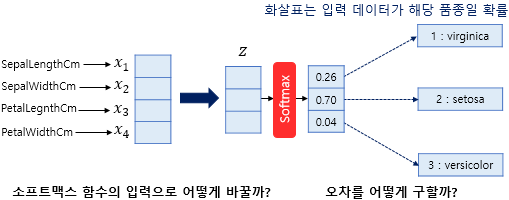
다중 분류 (Multiclass Classification)
다중 분류 : 3개 이상의 선택지 중에서 1개를 고르는 다중 클래스 분류
원 핫 인코딩 (One-Hot Encoding)
원 핫 인코딩 : 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 벡터 표현 방식
매우 기초적인 인코딩 방법이라서 많은 곳에서 자주 쓰임.

from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
text = "나랑 점심 먹으러 갈래 점심 메뉴는 햄버거 갈래 갈래 햄버거 최고야"
tokenizer = Tokenizer()
tokenizer.fit_on_texts([text])
print('단어 집합 :',tokenizer.word_index)
sub_text = "점심 먹으러 갈래 메뉴는 햄버거 최고야"
encoded = tokenizer.texts_to_sequences([sub_text])[0]
print(encoded)
# 이 함수로 원 핫 인코딩을 할 수 있음
one_hot = to_categorical(encoded)
print(one_hot)
#밑에 나오는 함수이지만, 이것으로도 원 핫 인코딩을 한 것처럼 볼 수 있음
# 결과 같음
y = pd.get_dummies(y)소프트맥스 함수 (Softmax Function)
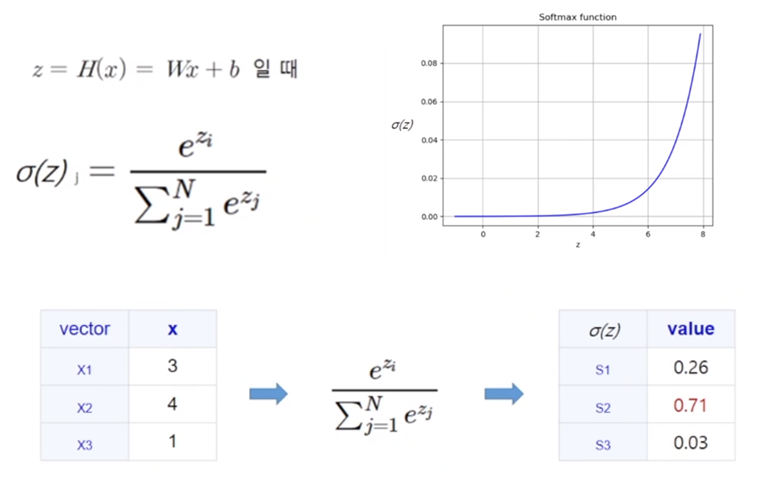
소프트맥스 함수 : 선택해야 하는 선택지의 총 개수를 k라고 할 때, k차원의 벡터를 입력받아 각 클래스에 대한 확률을 추정
다른 말로는 다항 로지스틱 회귀 라고 한다
- 로지스틱 회귀는 이진 분류일때 사용하고, 소프트맥스 함수는 다중 분류일때 사용함
실습 : Iris 데이터 분류
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
!git clone https://github.com/taehojo/data.git
df = pd.read_csv('./data/iris3.csv')
#데이터를 불러와서 sns으로 plot 으로 시각화
sns.pairplot(df, hue = 'species')
plt.show()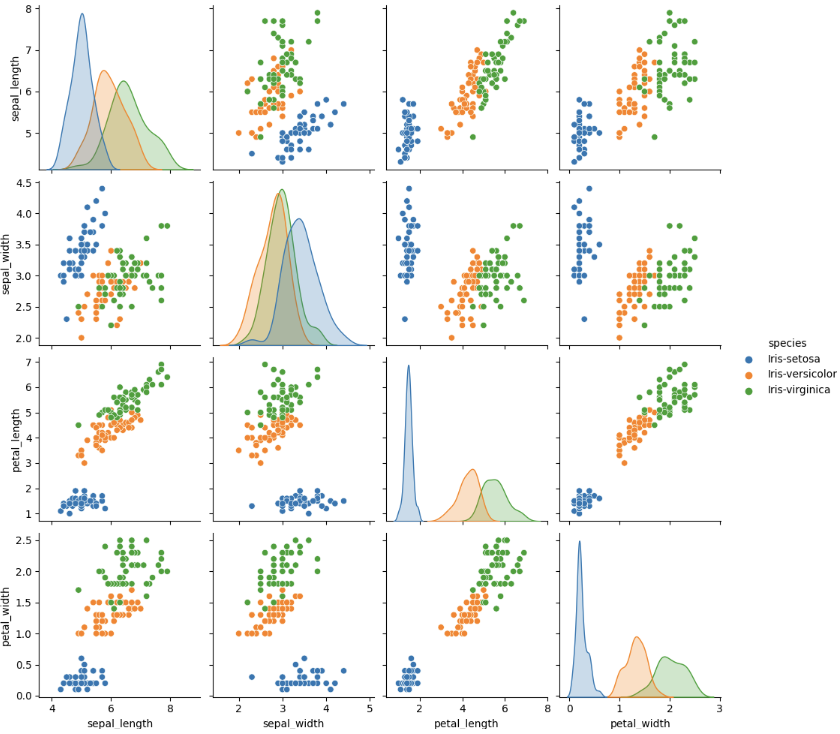
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('./data/iris3.csv')
X = df.iloc[:,0:4]
y = df.iloc[:,4]
#더미데이터(가변수) 만들기
y = pd.get_dummies(y)
model = Sequential()
#입력층은 relu를 사용함
model.add(Dense(12, input_dim=4, activation='relu'))
#중간 은닉층은 relu를 사용, 기울기 소실 방지
model.add(Dense(8, activation='relu'))
#출력층은 softmax로, 다중 분류를 위해 사용함
model.add(Dense(3, activation='softmax'))
model.summary()
#컴파일은 소실함수는 벡터 형태로 오는 데이터를 받아오기 위해 categorical_crossentropy를 사용
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X, y, epochs=30, batch_size=5)
#총 손실은 0.68, 정확도는 0.667 정도로 나옴
실습 2 : 발로란트 무기 분석 하기
발로란트에는 많은 무기들이 있고, 그 무기들마다의 특징이 있음.
무기들의 성능에 따라서 무기를 분류해보기
데이터는 https://dotesports.com/valorant/news/damage-stats-for-all-weapons-in-valorant 의 데이터를 임의로 가공하여 사용함. → 최종 데이터 = stat3 데이터
분류할 때
- SideArm = 0
- SMGs = 1
- Shotguns = 2
- Rifles = 3
- Snipers = 4
- Heavy = 5
로 정의, Dropoff 데이터 삭제, Head / body / Leg 데미지는 최대값으로 조정함.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
vf2 = pd.read_csv('/content/valorant_stats3.csv')
#데이터 중 쓰는 데이터는 데미지(머리,몸통,다리), 총 소지 시 이동 속도, 재장전 속도, 탄창
x2 = vf2.iloc[:, 4:10]
y2 = vf2.iloc[:,10]
y2 = pd.get_dummies(y2)
model = Sequential()
model.add(Dense(12, input_dim=6, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(6, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(x2, y2, epochs=500, batch_size=5)
#손실은 0.23, 정확도는 0.94 가 나옴
#위보다 정확도가 높은 이유는 epochs 를 그냥 무식하게 많이 줘서 그런듯
#그리고 손실이 늘어나는 것이 보이는 것으로 보아 과대적합이 일어나기 직전에 멈춘듯함
#그렇다면 적정 적합은 498번 학습인 것이다.

-ㅅ-)b