 몇 개만 살펴보면 다음과 같다.
- Type selector: CSS 타입에 따라서 선택할 수 있다.(ex. p, div)
- Class selector: 클래스에 따라 선택할 수 있다.
- Id selector: id에 따라 선택할 수 있다.
CSS 상속
스타일에 대한 문서를 작성할 때 주의해햐 할 점 중 하나가 상속이다. CSS는 요소의 위치에 따라서 상위 요소의 스타일을 상속받도록 되어있다. 이런 특성으로 인해 스타일을 반복작업을 거치지 않고도 하위 자식요소들에게 적용되지만 이에 따라 상속을 어떻게 받을지 잘 생각해야 한다.
<div style = "color:red">
<p>I have no style</p>
</div>p태그는 아무런 스타일이 적용되어 있지 않아도 상위 요소인 div의 스타일을 상속받는다.
CSS Class Selecotor
클래스는 어떤 특정 요소들의 스타일을 정하고 싶을 때 사용된다. 동시에 여러 개의 요소들에 대한 스타일을 정할 때에 보통 클래스를 지정해서 상속받도록 정한다.
.banana {
color:"yellow";
}CSS에서는 위와 같은 방법을 통하여 .을 통해서 클래스를 정의할 수 있다. 이렇게 정의한 클래스는 HTML에서는 다음과 같은 방법으로 적용할 수 있다.
<p class="banana">I have a banana class</p>이때 여러 개의 클래스도 동시에 부여할 수도 있다.
<p class="banana fruit orange">I have a banana class</p>CSS ID Selecotor
클래스와 비슷하게 사용할 수 있는 것이 ID이다. HTML에서는 클래스뿐만 아닌 ID도 지정할 수 있다. 다만 ID는 보통 특정 HTML 요소를 가리킬 때에만 사용된다. 클래스와 달리 보통 여러 개의 요소에 사용되지 않는다. 이러한 차이점을 인지하고 ID 혹은 클래스를 구분할 수 있어야 한다.
CSS에서는 #기호를 통해서 스타일을 정할 수 있다.
#pink{
color:"pink";
}이 ID를 이용하는 HTML예시는 다음과 같다.
<p id='pink'>My id is pink</p>2. DOM
DOM은 Document Object Model의 약어로 웹페이지에서 매우 중요한 역할을 하는 문서 객체 모델이라고 불린다. 여기서 중요한 역할이란 HTML문서에 접근하기 위한 일종의 인터페이스 역할로 문서 내의 모든 요소를 정의하고, 각각의 요서에 접근하는 방법을 제공한다. 이러한 기능 덕분에 프로그래밍 언어에서도 웹페이지의 요소나 스타일 등을 추가하거나 수정하는 등 다양한 작업을 진행할 수 있다.
특히 DOM은 객체(Object)로 표현을 하는데 이 때 object란 JS(Java Script)에서 사용되는 데이터 구조 중 하나를 의미한다. 파이썬에는 이와 비슷한 것으로 dictionary가 존재한다.
즉, DOM을 통해서 HTML을 프로그래밍 언어에서 사용할 수 있는 데이터 구조 형태로 작업을 수행할 수 있어서 크롤링 등 웹 페이지와 작업할 때 매우 중요한 개념 중 하나이다.
DOM의 종류
W3C DOM 표준은 세가지 모델로 구분된다.
1. Core DOM: 모든 문서를 타입을 위한 DOM모델
2. HTML DOM: HTML문서를 위한 DOM모델
3. XML DOM: XML문서를 위한 DOM모델
DOM을 사용할 수 있는 가장 손쉬운 방법 중 하나는 개발자 도구를 열어서 Console 창으로 들어가 JS를 통하여 DOM을 사용해 보는 것이다.
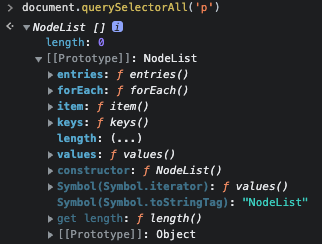
위 사진은 Console창에서 JS를 통해서 NodeList라는 이름의 p태그를 사용하는 요소들을 담은 유사 배열이라는 것을 받은 것이다. 이처럼 HTML이나 XML 등 웹페이지의 문서 형식을 프로그래밍 언어에서도 사용할 수 있는 큰 장점이 있다.
이와 비슷하게 DOM에는 다양한 기능들이 존재하며 대표적인 몇가지만 나타내어 보겠다.
getElementsbyTagName: 태그 이름으로 문서의 요소들을 리턴한다.getElementById: id가 일치하는 요소들을 리턴한다.getElementByClassName: class가 일치하는 요소들을 리턴한다.querySelector: selector와 일치하는 요소들을 리턴한다.querySelectorAll: selector와 일치하는 모든 요소들을 리턴한다.
DOM은 크롤링 할 때에도 DOM의 개념은 중요하다. 예를 들어 파이썬에서 크롤링을 한다고 해도 웹 페이지를 텍스트, 즉 문자열로 읽게되면 원하는 정보를 찾기가 쉽지 않을 것이다. 하나의 거대 문자열로 웹페이지를 인식하게 되면 텍스트를 해석하고 원하는 정보를 찾을 때 구별하기 쉽지 않게 된다. 따라서 보통은 웹페이즈를 텍스트 형식으로 사용하는 것이 아닌 DOM을 활용한다.
<html>
<head>
</head>
<body>
<h1>h1 태그입니다.</h1>
<p>p 태그입니다.</p>
</body>
</html>위와 같은 간단한 html이 있다고 하자. 여기서 만일 h1의 내용을 알고 싶을 때 html이 전부 문자열이였다면 태그를 구분할 수 있는 방법을 먼저 고민하고, 그 후에 태그 내부에 있는 정보를 받아 사용할 수 있다. 하지만 이렇게 되면 단순한 작업을 하는 것도 오래 걸리게 된다.
반면에 DOM을 사용하면 위에서 봤던 예시처럼 간단한 명령어를 통해서 태그 내용을 추출할 수 있다. 이런 편의성으로 인해 DOM이 중요하다.
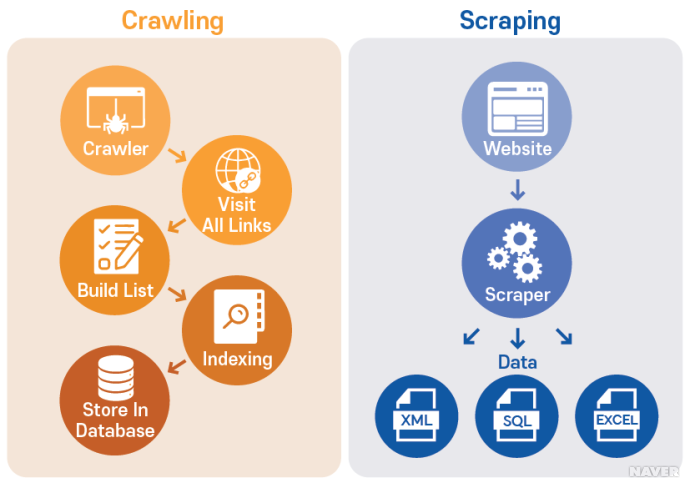
3. 웹 스크레핑과 크롤링
웹스크레핑
웹 스크레핑은 특정 웹 사이트나 페이지에서 필요한 데이터를 자동으로 추출해 내는 것을 의미한다. 원하는 데이터를 추출하기 위해서 특정 웹 사이트에 콘텐츠를 다운로드하기 위한 HTTP GET요청을 보낸다. 이에 사이트가 응답하면 HTML문서를 분석하여 특정 패턴을 지닌 데이터를 뽑아낸다. 그리고 추출된 데이터를 원하는 대로 사용할 수 있도록 데이터베이스에 저장한다.
웹 스크래핑은 자동으로 수집된 특정 정보가 필요한 분야에서 다양하게 활용되고 있다. 금융 및 주식 시장의 경우, 스크래핑 기술을 활용하여 뉴스 정보를 모으기도 하고, 애널리스트들이 투자 자문을 위해 활용할 수 있는 기업 재무제표 정보를 자동으로 수집하기도 한다. 전자 상거래 시장의 경우 경쟁력 확보를 위해 경쟁사 상품의 정보를 수집하고 가격 변동 이슈를 빠르게 파악하기 위해 스크래핑 기술을 활용하기도 한다.
웹 스크레핑은 특정사이트에 필요한 데이터를 찾는데 집중하기 때문에 데이터 포인트를 정확히 잡고 확실한 정보만을 수집할 수 있다는 점에서 유용한다. 장기적으로 서비스 대역폭이나 비용을 절약할 수 있다는 장점이 있다.
그리고 스크래핑은 방식에 따라서 크게 정적 스크래핑과 동적 스크래핑 나눌 수 있다.
정적 스크래핑은 정적인 데이터를 수집하는 방법으로 한 페이지 안에서 원하는 정보가 모두 들어나는 경우에는 이 방식을 활용하여 스크래핑할 수 있다. beautifulsoup4가 대표적인 라이브러리이다.
동적 스크래핑은 페이지에서 로그인, 스크롤 등의 이동이나 실시간으로 페이지의 내용이 계속 추가되거나 수정될 때 사용할 수 있는 방식이다. Selenium이 대표적인 라이브러리이다.
웹크롤링
웹 크롤링이란 "기어다니다"라는 뜻을 지닌 이름에서도 알 수 있듯이 여러 웹사이트들을 기어다니며 원하는 정보를 탐색하고 수집하는 작업을 의미한다. 인터넷에 존재하는 방대한 양의 정보를 사람이 일일히 파악하는 것은 불가능한 일이다. 때문에 규칙에 따라 자동으로 웹 문서를 탐색하는 컴퓨터 프로그램, 웹 크롤러(Crawler)를 만들었다.
크롤러는 인터넷을 돌아다니며 여러 웹 사이트에 접속한다. 그리고 페이지의 내용과 링크의 복사본을 생성하여 다운로드하고 요약본을 만든다. 그리고 검색 시 유용한 정보만을 노출하도록 검색 색인을 붙인다. 이는 도서관에서 책을 찾기 위해 분류 기준을 구성하는 것과 비슷한 작업이다.
웹 크롤링은 웹상을 돌아다니며 방대한 양의 정보를 수집하기 때문에, 특정 키워드에 대한 심층 분석이 필요할 때 유용하다. 또한 크롤러는 실시간 정보 수집을 위해 계속해서 작동하므로 자주 변화하는 데이터를 파악하기가 좋다.
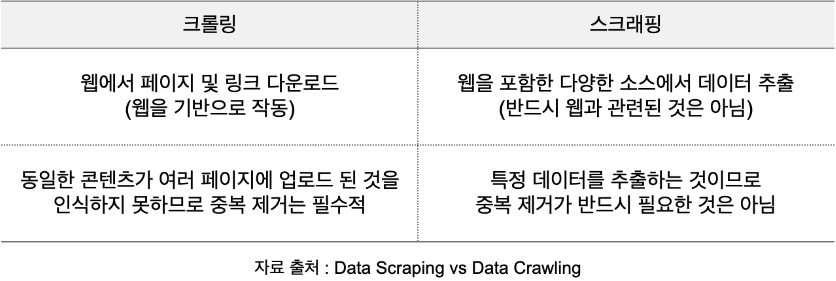
차이점
둘은 "원하는 데이터를 모을 수 있다."라는 점이 비슷하여 의미가 자주 혼용되고 한다. 또한 기술적으로 함께 사용되는 경우가 많아 더욱 헷갈린다. 하지만 웹 크롤링은 웹 페이지의 링크를 타고 계속해서 탐색을 이어나가지만, 웹 스크레핑은 데이터 추출을 원하는 대상이 명확하여 특정 웹 사이트만을 추적한다는 차이점이 있다.
또한 웹 크롤링은 페이지를 모아 색인화하고 검색 결과에 내가 찾는 키워드와 관련된 링크만 모아 볼 수 있도록 작동한다. 하지만 웹 스크래핑은 상품의 가격, 주식정보 등 원하는 데이터가 명확하여, 흩어져있는 해당 데이터를 자동으로 추출하여 전달한다. 이 외에 차이점은 아래와 같다.
4. Library: requests
파이썬에서 사용할 수 있는 웹과 소통을 편하게 해주는 라이브러리이다. 이 라이브러리는 파이썬에서 HTTP요청을 보낼 때 거의 표준으로 사용되는 정도로 많이 사용되고 있다. 특히 HTTP요청을 간단한 메소드를 통해 실행할 수 있도록 짜여졌다는 것이 가장 큰 장점 중 하나이다. 따라서 사용자는 HTTP요청이나 응답에 대한 고민을 줄이고 실제 서비스나 기능에 더욱 집중할 수 있게 된다.
먼저 pip을 사용하여 라이브러리를 설치해준다.
pip install requests다음으로 라이브러리를 불러와서 원하는 사이트의 콘텐츠를 다운로드 하기 위한 Get요청을 다음과 같이 보낼 수 있다.
import requests
requests.get('{사이트주소}')
-------------------------
<Response [200]> # 정상적으로 연결됐을 시 출력응답 객체의 type을 확인하면 다음과 같은 결과가 출력된다.
<class 'requests.models.Response'>requests라이브러리의 Response타입인 것을 알 수 있다.
import requests
url = 'https://google.com'
resp = requests.get(url)
print(resp.status_code)위 코드를 통해서 응답의 상태 코드를 확인할 수 있다. 200이라고 출력된다면 정상적으로 요청이 처리된 것이다.
다음으로는 응답 객체를 통해 응답 내용을 살펴보겠다. 먼저 웹 브라우저를 통해 웹 페이지에 접속하게 되면 보이게 되는 HTML은 사실 브러우저에서 뒷작업을 거치면서 보여지게 되는 것이다. 그러나 본질은 HTML, CSS 등 문서 파일이라는 것은 변함이 없다.
따라서 requests라이브러리를 활용해서 웹 브라우저가 받는 동일한 HTML문서를 받을 수 있다. 물론 이것 뿐만 아니라 서버에서 보내주는 데이터도 받을 수 있다.
일단 Response객체에는 text라는 속성이 존재한다. 이 속성은 서버에서 받은 응답을 텍스트 형식으로 보여주게 된다. 서버에서 받게되는 응답의 데이터는 실제로 bytes로 받게 된다. 따라서 해당 데이터를 텍스트로 인지하기 위해서는 알맞게 디코딩 작업을 거쳐야 한다. 이런 디코딩 작업을 text속성이 알아서 해주기 때문에 보통은 걱정하지 않아도 된다. 그리고 requests의 기본적인 인코딩 방법은 utf-8이다.
resp.text
----------
'<!doctype html><html itemscope=" "......><head>...</head></html>'출력을 자세히 살펴보면 하나의 HTML파일이다.
5. Library: BeautifulSoup
공식문서: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
requests를 통하여 실질적으로 돌려받은 응답 내용을 파싱(parsing)하고 정보를 얻어낼 수 있어야 한다. BeautifulSoup 라이브러리는 받아온 HTML파일을 파싱해서 원하는 정보를 손쉽게 찾을 수 있도록 해준다.
💡 파싱(Parsing)이란?
파싱은 구문 분석이라고 한다. 문장이 이루고 있는 구성 성분을 분해하고 분해된 성분의 위계 관계를 분석하여 구조를 결정하는 것이다. 즉 데이터를 분해 분석하여 원하는 형태로 조립하고 다시 빼내는 것을 말한다. 웹상에서 주어진 정보를 내가 원하는 형태로 가공하여 서버에서 불러들이는 것이다.
더 쉽게 이야기하면 HTML 등을 파이썬 등에서도 사용할 수 있게 변환해주는 것이라 생각해도 된다.
설치는 다음과 같이 pip을 사용하여 설치한다.
pip install beautifulsoup4기본 파싱
먼저 파싱할 문자열과 어떻게 파싱할 것인지 정한다. 기본적으로 사용할 수 있는 parser는 html.parser이다. 이때 이 parser는 파이썬 기본 라이브러리에 포함되어 있기 때문에 별도의 설치가 필요하지 않지만, 만약에 XML문서나 다른 HTML파서(ex. htm5lib)등을 사용하려면 따로 설치를 진행해야 한다. 각 parser에 대한 장단점은 공식문서에 나와있다.
다음과 같은 코드를 이용하면 문자열로 된 HTML파일을 넘길 수 있다.
import requests
from bs4 import BeautifulSoup
url = 'https://google.com'
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')요소찾기
파싱을 완료했으면 원하는 요소를 찾아내야 한다. 기본적으로 id, class, tag 등의 특징들과 find 및 find_all메소드를 이용해 찾아내는 방법들을 알아보겠다.
bs4에서 한 개의 요소를 찾을 때에는 find, 여러 개의 요소들을 찾을 때는 find_all을 사용하게 된다. find는 조건에 일치하는 첫번째 결과를 리턴하고 find_all은 조건에 일치하는 모든 결과를 리스트에 담아 반환한다. 그리고 여기서 얻게 되는 결과들은 HTML문서이기 때문에 결과를 가지고 다시 find혹은 find_all과 같은 메소드를 실행할 수 있다.
"""
id = 'dog'인 요소 찾기
id는 주로 한번만 사용되기 때문에 find 사용
"""
dog_element = soup.find(id='dog')
------------------------
"""
class = 'cat'인 요소 찾기
class를 이용해 찾을 경우 class_을 사용해야 한다. 이는 파이썬의 class와 구분하기 위함이다.
class는 다양한 요소에 사용되기 때문에 find_all을 사용
"""
cat_elements = soup.find_all(class_='cat')
------------------------
"""
앞 서 설명했듯이 얻게된 결과 역시 HTML문서이기 때문에 결과를 가지고
다시 find 및 find_all사용 가능
"""
cat_elements = soup.find_all(class_='cat')
for cat_el in cat_elements:
cat_el.find(class_='fish')태그 활용
조금 더 상세하게 찾고 싶을 경우 tag를 조합해서 사용할 수 있다.
예를 들어 cat이라는 클래스가 div라는 태그에도 있고 p태크에도 있다면 이 때 div태크를 사용하는 요소들만 가지고 오고 싶다면 다음과 같이 실행할 수 있다.
cat_div_elements = soup.find_all('div',class_ = 'cat')String 활용
특정 문자열이 포함되어 있는 요소를 찾고 싶을 때 사용할 수 있다. 만일 raining이라는 문자열이 포함되어 있는 요소를 찾고 싶다면 string파라미터를 이용해 다음과 같은 코드를 사용할 수 있다.
soup.find_all(string='raining')이때 string의 단점은 명시한 문자열을 그대로 찾는다는 것이다. 즉, 정확히 raining이라는 문자열을 포함하는지 확인한다. 만약에 대소문자를 잘못 적어써나 띄어쓰기를 실수했다해도 동일한 문자열을 포함한 요소를 찾는다.
만일 이런 엄격한 기준으로 찾기보다 대소문자 구분없이 들어가 있는 것을 찾고 싶다면 익명함수를 활용할 수 있다.
soup.find_all(string=lambda text: 'raining' in text.lower())이때 string을 사용하면 .string속성을 불러오는 것이기 때문에 요소가 아닌 문자열로 리턴된다. 따라서 하나의 요소로 받기 위해서는 태그도 같이 추가해야 된다.
soup.find_all('h3', string='raining')정보 얻기
원하는 요소들을 선택했다면 이제부터는 정보를 얻어낼 수 있어야 한다. 기본적으로 text속성을 이용해서 내부 문자를 얻어낼 수 있다. 다음과 같은 HTML에서 p태그 내부 글을 얻으려면 text속성을 사용할 수 있다.
<p class='cat'>This is a p-cat</p>cat_el = soup.find('p', class_='cat')
cat_el.text
------------------------------------
'This is a p-cat'만일 불필요한 띄어쓰기가 있을 수 있다. 그럴 때에는 파이썬의 strip메소드를 사용해서 정리해줄 수 있다. strip은 특정 문자를 제거하는 함수로 아무 인자도 입력으로 주지 않으면 공백을 제거한다.
cat_el.text.strip()2. 회고
음...할 말이 없다. 너무 오래 지났다. 일단 빨리 다음 것도 마무리하고 정상화 렛츠기릿 해야겠다.
