☃️본 포스트는 2020-2학기 학교 수업이였던 데이터사이언스개론 내용을 토대로 작성되었습니다.
데이터 사이언스란?
데이터를 효과적으로 분석, 예측하는 방법을 다루는 학문이라고 정의할수있을것같다. 분석할 데이터의 양이 적어서, 혹은 컴퓨터의 성능이 낮아서 이전에는 불가능했던 것들이 이제는 분석 가능해졌고 그에 따라 더 효과적으로 분석할수있는 기법들이 연구되어 점점더 발전해나가고 있는 추세다.
성장하고있는 학문이고 적용 분야도 확장됨에 따라, 배움의 필요성이 증가될 학문이라고 생각한다.
아나콘다
아나콘다 링크
이번학기 데이터 사이언스는 파이썬으로 진행되었는데, 아나콘다라는 플랫폼(?)에서 주피터 노트북이나 스파이더같은 프로그램을 실행할 수 있었다.
파이썬 같은경우 파이썬의 버전에 따라 패키지가 호환되지 않는 경우가 존재하는데(ex.2020년 기준, 텐서플로우 패키지는 파이썬 3.8버전에 설치할수 없다) 아나콘다는 마치 도커의 컨테이너를 구성하는 것처럼, 사용할 패키지와 호환되는 파이썬 버전을 구성하고 그 속에 패키지를 다운받아 실행환경을 구성할수 있어서 편리했던것 같다!
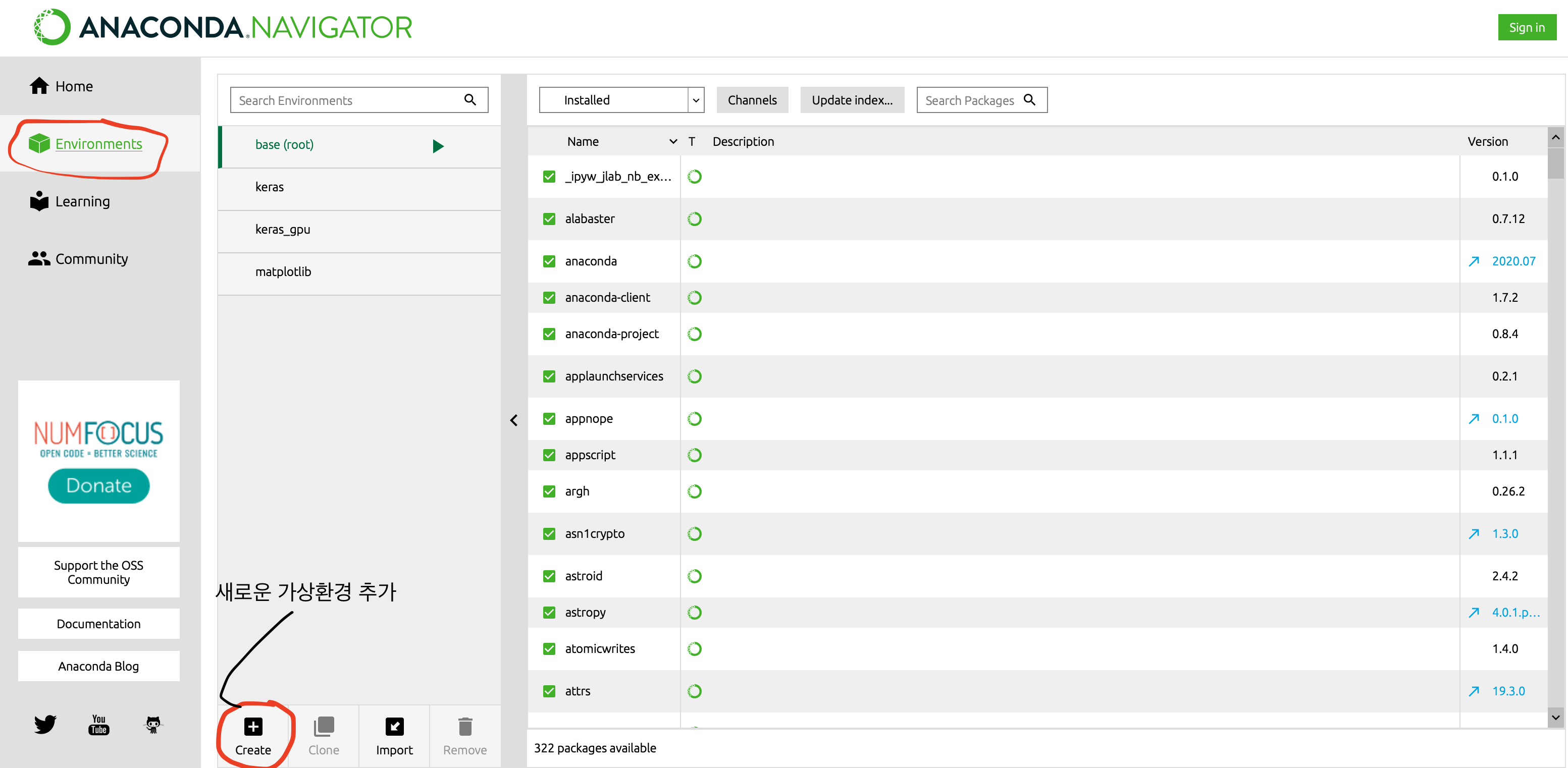
Create -> 이름이랑 파이썬 버전 선택 -> 자동으로 기본적인 패키지들 설치됨 -> 추가로 원하는 패키지는 우측 상단의 installed 드롭박스를 not installed 로 바꿔주고 Search Packages에 원하는 패키지 이름 쳐서 다운 받을수있다
주로 사용되는 패키지
pandas : "데이터 프레임"을 다룰수있게된다
numpy : "병렬 연산이 가능한 배열 자료형 ndarray"을 다룰 수 있게된다
scipy : 넘파이의 ndarray자료형을 이용한 효율적인 연산을 지원해준다
scikit-learn: 다양한 AI 알고리즘들을 사용할 수 있게된다
matplotlib : 데이터로 시각적인 그래프를 그릴수 있게 된다
tensorflow : 다양한 AI 모델들을 사용할수 있게된다
keras : tensorflow랑 마찬가지!
얘네를 같이 사용하려다보면 최신 버전의 파이썬으론 호환안되는 패키지가 존재할수있다(케라스가 그랬었는데). 파이썬 3.6.12에선 모두 잘 돌아갔으니 참고하자
Numpy
다차원 배열 ndarray 자료형을 지원하는 패키지이다
리스트와 달리 ndarray는 구성하는 자료형의 타입 형태가 같아야 한다.
넘파이 써보기
import numpy as np
a = np.arange(15)
b = a.reshape(3,5)
print(a)
print(b)
print(type(a))
print(type(b))
print(a.shape)
print(b.shape)
print(a.ndim)
print(b.ndim)
print(a.dtype.name)
print(b.dtype.name)
print(a.itemsize)
print(b.itemsize)
print(a.size)
print(b.size)ndarray 생성
import numpy as np
# 2차원 배열 생성
a = np.array([[1,2,3],[4,5,6]])
# 0으로 채운 3 by 4 배열
b = np.zeros((3,4))
# 1로 채운 2 by 3 by 4 배열
c = np.ones((2,3,4), dtype = np.int64)
# 2 by 3 빈 배열
d = np.empty((2,3))
# 10 ~ 100전까지 10을 오프셋으로 하는 일차원 배열 (10 20 30 ... 90)
e = np.arange(10,100,10)Numpy와 산술
데이터 사이언스에서 Numpy를 사용하는 이유는 연산의 속도에 있다.
넘파이의 ndarray를 사용하면 기존처럼 배열의 요소 하나하나 반복문으로 접근해서 연산하는것보다 월등히 빠른 연산이 가능해지는데 이를 "벡터화 연산"이라고 한다.
A = np.array( [20,30,40,50])
B = np.arange(4)
C = A - B
D = B ** 2 ⇒ 각각의 요소 제곱
print(A < 35)다음 코드로 연산 속도 차이를 경험해 보자
import time
a = range(10000000)
b = range(10000000)
c = []
start = time.time()
for i in range(10000000):
c.append(a[i]*b[i])
end = time.time()
print("elapsed time(리스트 사용) =", end - start)
import numpy as np
import time
# 넘파이를 사용했다
a = np.range(10000000)
b = np.range(10000000)
start = time.time()
c = a*b
end = time.time()
print("elapsed time =", end - start)대략 200배에서 2000배정도 차이가 난다
따라서, 행렬에 대한 연산이 필요하다면 numpy를 무조건 사용하는게 좋다!
리스트가 굉장히 편하니까 자주 사용되지만 최종적으로 연산을 하게 될때는 리스트의 데이터를 넘파이로 바꿔서 실제로 머신러닝을 하게 된다고 생각하자
matrix wise 연산
A = np.array([1,1], [0,1])
B = np.array([2,0], [3,4])
C = A * B // element wise 연산
⇒ [[2,0],[0,4]]
D = A @ B // matrix wise 연산
⇒ [[5, 4], [3,4]]
X = [1,2,3,4]
Y = [1,0,1,0]
F = np.inner(X,Y) // 내적 (각 요소 곱하고 합)
⇒ 4