[PyTorch/에러 해결] RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:1 and cuda:0! (when checking argument for argument weight in method wrapper__cudnn_convolution)
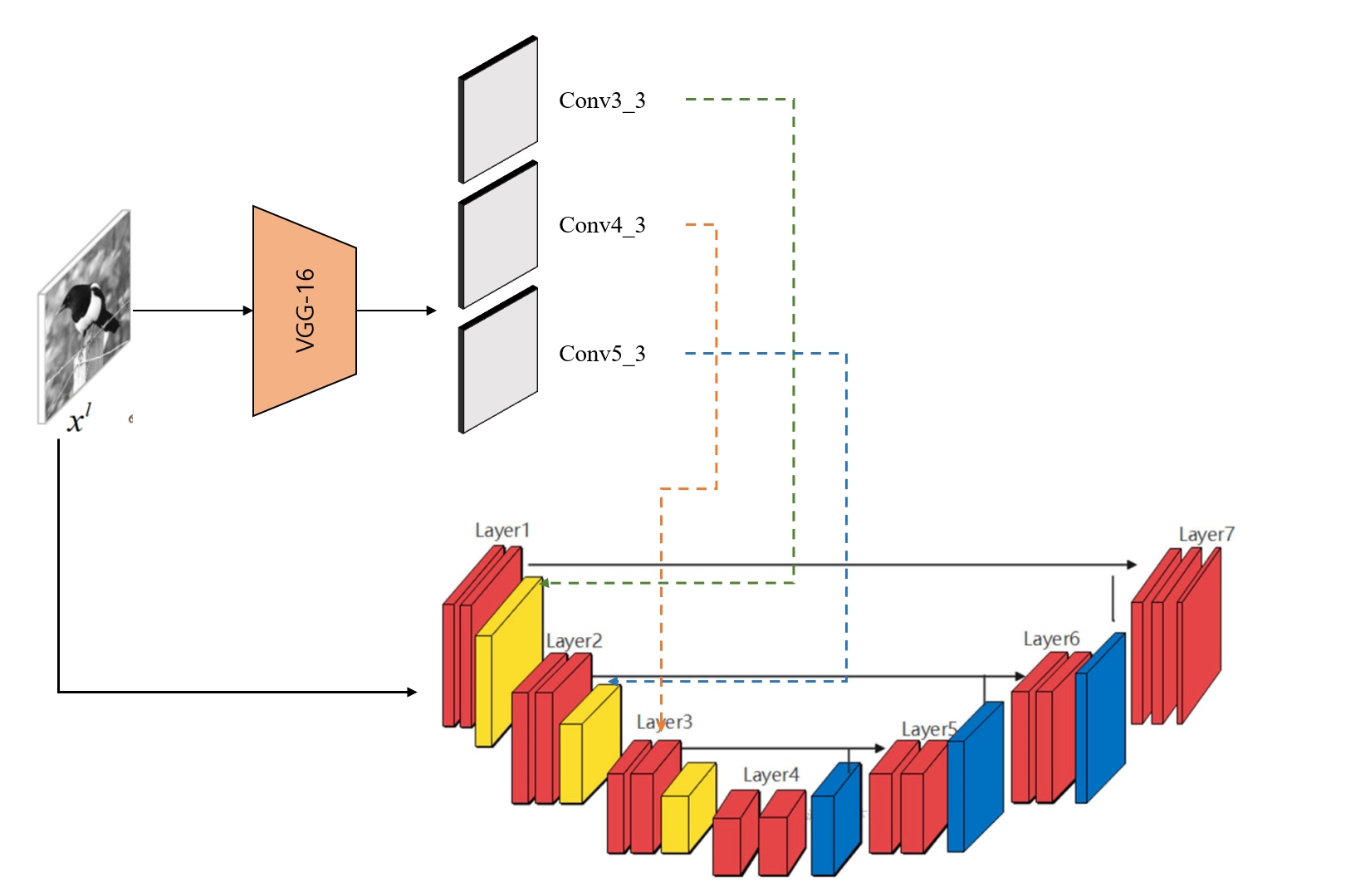
Pretrained 된 VGG16 Model의 Feature Map과 U-Net에서 나온 feature map을 concat 하고 self-attention 연산을 할때 에러가 났다. 간단하게 그림으로 표현하면 아래와 같다.
VGG16에서 얻은 feature map들을 각 U-Net block에 concat후 self-attention을 진행한다.
# Attention U-Net 코드 일부
class Attention_block(nn.Module):
def __init__(self, F_g, F_l, F_int): #Forward g, l, int?
super(Attention_block, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self,g,x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.relu(g1+x1)
psi = self.psi(psi)
return x*psi
x = self.Att5(g=feature_map_vgg,x=x_from_unet)
위 코드의 feature_map_vgg 이랑 x_from_unet은 각 다른 모델에서 forward가 되었기 때문에 일반 nn.DataParallel 연산을 할 때 다른 cuda에 올려놔있다. 여러가지 해결방안을 해보다 (chatgpt 조차 해결해주지 못했다 ㅠ) 임시방편으로 되는 코드를 찾아 일기로 남길 겸 공유해본다.
Forward 함수에서 self attention 전에 self attention에 들어가기전 input을 .cuda() 쿠다로 넣어주고 그다음 input을 같은 전 input의 device로 같이 설정해준다. 상세 코드는 아래와 같다.
x5 = self.conv5(vgg16_featuremap)
x5 = x5.cuda()
x4 = x4.to(x5.device) # x4을 x5랑 같은 device로 강제로 설정하기
d5 = self.Up5(x5) # 2, 512, 28, 28
x4 = self.Att5(g=d5,x=x4)
d5 = torch.cat((x4,d5),dim=1)
d5 = torch.cat((d5, model_fusion), dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
d4 = d4.cuda()
x3 = x3.to(d4.device) # x3를 d4과 같은 device로 설정하기
x3 = self.Att4(g=d4,x=x3)
d4 = torch.cat((x3,d4),dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
d3 = d3.cuda()
x2 = x2.to(d3.device) # x2 도 d3로 같은 device로 강제로 설정하기
x2 = self.Att3(g=d3,x=x2)
d3 = torch.cat((x2,d3),dim=1)
d3 = self.Up_conv3(d3)
d1 = self.Conv_1x1(d3)
return d1, classification_semantics, true_distribution

잘 학습되는걸 볼 수 있다!
결론적으로 DataParallel때문에 각 모델에서 나온 output들이 다른 device에 설정이 되어있다. 아무리 model을 model.to(device)로 설정해도 문제가 해결이 안된 만큼 강제로 output을 같은 device로 넣게 만들어서 문제를 해결했다.
물론 이 해결법이 정확한 해결법이나 optimal한 해결법은 아닐 수도 있다. 하지만 누군가에게 비슷한 에러를 (cuda and cpu 말고 cuda:0, cuda:1)처럼 다른 2 gpu에서 dataparallel을 돌리는 경우, 이 글이 도움이 됐으면 좋겠다.
