[딥러닝/컴퓨터비전] 1장 - Getting Started
재미있는 비전 프로젝트를 진행하기에 앞서 "Deep Learning for Computer Vision" 책을 우선 공부하기로 했다.
컴퓨터 비전 관련 해서 자율 주행 차량 부터 시작해서 다양한 얼굴 인식 프로젝트들을 진행해보고 싶어서 어서 빨리 실습을 진행해보고 싶다ㅎㅎ
원서를 구매했는데 이를 3주 내로 공부하여 정리해둘 계획이다.
오늘은 첫날 - Chapter 1, Getting Started 부터 시작해본다.

Deep Learning for computer Vision
📃1단원의 목표
- 딥러닝 기본 어휘들 이해하기
- 딥러닝과 컴퓨터 비전을 결합해서 이용할 수 있을까?
- 환경 설정 마치기
- TensorBoard나 TenserFlow Serving에 대해서 탐구해보기
📕 Understanding deep learning
기본 용어 익히기! (얕음 주의)
Perceptron 퍼셉트론
퍼셉트론은 본래 인간의 뇌를 구성하는 신경 세포들을 본따서 만든 알고리즘이다.
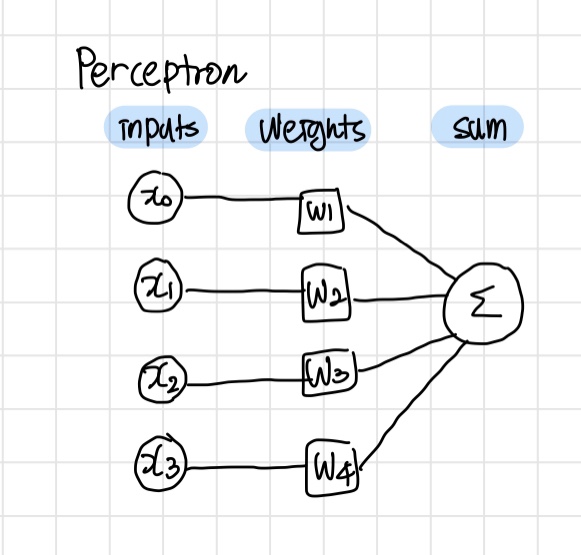
각각의 input에 weight 값을 곱하고, 이 값들을 더해준다.
딥러닝 학습에 있어서 적절한 weight 값을 구해 나가는 것을 training이라고 한다.
이 결과값은 activation function이 입력값으로 이용된다.
Activation Functions 활성함수
활성함수는 neural net을 비선형으로 만들어주는 역할을 한다.
비선형인 활성함수를 사용하는 이유?
딥러닝의 장점은 신경망의 개수가 많아지고, 깊이 있어 지는 데에서 정확도를 높인다. 그런데 선형인 함수를 이용하게 될 경우, 하나의 망으로 간단하게 구현할 수 있기 때문에 망을 깊게 만들 수가 없다.
활성함수는 train을 할 때, gradients를 수정하는 역할을 한다.
활성함수는 항상 연속적이고 미분 가능하다는 특징을 가진다.
-
Activation function의 예
1. Sigmoid
시그모이드 활성 함수는 다음과 같은 형태를 띈다. 계단 함수를 부드럽게 한 형태이다.
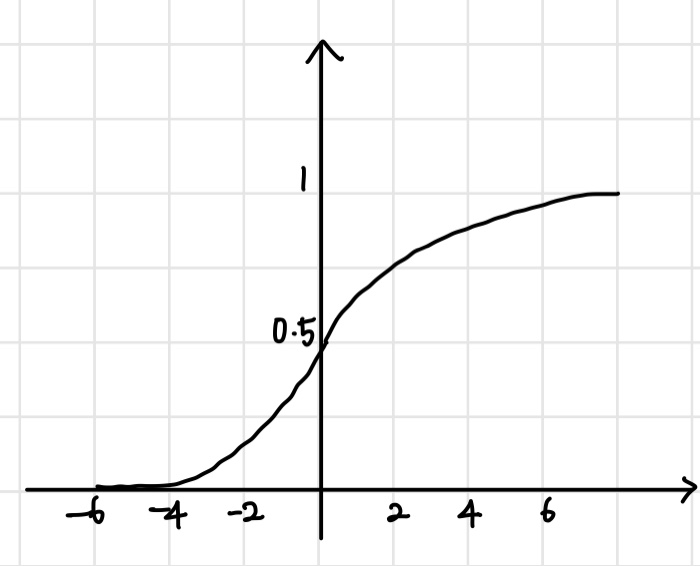
- 시그모이드 함수는 0과 1사이의 값을 가지기 때문에 확률로 나타내기에 좋다.
- binary classification(2진 분류)으로도 이용할 수 있다. 2가지 중 하나로 분류하는 것을 뜻한다. (ex. 스팸 메일 구분하기)
이는 시그모이드 함수가 0과 1사이이기 때문에, 결과값을 0과 1과 중 보다 가까운 값을 택하는 형태로 분류를 할 수 있기 때문인듯하다. - Vanishing gradient 란?
시그모이드 함수를 살펴보면 값이 커질 수록, 기울기의 변화량이 작아지는 것을 볼 수 있다. 0과 가까운 값이 되어 학습이 어려워지는 상황이 발생할 수 있는 것이다. 이러한 문제를 vanishing gradient라고 한다.
- The hyperbolic tangent function
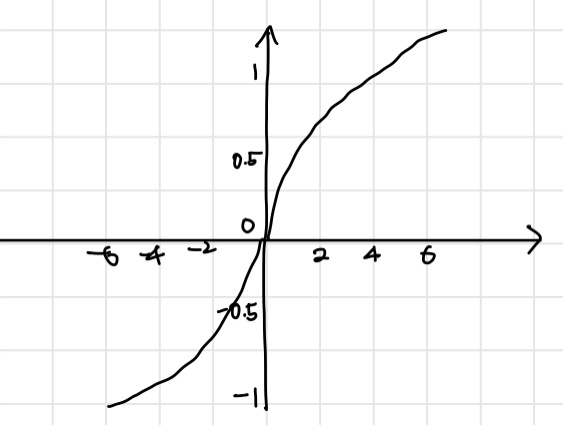
시그모이드 함수를 변환한 함수이다. 범위는 -1부터 1을 가진다.
- sigmoid함수보다 미분값이 더 안정적(변화량이 크다는 의미인듯하다)이기에 vanishing gradients 문제가 적게 나타난다.
- sigmoid와 hyperbolic tangent 함수 모드 fire 한다고 한다. 다음 소개할 ReLU는 fire하지 않는데 이로써 neural network의 크기를 줄일 수 있다는 장점을 가지게 할 수 있다고 한다.
- The Rectified Linear Unit (ReLU)
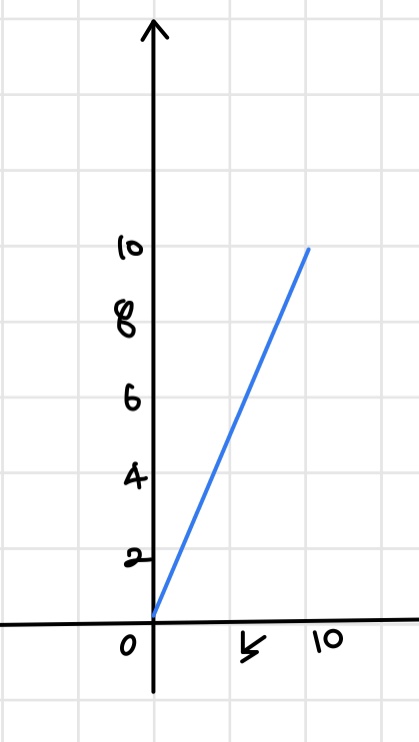 음수 값은 0, 음수가 아닌 값은 자기 자신 그대로의 값을 가진다. 큰 앞의 2 함수와 다르게 큰 값을 가질 수 있다.
음수 값은 0, 음수가 아닌 값은 자기 자신 그대로의 값을 가진다. 큰 앞의 2 함수와 다르게 큰 값을 가질 수 있다.
- fire 않기 때문에 더 빠르게 train이 가능해진다.
- 간단한 함수이기에 비용도 저렴한 편이다.
Artificial neural network(ANN)
ANN은 앞서 설명한 perceptron과 활성 함수의 모음이 ANN 인공 신경망이다. perceptron은 서로 연결되어 hidden layer을 구성한다.
input과 output을 매핑하는 망이라고도 할 수 있겠다.
매핑하는 방식은 weight된 입력값들과 bias의 합을 이용한다.
이러한 구조, weight, bias들을 일컬어 model 모델이라고 한다.
학습은 다음과 같은 과정을 거친다.
1. 모델 value 랜덤 초기화
2. loss function으로 에러 값 계산
3. 에러를 줄이는 방향으로 weight과 bias tune
4. 에러를 더 이상 줄일 수 없을 때까지 2,3 반복
ANN은 다음과 같은 형태로 구성되어 있다.
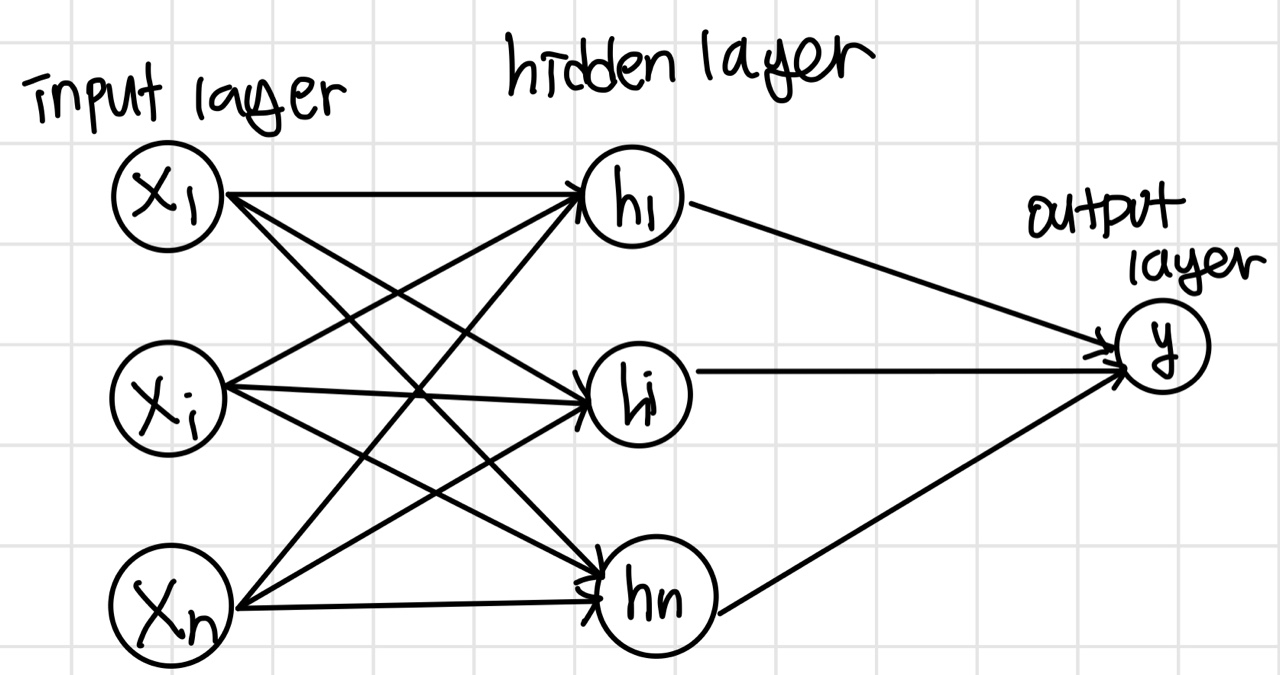
Universal Approximation theorem (시벤코 정리) 에 의하면 위와 같은 NN으로 어떠한 함수로도 근접 가능하다고 한다.
각각의 layer는 하나의 활성 함수를 가진다.
One-hot encoding
분류 문제를 다룰 때 타겟이 되는 클래스를 나타내는 방식이다.
목표 타겟을 1로 나타내고 나머지는 0으로 표시하는 것이다.
Softmax
NN의 결과값의 합을 1로 설정하는 것이다. 이렇게 한다면 확률 분포를 다루는 결과값을 가질 수 있다.
일종의 활성 함수이다.
Softmax와 one-hot encoding을 함께 쓴다면, 하나의 값 1을 제외하면 다른 class는 모두 0이 될 것이다.
Cross-entropy
Cross - entropy는 loss function(손실 함수) 로 One-hot Encoding과 softmax의 결과값을 비교한다.
우리가 보통 entropy 하면 불확실성에 대한 척도라고 한다.
이 entropy 값이 커지면, 불확실성이 커진 것이다.
cross - entropy의 경우 실제 값과 예측값의 차이를 줄이기 위해서 사용되는 것이다.
Overfitting을 줄이기 위한 방법
Overfitting이란 학습 데이터에 너무 딱 맞게 학습하여, 다른 데이터가 들어왔을 때 정확하게 예측하지 못하게 된 문제점을 일컫는 용어이다. 이를 해결하는 방법으로는 다음과 같은 것들이 있다.
-
Dropout
Dropout은 말 그대로 몇 개의 hidden layer을 stocastically(확률적으로) drop 하고 진행하는 것을 뜻한다. 이처럼 랜덤으로 선택하면 선택되는 layer마다 각기 다른 결과가 나올 것이다. 이는 다소 극단적인 방식이다! 따라서 상황에 맞게 이용하기 -
Batch Normalization
각각의 feature을 독립적으로 정규화하는 방식이다. layer의 결과값을 평균 0, 분산 1로 정규화 한다. -
L1 and L2 Normalization
Training neural networks
Artificial neural network에서 학습을 하기 위해서는 값들을 업데이트 해야한다. 이 과정을 backpropagation이라고 한다. 에러를 줄여나가는 것을 optimization이라고 한다.
Backpropagation
Backpropagation은 이름과 같이 NN의 뒤부터 앞으로 값을 업데이트 하는 방법을 의미한다.
Gradient descent (경사하강법)
많이 쓰이는 optimization 방법 중 하나이다.
Gradient값이 작은 방향으로 업데이트 해나가는 방식이다.
Stochastic gradient descent도 이의 한 종류이다.
Convolutional neural network
CNN은 이미지를 다루는데에 많이 이용된다.
일단, weight, bias, output이 있다는 점에서 ANN과 유사하다.
그런데 이미지를 다룰 때에 일반 NN을 이용할 수 없는 이유는 이미지의 크기 때문이다. 이미지는 가로, 세로, 높이와 RGB의 색상정보의 정보를 담고 있다. CNN은 volumn을 가진 체로 input값을 줄 수 있어, 이미지를 다룰 때 많이 이용된다.
이미지는 filter을 이용해서 패턴이나 특성을 분석할 수 있다.
Kernel
Convolution layer에서 이미지를 convolve 할 때에 이용되는 값이다.
size는 커널의 크기이다. 2x2 와 같은 형태이다. stride는 보폭이라는 뜻으로, 얼마만큼의 보폭으로 kernel을 이동해나갈 것인지를 결정하게 된다.
Max pooling
CNN에는 convolution layer 뿐만 아니라 pooling layer라는 것도 있다. 이 layer에서는 이미지의 크기를 샘플링을 통해서 줄이는 단계이다. 설정한 구간 내에서 "max" 값을 구간의 대표값으로 지정하는 것이다. max 뿐만아니라 Average pooling도 있다. 평균값으로 이미지의 크기를 줄이는 것이다.
pooling은 overfitting을 해결할 수 있는 방법으로 볼 수 있다. 주어진 데이터 값만으로 overfit하지 않도록 값을 조정하기 때문인듯하다.
Recurrent neural networks (RNN , 순환 신경망)
RNN은 sequential(순차적으로 일어나는) 정보에 대한 모델을 처리한다.
Recurrent는 순환한다는 의미인데, 각 노드가 방향을 가지며, 순환하는 구조를 가졌다는 특징을 가진다. 아래 그림은 RNN 신경망 모델 구조의 예이다.
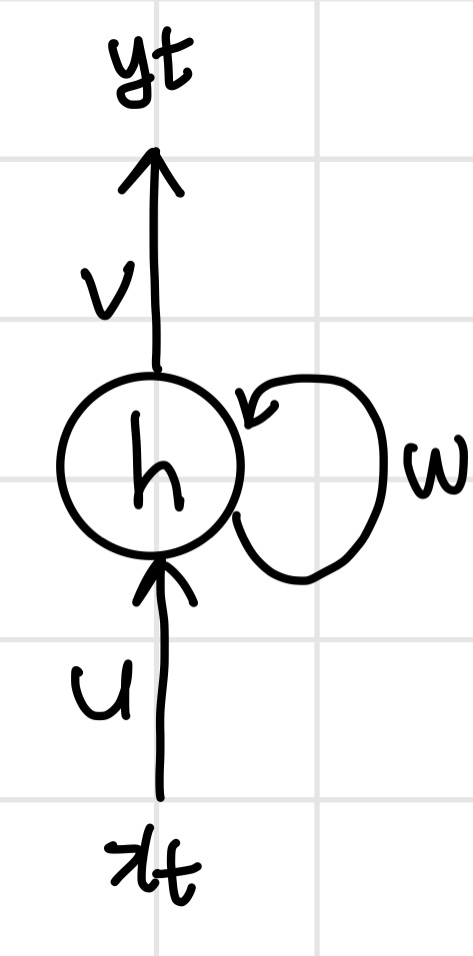
위가 하나의 step이다. input은 x , output은 y이며, 각 단계 마다 weight가 있다.
하나의 단계를 전체로 연결하면 아래와 같다.
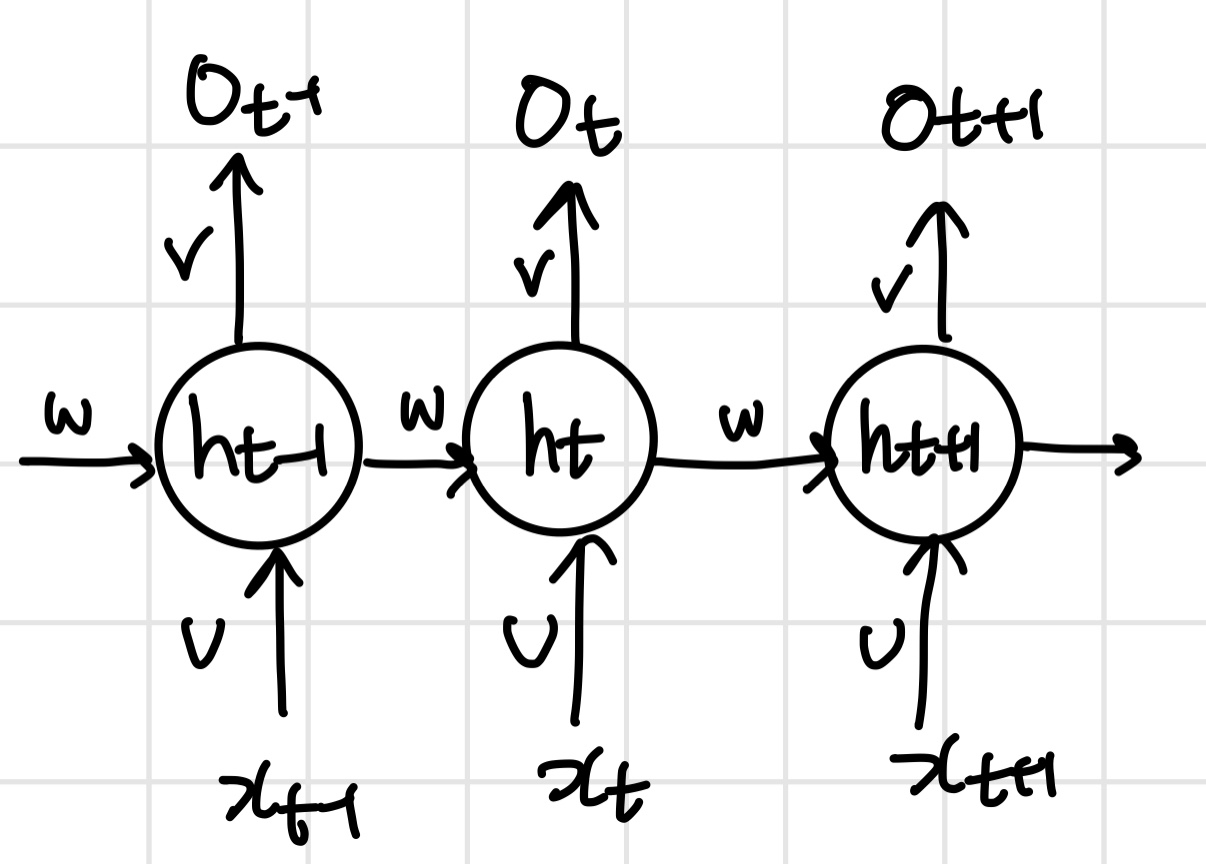
이전의 학습값의 output을 다음 학습의 input값으로 한다. 그런데 장기간의 정보에 대한 값을 기억하지는 못하며, 기억하기를 원하는 경우는 LSTM이라는 방법을 이용하기도 한다.
📕 Deep Learning for computer vision
컴퓨터 비전에 딥러닝을 적용하여 어떠한 분야들을 볼 수 있을까?
-
Classification
이미지를 라벨링 하는 작업이다. -
Detection or localization and Segmentation
Detection/localization은 bounding box를 이용하여 detect/localize 작업을 하는 것을 의미한다.
Segmentation은 "pixel-wise"로 classification을 진행한다. 이는 명확하게 특정 물체를 이미지와 분리해내기 때문에 의료 분야나 인공위성과 관련하여 많이 사용된다. -
Similarity Learning
이미지가 서로 유사한 것인지 학습하는 것을 similarity learning이라고 한다. 예를 들면, 사진에서 사람의 표정이 웃고 있는 경우, 표정의 유사성을 판별해볼 수 있을 것이다. -
Image captioning
이미지를 단순히 무엇인지 라벨링 하는 것에 그치지 않고, 이미지가 어떠한 상황인지 설명하는 것을 의미힌다. 이는 설명을 위한 언어도 자동화 해야하기 때문에 보다 복잡한 작업을 요한다. -
Generative models
generate는 생성한다는 의미를 가지고 있다. 생성하고자 하는 타입의 이미지를 먼저 학습하고, 이를 생성하는 것이다. -
Video analysis
비디오 관련하여 위 작업들을 진행하는 분야이다. 쏟아져 나오는 수 많은 영상들을 생각해보면 상당히 유용한 분야일 듯하다.
