음향의 특성을 추출하는 방법
음향의 특성을 분석해주는 유용한 파이썬 라이브러리가 있다.

리브로사는 정말 다양한 음향 분석 메서드를 제공한다.
근데 분석 하기전에 사전 지식을 조금 알고가자. 간단하게 설명하고 넘어가겠다.
우리 귀에 들리는 소리는 세기 / 높낮이 / 음색이라는 3 요소를 가지고 있다.
이 세 가지 요소는 각각 소리라는 파동의 진폭, 진동수, 파형에 해당한다.
파동의 진폭이 클수록 큰 소리가 나고 파동의 주파수(진동수)가 높을수록 고음이 발생한다.
소리의 음색은 파동의 파형에 의해 결정된다.
우리는 이 3가지 특징을 추출해서 다양한 기법으로 소리를 표현하고 분석할 수 있다.
1. 스펙트럼(Spectrum)
소리 신호를 주파수와 진폭으로 분석한다.
고속 푸리에 변환을 적용하여 시간 영역의 신호를 주파수 영역으로 변환한다.
X 축은 주파수, Y 축은 진폭을 나타낸다.
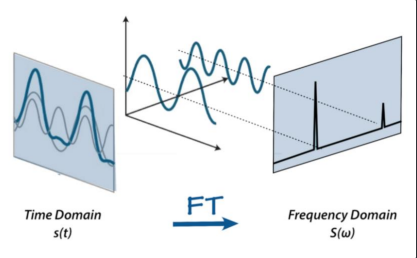
2. 멜 스펙트로그램(Mel Spectrogram)
주파수 특성이 시간에 따라 달라지는 오디오를 분석하기 위한 특징 추출 기법이다.
인간의 청각 영역을 반영한 mel scale 을 적용한다.
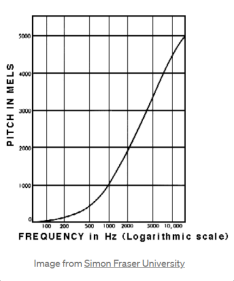
Mel scale?
- 사람은 소리의 주파수를 선형적으로 인식하지 못함
- 보통 저주파를 더 잘 인식함
- 이러한 인간의 특성을 나타낸 것이 mel scale
3. MFCC (Mel-Frequency Cepstral Coefficient)
MFCC를 추출하기 위해서는
- 스펙트로그램 생성
- 멜 스케일 적용, 멜 스펙트로그램 생성
- 캡스트럴 분석을 통해 MFCC 특성을 추출
- 캡스트럴 분석은 스펙트럼에서 배움 구조를 유추할 수 있도록 도와줌
- 배움 구조란 음향의 음색? 정도로 생각하면 된다.
- 멜 스텍트로그램에 절댓값과 로그를 취한 뒤 역 푸리에 변환을 수행하면 완료!
- 캡스트럴 분석은 스펙트럼에서 배움 구조를 유추할 수 있도록 도와줌

음 이정도의 사전 지식이면 우리도 음향의 특성을 얼마든지 추출할 수 있다.
리브로사로 추출해보자
특징 추출에 들어가기 앞서
혹시 본인의 컴퓨터에 주피터 환경과 Anaconda3 환경이 설정되어있지 않다면
Anaconda3 + tensorflow 키워드로 구글링해서 나오는 블로그들을 참고하기 바란다.
또한 우리는 뉴욕 대학교 MARL(Music and Audio Research Lab)에서 2014 년에 공개한 UrbanSound8K 사운드 데이터를 이용할 것이다.
다운로드 하기전에 사용 목적을 물어보는데 작성해주면 된다.
준비 끝! 본격적인 특징추출
이번에 사용할 라이브러리들이다.
keras 쓰면 짱 편함 ㅋㅅㅋ
import os
import glob
import librosa
import numpy as np
import pandas as pd
import pickle
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split아래의 코드는 딥러닝을 할 때 필요한 만큼 GPU의 메모리를 할당하도록 하는 코드이다.
본인 랩탑에 GPU가 있다면 사용하는걸 추천한다.
GPU를 사용하면 특징 추출 속도가 빨라지고 딥러닝 학습 속도 또한 빨라진다.
tensorflow gpu 사용 - Google Search
physical_devices = tf.config.list_physical_devices('GPU')
try:
tf.config.experimental.set_memory_growth(physical_devices[0], True)
except:
# Invalid device or cannot modify virtual devices once initialized.
pass아래의 코드는 특징을 추출하는 코드이다.
위에서 잠깐 살펴본 mfcc 를 추출하는 코드가 보이고
numpy를 이용해서 특징의 width를 조절해주는 코드가 보인다.
우리가 추출하는 코드는 (40, 174) 라는 데이터 shape을 가지고 있고
이 shape은 본인이 얼마든지 조절할 수 있다.
코드 그대로 2차원으로 추출해도 되고 shape을 조절해서 1차원으로 늘어뜨려도 된다.
max_pad_len = 174
def extract_feature(file_name):
print('file name :', file_name)
try:
audio, sample_rate = librosa.load(file_name, res_type='kaiser_fast')
mfccs = librosa.feature.mfcc(y=audio, sr=sample_rate, n_mfcc=40)
pad_width = max_pad_len - mfccs.shape[1]
mfccs = np.pad(mfccs, pad_width=((0,0), (0, pad_width)), mode='constant')
print(mfccs.shape)
except Exception as e:
print("Error encountered while parsing file: ", file_name)
print(e);
return None
# return padded_mfccs
return mfccs잘 추출되는지 확인해보자.
extract_feature('upload_sound/7383-3-0-0.wav')
# extract_feature('테스트할 음향 파일 위치')
우리가 의도한대로 (40, 174) shape이 나오는걸 볼 수 있다.
자 그럼 이제 전체 음향 파일을 대상으로 추출해보자.
UrbanSound8K 데이터 셋을 다운받았다면 코드가 문제없이 실행될 것이다.
파일 경로는 본인의 환경에 맞게 수정해야한다.
# Set the path to the full UrbanSound dataset
fulldatasetpath = 'UrbanSound8K/audio/'
metadata = pd.read_csv('UrbanSound8K/metadata/UrbanSound8K.csv')
features = []
# Iterate through each sound file and extract the features
for index, row in metadata.iterrows():
file_name = os.path.join(os.path.abspath(fulldatasetpath),
'fold'+str(row["fold"])+'/',str(row["slice_file_name"]))
class_label = row["classID"]
data = extract_feature(file_name)
features.append([data, class_label])
# Convert into a Panda dataframe
featuresdf = pd.DataFrame(features, columns=['feature','class_label'])최초 추출한 데이터는 data이고 class_label과 합쳐져서 features에 저장된다.
data는 우리가 리브로사로 추출한 mfccs라는 특성이고
class_label은 그 음향의 종류를 나타낸다.
UrbanSound8K 데이터 셋에 포함된 음향의 종류는 아래와 같다.

모든 특성을 추출했다면 featuresdf에 판다라는 형태로 데이터가 저장되었을 것이다.
우린 이걸 피클이라는 데이터 형태로 저장할 것이다.
혹시 모르니 저장하는 것이고 필수는 아님
# 피클로 데이터 저장
featuresdf.to_pickle("featuresdf.pkl")
# 피클 데이터 로드
featuresdf = pd.read_pickle("featuresdf.pkl")훈련(Train) 셋과 검증(Test) 셋 생성
from keras.utils import to_categorical
X = np.array(featuresdf.feature.tolist())
y = np.array(featuresdf.class_label.tolist())
le = LabelEncoder()
yy = to_categorical(le.fit_transform(y))불러온 featuresdf에서 feature는 X에 저장하였고 class_label은 y로 저장하였다.
헌데 y는 yy로 변환과정을 거쳐서 다시 저장되었다.
둘의 차이는 원-핫-인코딩의 여부이다.
원-핫-인코딩은
2라는 자연수를 [0. 0. 1. 0. 0. 0. 0. 0. 0. 0.] 이런식으로 변환해준다.
이렇게 변환해서 사용하는 이유는 우리가 작성할 딥러닝 모델이 멀티 클래스(10 가지) 분류를 하기 때문이다.
( 원핫 인코딩(One-Hot Encoding)은 사람이 매우 쉽게 이해할 수 있는 데이터를 컴퓨터에게 주입시키기 위한 가장 기본적인 방법이다. )
자 이제 X와 yy를 이용해서 훈련, 검증 셋을 만들자
x_train, x_test, y_train, y_test = train_test_split(X, yy, test_size=0.2, random_state = 42)훈련 셋과 검증 셋의 비율은 8:2 로 분류되었다.
(데이터 셋 검사)

마지막으로 훈련, 데이터 셋의 shape을 딥러닝 모델에 넣기 위한 모습으로 변환해 줄 것이다.
n_columns = 174
n_row = 40
n_channels = 1
n_classes = 10
# input shape 조정
# cpu를 사용해서 수행한다
with tf.device('/cpu:0'):
x_train = tf.reshape(x_train, [-1, n_row, n_columns, n_channels])
x_test = tf.reshape(x_test, [-1, n_row, n_columns, n_channels])딥러닝 모델 작성하기
우리는 CNN이라는 대표적인 딥러닝 모델을 사용할 것이다.
model = keras.Sequential()
model.add(layers.Conv2D(input_shape=(n_row, n_columns, n_channels), filters=16, kernel_size=2, activation='relu'))
model.add(layers.MaxPooling2D(pool_size=2))
model.add(layers.Dropout(0.2))
model.add(layers.Conv2D(kernel_size=2, filters=32, activation='relu'))
model.add(layers.MaxPooling2D(pool_size=2))
model.add(layers.Dropout(0.2))
model.add(layers.Conv2D(kernel_size=2, filters=64, activation='relu'))
model.add(layers.MaxPooling2D(pool_size=2))
model.add(layers.Dropout(0.2))
model.add(layers.Conv2D(kernel_size=2, filters=128, activation='relu'))
model.add(layers.MaxPooling2D(pool_size=2))
model.add(layers.Dropout(0.2))
model.add(layers.GlobalAveragePooling2D())
model.add(tf.keras.layers.Dense(units=10, activation='softmax'))
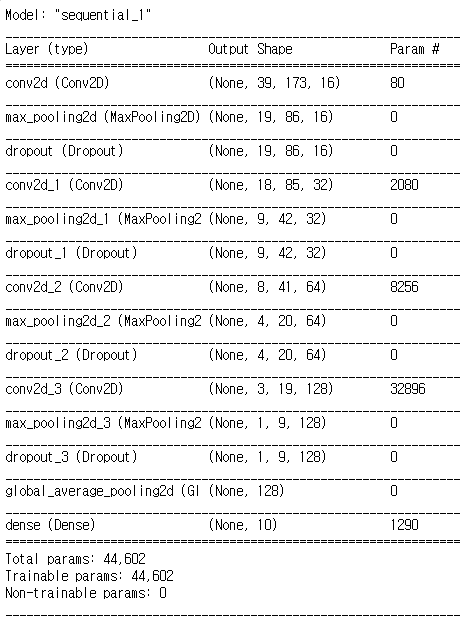
model.summary()model.summary()를 하면 이렇게 모델의 대략적인 모습을 볼 수 있다.
훈련시키기!
training_epochs = 72
num_batch_size = 128
learning_rate = 0.001
opt = keras.optimizers.Adam(learning_rate=learning_rate)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
history = model.fit(x_train, y_train, batch_size=num_batch_size, epochs=training_epochs)model.fit은 훈련을 시작시키고 반환값으로 훈련 history를 반환한다.
반환된 훈련 history를 참고하면 훈련의 문제점 또는 모델의 문제점을 파악하는데 도움이 된다.
훈련 진행상황 ...
훈련 history 그래프 보기
import matplotlib.pyplot as plt
def plot_history(history) :
key_value = list(set([i.split("val_")[-1] for i in list(history.history.keys())]))
plt.figure(figsize=(12, 4))
for idx , key in enumerate(key_value) :
plt.subplot(1, len(key_value), idx+1)
vis(history, key)
plt.tight_layout()
plt.show()
plot_history(history)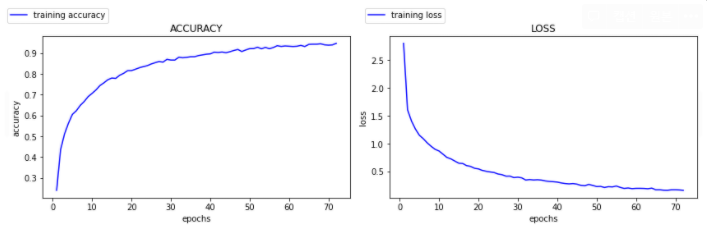
아주 이쁜 그래프가 나왔다!
보기 좋은 떡이 맛도 좋다고 그래프도 마찬가지임 ㅋ
모델 검증하기
print('\n# Evaluate on test data')
results = model.evaluate(x_test, y_test, batch_size=128)
print('test loss, test acc:', results)
검증 결과 정확도 90으로 나온다.
실제 환경에서 테스트해 본 결과 제대로 분류되지 않는 특정 소리가 있는 것 같다.
정확도를 높히려면 추출한 특징을 훈련시키기 전에 데이터 가공을 하는 것이 좋을 것 같다. (모델 훈련에 효과적인 데이터 셋의 형태를 만들어 주는 것이 중요한 것 같다)
모델 저장하기
model.save("sound_classifier_model")혹시나
# GPU 메모리 해제가 안될 때
from numba import cuda
device = cuda.get_current_device()
device.reset()
# 모델 삭제
del model텐서플로우의 고질적인 문제라는 것 같은데 메모리를 다 잡아먹고 release 하지 않는 이상한 문제가 있는 것 같다. 그래서 재 훈련을 하려고 하면 메모리 공간이 없어서 진행이 안될 수 있다. 그때는 메모리를 수동으로 해지하는 방법이 있다.

안녕하세요! 음성 파형 공부하고 있는 학생입니다.
좋은 글 작성해주셔서 감사합니다. 덕분에 음성 분류 작업에 잘 참고하였습니다.
질문이 하나 있어 댓글 남기게 되었습니다. 혹시 마지막에 정확도 확인하는 코드에서 vis가 어떤 것을 의미하는 것일까요?
좋은 정보 공유 감사합니다~!