앞서 데이터 사이언스에서 주로 사용되는 패키지중 Pandas를 소개한 적있다.
Pandas는 DataFrame을 제공해주는데 오늘은 데이터 프레임에 대해 알아보는 시간을 가질 것이다.
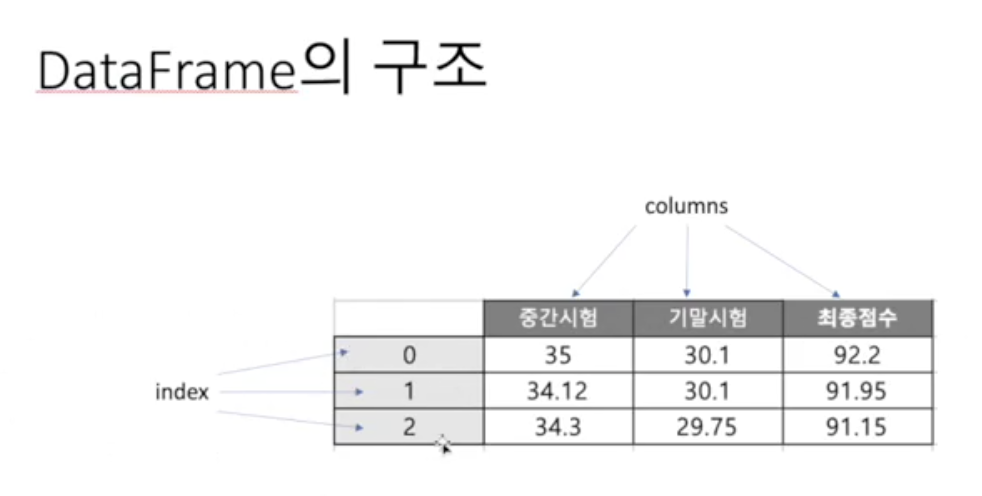
Pandas와 DataFrame
DataFrame은 Pandas가 제공하는 2차원 테이블형태의 자료구조로 Numpy의 ndarray 혹은 dict, list등과 데이터를 호환 및 변환 할 수있다.
또한 엑셀파일로 된 데이터 파일을 쉽게 읽어올수있다는 장점이있다
데이터 프레임으로 파일 읽어오기
import pandas
file_location = 'example.xlsx'
data_frame = pandas.read_excel(file_location)
print(data_frame)데이터 프레임 생성하기
import pandas
data = {"student number" : ["201512345", "201512346", "201512347"],
"score" : [30, 15, 50],
"grade" : ["B", "C", "A"]}
data_frame = pandas.DataFrame(data, columns = ["student number", "score", "grade"],
index = ["jake", "john", "kate"])데이터 프레임의 열을 선택하고 조작하기
-
하나의 열을 가져올때
1) 데이터프레임변수["컬럼명"]
2) 데이터프레임변수.컬럼명 -
두개 이상의 열을 가져올때
1) 데이터프레임변수[["컬럼1", "컬럼2"]] -
선택한 열의 값 조작하기
1) 선택 열의 모든 요소 초기화: 데이터프레임변수["컬럼명"] = 초기화시킬값
2) 선택 열의 개별 요소 초기화: 데이터프레임변수["컬럼명"] = [값1, 값2, 값3 ,,,]
데이터 프레임의 행을 선택하고 조작하기
-
하나의 행을 가져올때
1) 데이터프레임변수.loc["행 이름"]
2) 데이터프레임변수.iloc[행번호(인덱스)] -
두개 이상의 행을 가져올때
1) 데이터프레임변수.loc["행1": "행2"]
2) 데이터프레임변수.iloc[행번호1:행번호2]

삽질하는 개발자 지망생