train data - test data
학습 데이터(train data) : 알고리즘이 학습할 데이터로 모델 학습에 주가 되는 역할
테스트 데이터(test data) : 테스트 데이터는 일반적으로 컴퓨터 프로그램의 테스트에 사용하기 위해 특별히 식별된 데이터
보통 train data와 test data 사이에 validation data(검증 데이터) 가 있음. 검증 데이터는 훈련 데이터의 값을 미세하게 조절할 때 사용함.
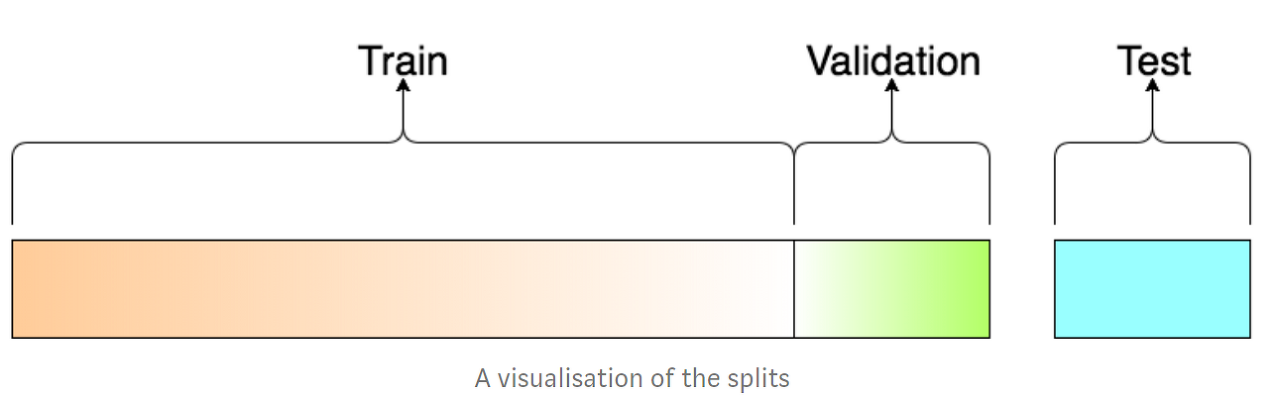
나누는 방법
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, shuffle = True)
#x, y 를 이용해서 train 과 test 데이터를 구분함. 비율은 train : test = 7 : 3 정도
# shuffle은 데이터를 나눈 뒤 무작위로 섞어서 학습을 더 효율적으로 할 수 있게 도와줌overfit과 underfit
데이터를 학습시키는 것도 정확도를 높이기 위해 하는 행동이다. if 정확도가 100%라고 뜬다면?
과적합(overfit) : 기계 학습 모델이 학습 데이터에 대한 정확한 예측을 제공하지만 새 데이터에 대해서는 제공하지 않을 때 발생하는 바람직하지 않은 기계 학습 동작
- epoch이 증가할수록 과적합이 일어날 확률이 높음
과소적합(underfit) : 과소적합은 테스트 세트의 성능이 향상될 여지가 아직 있을 때
- 아직 학습을 덜 했거나, epoch의 수가 너무 적을 때 과소적합이 일어남
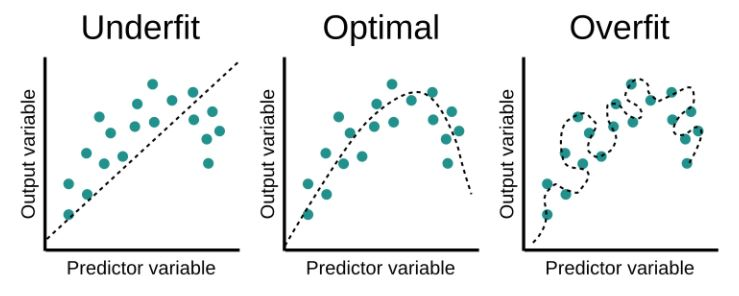
모델 성능 평가
모델 성능 평가 : 실제값과 모델에 의해 예측된 값을 비교하여 그 두 값의 오차를 구하는 것
과적합을 방지하고 최적의 모델을 찾기 위해 실시함
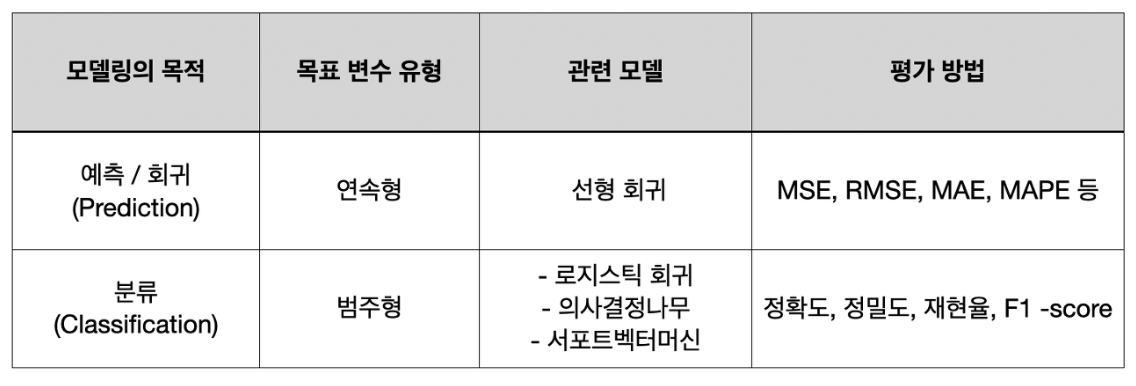
모델링의 목적에 따라 다른 평가 방법을 사용함.
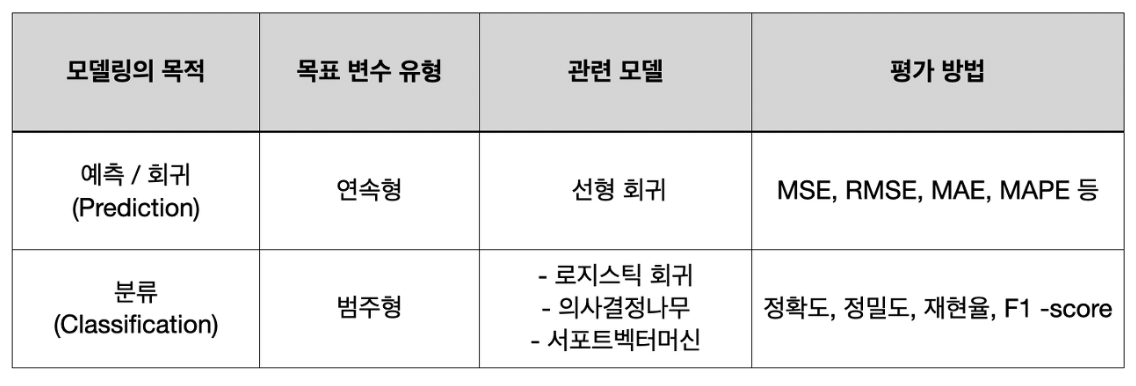
회귀 모델은
- MSE(평균 제곱 오차)
- RMSE(평균 제곱근 오차)
- MAE(평균 절대 오차)
- MAPE(평균 절대비율 오차)
등을 사용함
회귀 모델의 평가는 평가값이 작을수록 모델이 좋음을 의미함
분류 모델은 여러 지표를 종합해서 비슷한 정도가 높을 수록 좋음을 의미함
- 정확도(Accuarcy) : 전체 데이터 중 정확하게 예측한 데이터의 수
- 이때, 불균형한 데이터를 사용하게 될 경유 분류 모델 성능 평가에서는 빼는 것이 좋음
- 오차 행렬(Confusion Matrix) : 분류한 예측 범주와 실제 데이터의 분류 범주를 교차 표(cross table)로 정리한 것
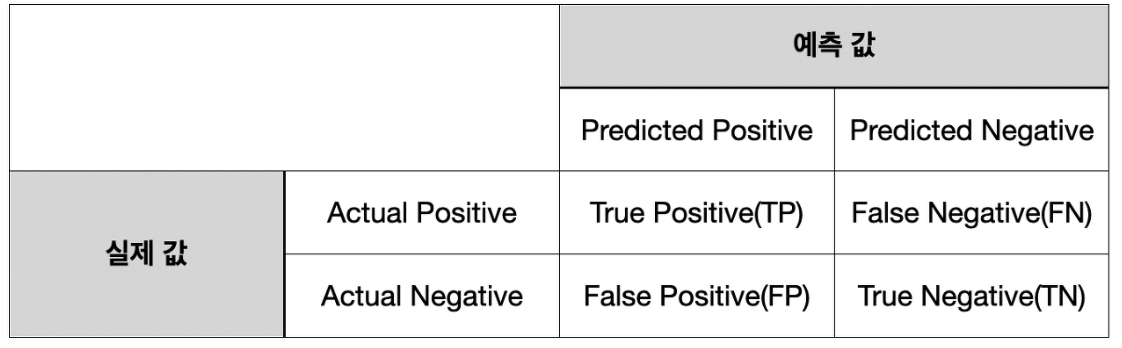
- 정밀도(Precision) : 양성으로 판단한 것 중, 진짜 양성의 비율

- 재현율(Recall) : 진짜 양성으로 판단한 것 중, 올바르게 양성으로 판단한 비율
- 다른 말로 민감도(Sensitivity)라고 함

정밀도와 재현율의 중요성은 상황에 따라 다른데,
Positive data를 Negative 로 잘못 판단하면 안되는 경우 → 재현율
Negative data를 Positive 로 잘못 판단하면 안되는 경우 → 정밀도
둘의 상황에 따라서 중요한 지표는 다르게 됨.
- F1 Score : 정밀도와 재현율을 결합하여 만든 지표
- 둘 다 평균적으로 나올 때 F1 Score은 높게 나옴

실습 : 초음파 광물 예측하기
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
import pandas as pd
df = pd.read_csv('./data/sonar3.csv', header=None)
X = df.iloc[:,0:60]
y = df.iloc[:,60]
#x, y 를 이용해서 train 과 test 데이터를 구분함. 비율은 train : test = 7 : 3 정도
# shuffle은 데이터를 나눈 뒤 무작위로 섞어서 학습을 더 효율적으로 할 수 있게 도와줌
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True)
model = Sequential()
#모델의 입력층과 은닉층은 relu를 사용함. 기울기 소실을 방지하기 위해서.
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 분류 모델이기 때문에 이진 함수인 sigmoid 함수를 사용함
# binary_crossentropy 를 사용하면 로그함수를 이용해 오차 함수를 구현함
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X_train, y_train, epochs=200, batch_size=10) # train data로 학습
score = model.evaluate(X_test, y_test) # test data로 정확도 구하기
print('test accuracy : ', score[1])
결과를 보면, train 의 정확도는 0.98, test의 정확도는 0.85 정도 이다.
K겹 교차검증
k겹 교차검증 (그 K 아님) : 집합을 체계적으로 바꿔가면서 모든 데이터에 대해 모형의 성과를 측정하는 검증 방식
- k겹은 전체 데이터셋을 k개의 부분집합으로 나눈다는 의미로, 변수 k를 의미한다.
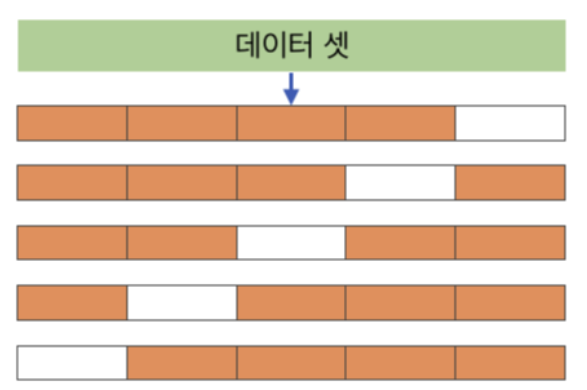
예시
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import pandas as pd
df = pd.read_csv('./data/sonar3.csv', header=None)
X = df.iloc[:,0:60]
y = df.iloc[:,60]
k=5
kfold = KFold(n_splits=k, shuffle=True)
acc_score = [] # 정확도 체크
#모델은 앞에서 사용했던 모델을 그대로 사용할 예정
def model_fn():
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
return model
for train_index , test_index in kfold.split(X): # k번 반복해 test data와 train data를 구분함
#구분
X_train , X_test = X.iloc[train_index,:], X.iloc[test_index,:]
y_train , y_test = y.iloc[train_index], y.iloc[test_index]
#모델 학습
model = model_fn()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X_train, y_train, epochs=200, batch_size=10, verbose=0)
accuracy = model.evaluate(X_test, y_test)[1]
acc_score.append(accuracy) # 매번 체크한 정확도를 삽입
avg_acc_score = sum(acc_score)/k # 그 정확도들의 평균을 구함
print('정확도:', acc_score)
print('정확도 평균:', avg_acc_score)