데이터셋의 종류
- 학습 데이터(train data) : 알고리즘이 학습할 데이터로 모델 학습에 주가 되는 역할
- 테스트 데이터(test data) : 일반적으로 컴퓨터 프로그램의 테스트에 사용하기 위해 특별히 식별된 데이터
- 검증 데이터(Validation data) : 모델의 성능 평가 및 훈련에 적절한 지점을 찾기 위한 데이터, 과대적합/과소적합 방지
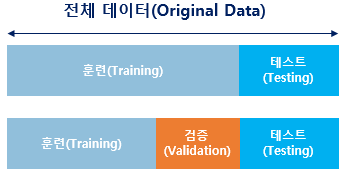
- 보통 훈련 데이터를 쪼개서 검증 데이터를 만들어냄
나누는 방법은 여러가지가 있지만, 보통 train_test_split()함수를 사용해서 함
from sklearn.model_selection import train_test_split
#x, y는 임의의 데이터셋
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3)과적합이란?
과적합(overfit) : 모델이 훈련 데이터에 너무 가깝게 맞춰져 새 데이터에 어떻게 대응해야 할지 모를 때 발생하는 머신러닝 행동
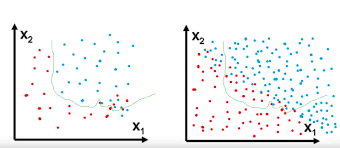
보통 훈련 데이터에 대한 정확도가 96-97% 정도로 되어있지만, 테스트 데이터에 대한 정확도가 80%이하로 나올 때 과적합이 일어났다고 판단함.
그래프로 적합 확인하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import ModelCheckpoint
from sklearn.model_selection import train_test_split
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
!git clone https://github.com/taehojo/data.git
df = pd.read_csv('./data/wine.csv', header=None)
X = df.iloc[:,0:12]
y = df.iloc[:,12]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
#모델 저장 조건 설정
modelpath="./data/model/all/{epoch:02d}-{val_accuracy:.4f}.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, verbose=1)
history=model.fit(X_train, y_train, epochs=50, batch_size=500, validation_split=0.25, verbose=0, callbacks=[checkpointer])
score=model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])
#데이터 오차를 보기 위해서 epochs 를 2000으로 매우 많이 설정해놓음
history=model.fit(X_train, y_train, epochs=2000, batch_size=500, validation_split=0.25)
hist_df=pd.DataFrame(history.history)
#훈련 데이터, 테스트 데이터의 오차를 저장
y_vloss=hist_df['val_loss']
y_loss=hist_df['loss']
#그래프로 표현
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, "o", c="red", markersize=2, label='Testset_loss')
plt.plot(x_len, y_loss, "o", c="blue", markersize=2, label='Trainset_loss')
plt.legend(loc='upper right')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()결과 :
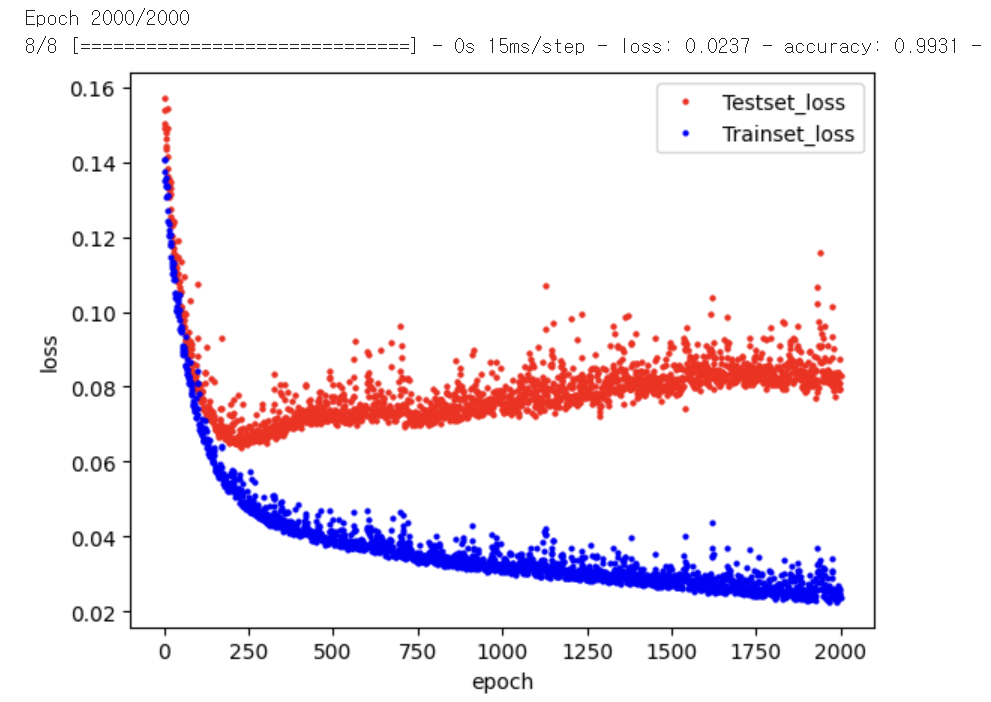
데이터를 보면 특정 순간부터 테스트 데이터의 오차가 늘어나는 것을 볼 수 있는데, 이 순간이 과적합이 일어나는 순간이라고 볼 수 있음.
과적합 방지 학습 중단
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
import os
import pandas as pd
!git clone https://github.com/taehojo/data.git
df = pd.read_csv('./data/wine.csv', header=None)
X = df.iloc[:,0:12]
y = df.iloc[:,12]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 학습 중단을 할 순간을 설정
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=20)
# 중단된 이후, 최적화된 모델을 저장할 곳을 선언
modelpath="./data/model/Ch14-4-bestmodel.hdf5"
#모델을 업데이트하고 저장
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=0, save_best_only=True)
history=model.fit(X_train, y_train, epochs=2000, batch_size=500, validation_split=0.25, verbose=1, callbacks=[early_stopping_callback,checkpointer])
score=model.evaluate(X_test, y_test)
print('Test accuracy:', score[1])결과 :


결과를 보면, epoch를 2000으로 설정해놓았지만 188번에서 중단되었고, 그 모델은 경로대로 보관된 것을 알 수 있다.
- 위 코드에서 학습 중단을 위해 사용한 EarlyStopping() 이라는 함수는 알아서 모드를 설정해주고, 데이터의 조건에 따라 멈춰야 할 때 중단해준다
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=50)
# 이 코드의 경우, validation accuracy가 1% 증가하지 않는다면 성능의 증가가 없다고 정의함.실습 : 유명한 음식들의 영양성분을 통한 음식 예측
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
import os
import pandas as pd
#따로 저장한 데이터를 가져옴
ndf = pd.read_csv('/content/nutrients_csvfile.csv')
#전처리 과정. 데이터들이 object로 되어있기에 이것들을 float으로 바꿔주기 위한 과정들
#str로 구분될 수 있는 것들은 모두 0으로 해주고, ','는 제거해도 문제없기에 제거해줌
#8-44로 애매하게 되어있는 것은 최대치로 설정해주고, NaN은 0으로 채워줌줌
ndf = ndf.replace('t','0')
ndf = ndf.replace("t'",'0')
ndf = ndf.replace("a",'0')
ndf['Grams'] = ndf['Grams'].str.replace(',', '')
ndf['Calories'] = ndf['Calories'].str.replace(',', '')
ndf = ndf.replace('8-44', '44')
ndf = ndf.fillna(0)
ndf = ndf.astype({'Grams' : 'float', 'Calories': 'float', 'Protein': 'float', 'Fat': 'float', 'Sat.Fat': 'float', 'Fiber': 'float', 'Carbs': 'float'})
ndf.head()
#데이터를 필요한 부분만 잘라냄
nx = ndf.iloc[:,2:9]
ny = ndf.iloc[:,9]
nx_train, nx_test, ny_train, ny_test = train_test_split(X, y, test_size=0.3, shuffle=True)
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(nx_train, ny_train, epochs=100, batch_size=300, validation_split=0.25)
score=model.evaluate(nx_test, ny_test)
print('Test accuracy:', score[1])결과 :


-ㅅ-)b